
Ретробенчмаркинг — GeForce 8800 GTX (G80)
Direct3D 10

Одним из столпов современного подхода к рендерингу 3D-графики в реальном времени является так называемая унифицированная шейдерная модель, суть которой заключается в использовании общего набора инструкций для различных типов шейдеров. Изначально вершинные шейдеры имели намного более богатый набор команд по сравнению с пиксельными, но со временем различия сокращались, а закончилось всё почти полной унификацией. Если говорить конкретно о популярном графическом API Direct3D, являющемся частью DirectX, то первой версией, в основу которой была положена унифицированная шейдерная модель, стала 10 версия этого API, увидевшая свет в конце 2006 года одновременно с выходом Windows Vista. Революционность DirectX 10 в плане вышеупомянутой унификации (и не только) возможно не сильно отпечаталась в памяти многих лишь по причине откровенного провала Windows Vista, для которой новый API был эксклюзивом. Из-за низкой популярности новой версии Windows ещё долгое время большинство игровых проектов ориентировались по-прежнему преимущественно на DirectX 9 и лишь немногие опционально дополнялись некоторыми возможностями DirectX 10.
 https://xkcd.ru/528/
https://xkcd.ru/528/
Однако, несмотря на свою невысокую популярность среди разработчиков игровых проектов и непродолжительное (особенно на фоне предшественника в лице Direct3D 9 и приемника в лице Direct3D 11) время жизни, Direct3D 10 был важной вехой как в развитии конкретного графического API Direct3D, так и индустрии 3D-графики в целом. Даже небольшой список самых важных нововведений Direct3D 10 впечатляет:
- Уже упомянутая унификация различных типов шейдеров, делавшая программирование 3D-графики значительно богаче, а также позволявшая избавиться от различных проблем фиксированных функций (например, проблемы неравномерной нагрузки на различные типы шейдерных блоков).
- Новый тип шейдеров, геометрический шейдер, позволявший аппаратно генерировать сложную геометрию, а также многочисленные улучшения всех типов шейдеров — в Shader Model 4 были добавлены целочисленные инструкции и битовые операции и убрано ограничение на количество инструкций.
- Виртуализация видеопамяти — теперь при нехватке видеопамяти, приложение не завершалось аварийно, а вместо этого часть данных из видеопамяти переносилась в системную память, подобно тому как при нехватке системной памяти часть данных переносится из неё в память виртуальную.
- Новая модель драйвера, WDDM (Windows Display Driver Model), в которой большая часть тяжёлой работы по сбору буфера команд выполнялась в пользовательском режиме, а в режиме ядра осуществлялась лишь пересылка собранного буфера на видеокарту. Такой подход существенно увеличил стабильность системы в целом, ведь при падении пользовательской части драйвера, прекращало работу лишь конкретное приложение, но не происходил всеми любимый BSOD.
- Детализированная и обязательная к исполнению спецификация API. Убраны списки возможностей (capability bits), так что теперь если производителем ускорителя заявлена поддержка DirectX 10, то гарантируется наличие всей функциональности, заявленной в спецификации (SM 4 в полном объёме, всех форматов текстур, всех режимов фильтрации и т.д). Более того, для Direct3D 10 написали спецификацию правил растеризации и эталонный программный растеризатор, так что теперь, если на каком-то коде картинка, полученная на конкретной видеокарте, не совпадала с эталонным результатом, это однозначно считалось ошибкой данной видеокарты.
- Снижение накладных расходов на использование API за счёт уменьшения количества вызовов на отрисовку и переключений состояний.
- Потоковый ввод/вывод, позволявший записывать результат работы вершинных и геометрических шейдеров в буферы без необходимости отрисовки.
Подход к рендерингу в Direct3D 10 получился максимально унифицированным и гибким, вот только на руку это было прежде всего разработчикам игр, а не архитекторам программных и аппаратных решений, которые должны были всю эту гибкость и унификацию обеспечить, притом обеспечить эффективно. Разработчик игры лишь формулировал задачу в терминах набора шейдеров различного назначения, которые необходимо было исполнить над определённым набором данных, а библиотеки времени исполнения Direct3D в тандеме с драйвером видеокарты должны были скомпилировать шейдерный код в инструкции, понятные графическому процессору, попутно их оптимизируя, а также постараться наилучшим образом распределить имеющиеся в составе видеоускорителя аппаратные ресурсы (шейдерные блоки, кэши и т.д.) для выполнения полученных инструкций. Так что удивляться очередному существенному усложнению драйверов видеокарт для поддержки Direct3D 10 не приходилось. Кстати, именно очередное усложнение и без того нетривиальных драйверов якобы и заставило Microsoft реализовать в Windows Vista совершенно новую модель драйвера WDDM, упомянутую выше. С одной стороны — меньше BSOD'ов, но с другой — перенос новой драйверной модели на предыдущую версию Windows оказался (по заверениям Microsoft) невозможен, так как требовал слишком много изменений в ядре Windows XP.
реклама
Сложно сказать, насколько в действительности было технически сложно перенести WDDM-модель в Windows XP, и была ли в новой драйверной модели столь острая именно техническая необходимость, но факт остаётся фактом — Direct3D 10 требовал новую модель драйверов, которая была реализована лишь в Windows Vista. И вот в свете выше обозначенной непопулярности Direct3D 10 среди разработчиков игр, связанного с отказом от поддержки этой версии API в Windows XP, может создаться впечатление, что все труды инженеров-разработчиков Direct3D 10 и видеокарт его поддерживающих пошли насмарку, ведь Direct3D 10 так толком и не "взлетел". И это правда, но лишь отчасти. Да, Direct3D 10 не оставил глубокий след в истории игровой индустрии, ведь игры на нём выходили преимущественно в течение всего трёх лет (с 2007 по 2009 годы), да и в большей части из них, как мы уже говорили выше, основным графическим API был Direct3D 9. Но Direct3D 10 подтвердил правильность выбранного курса на унификацию и заложил основы для дальнейшего эволюционного развития 3D-рендеринга в реальном времени, которое мы и по сей день наблюдаем.
Революционность Direct3D 10 сыграла с ним злую шутку — потребовалось менять слишком много всего, чуть ли не впервые в истории этого API полностью отказавшись от обратной совместимости во всех её видах. Но зато двигаться дальше стало значительно легче. Так, следующая 11-ая версия Direct3D представляла собой уже не столь радикальное обновление, привнесшее из принципиально нового, пожалуй, лишь аппаратную тесселяцию и поддержку ещё одного типа шейдеров (вычислительных). Конечно, в Direct3D 11 была обновлена шейдерная модель, улучшена поддержка многоядерных центральных процессоров и много ещё чего было добавлено и обновлено, но ничего из этого не потребовало кардинальных изменений в архитектуре программных и аппаратных решений, которые заставили бы вновь отказаться от какой-либо обратной совместимости. Direct3D 11 не требовал принципиально новую модель драйвера видеокарты (или чего-то другого принципиально нового от ОС), а потому прекрасно себя чувствовал как на новенькой Windows 7, так и на уже видавшей виды Windows Vista. Более того, Direct3D 11 приложения можно запускать на Direct3D 10 (и даже Direct3D 9) ускорителях, используя концепцию уровней поддержки (feature levels).
Уровни поддержки в API Direct3D определяют чётко заданные наборы возможностей графических ускорителей. В отличие от списков возможностей, использовавшихся до Direct3D 10, графическому приложению более нет нужды отдельно проверять, поддерживает ли графический ускоритель всякую единичную возможность, которую разработчик приложения хотел бы использовать. Теперь большая часть возможностей ускорителей разных поколений собраны воедино в различные уровни поддержки. Так, уровни поддержки 9_1, 9_2 и 9_3 в Direct3D 11 охватывают возможности различных популярных ускорителей эпохи Direct3D 9, а уровни поддержки 10_0 и 10_1 охватывают возможности ускорителей с аппаратной поддержкой Direct3D 10 и 10.1. Да, между Direct3D 10 и 11 был ещё Direct3D 10.1, и, вообще говоря, концепция уровней поддержки появилась именно в Direct3D 10.1, но эта версия API была совсем уж короткоживущей, так что не суть. Важно, как уже было сказано, то, что теперь можно было за один вызов узнать, поддерживается ли определённый набор возможностей видеокартой или нет, что упрощало написание графических приложений. Более того, уровни поддержки являются строгими подмножествами друг друга, так что каждый более высокий уровень гарантированно содержит в себе все возможности всякого более низкого уровня, что ещё больше упрощает жизнь.
Именно благодаря концепции уровней поддержки Direct3D 10 (и 10.1) ускорители оставались актуальными ещё долгое время после выхода Direct3D 11 — первые годы после выхода Windows 7 и DirectX 11 у владельцев ПК "на руках" было ещё слишком большое число видеокарт с поддержкой только Direct3D 10, так что во многих играх разработчики с помощью одного API Direct3D 11 поддерживали ускорители с разными уровнями поддержки, обычно 10_0 и 11_0. Конечно, не все игры, написанные "под" DirectX 11, поддерживали "старые" Direct3D 10 карты в таком "режиме обратной совместимости", не все технологии можно было использовать на "старых" картах, да и не каждая Direct3D 10 карты могла обеспечить необходимый новым играм уровень производительности, но в целом играть со "старой" Direct3D 10 картой в новые Direct3D 11 игры с разной степенью успешности можно было года эдак до 2015. Вот давайте и посмотрим, что смогут Direct3D 10 карты не только в DirectX 10, но и в DirectX 11 играх прошлых лет, проверив их потенциал максимально возможным образом. Ведь очень часто в обзорах новинок (и первые Direct3D 10 карты тому не исключение) можно встретить рассуждения об имеющемся у нового "железа" потенциала, который, возможно, будет позже раскрыт. Вот только в будущем про "старичков" забывают, так как на фоне постоянных анонсов всё нового "железа" уже особо не до них, они мало кому интересны, и тема раскрытия потенциала остаётся, прошу прощения за тавтологию, нераскрытой.
Архитектура
реклама
Мы уже упоминали о том, что эффективная реализация множества новшеств Direct3D 10 потребовала серьёзных усилий со стороны разработчиков программного обеспечения — библиотек времени исполнения, драйверов, игровых "движков" и, собственно, игр. Эффективной, конечно, должна была быть и аппаратная реализация всего Direct3D 10 "добра", так что и разработчикам графических ускорителей пришлось изрядно "попотеть". И сегодня мы мельком взглянем на результаты труда команды инженеров NVIDIA, рассмотрев некоторые важные аспекты архитектуры первого чипа этой компании с поддержкой Direct3D 10 — G80. Подробные всеобъемлющие обзоры прошлых лет можно почитать по ссылкам в конце статьи, а ниже остановимся лишь на том, что кажется наиболее важным и интересным по прошествии времени.
Унифицированная шейдерная архитектура
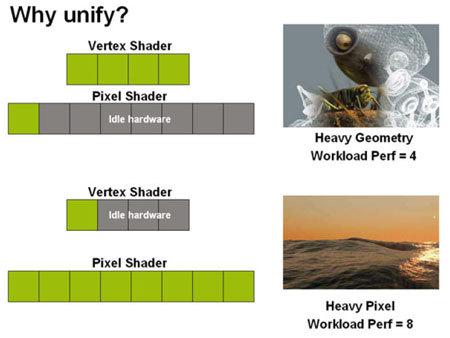
Итак, в унифицированной шейдерной модели для всех типов шейдеров имеется практически идентичный набор инструкций, поэтому очевидным образом напрашивается решение по организации ускорителя с поддержкой этой модели в виде массива вычислительных блоков, каждый из которых способен выполнять любой тип шейдерной программы. Такую архитектуру обычно называют унифицированной шейдерной архитектурой, и давайте сразу отметим, что для поддержки унифицированной шейдерной модели графический ускоритель, вообще говоря, совершенно не обязан иметь унифицированную шейдерную архитектуру. Никто не запрещает ускорителю по-прежнему иметь в своём составе выделенные блоки под различные типы шейдеров, разве что смысла в этом исчезающе мало, так как архитектурно блоки эти будут практически идентичны друг другу (из-за необходимости выполнения практически одинаковых наборов инструкций), но использовать их при этом можно будет только под те типы шейдеров, под которые они изначально выделены. Такое устройство ускорителя, естественно, было бы крайне неэффективным.
Возможна и обратная ситуация — ещё до внедрения в Direct3D унифицированной шейдерной модели ничто в принципе не запрещало построить графический процессор на унифицированной шейдерной архитектуре, используя вместо специализированных вершинных и пиксельных процессоров унифицированные устройства, способные исполнять инструкции и вершинных, и пиксельных шейдеров. Причём в отличие от первой, чисто гипотетической ситуации, процессор на унифицированной шейдерной архитектуре, разработанный под ещё неунифицированную шейдерную модель — это не какой-то теоретический конструкт. Такой чип реально существовал и, более того, был выпущен огромным числом экземпляров. Речь, конечно же, как многие уже могли догадаться, идёт о графическом процессоре Xenos, использовавшемся в игровой консоли Microsoft Xbox 360. В состав чипа, разработанного компанией ATI Technologies, входило 48 универсальных шейдерных процессора, каждый из которых был способен выполнять код как вершинных, так и пиксельных шейдеров. При этом имелась поддержка только "неунифицированного" API DirectX 9.0c, или, точнее, его специального надмножества. При этом в отличие от гипотетической ситуации поддержки унифицированной шейдерной модели посредством неунифицированной шейдерной архитектуры, обратный вариант как раз хорош в плане эффективного использования ресурсов. И вот почему.
Хорошо известно, что графическим ускорителям обычно приходится обрабатывать значительно большее число пикселей, чем вершин, и, как следствие, пиксельных процессоров в неунифицированных архитектурах обычно примерно в 2-3 раза больше, чем процессоров вершинных. Однако, в каждый конкретный момент времени нагрузка на указанные блоки может сильно разниться. Например, при отображении на экране простой геометрии (малое количество больших треугольников), вершинные процессоры по сути вообще простаивают, а пиксельные забиты работой "по самое не могу", а при сложной геометрии в кадре (большое количество малых треугольников) имеет место уже обратная ситуация.
реклама
Унификация вычислительных блоков позволяет динамически распределять нагрузку между ними — на сценах со сложной геометрии можно выделить большее число блоков под выполнение вершинных шейдеров, а на сценах с простой геометрией и сложными пиксельными эффектами, наоборот, будет выгодным выделить большее число блоков под выполнение шейдеров пиксельных.

Кроме того, унификация позволяет легко добавлять новые стадии в графический конвейер, такие, например, как геометрический шейдер — нет никакой необходимости заранее рассчитывать некоторое среднее соотношение "новых" и "старых" операций для определения, каким фиксированным числом блоков выполнения "новых" операций снабдить ускоритель. Собственно, в первую очередь именно из-за возможности динамического распределения нагрузки и простоты поддержки новых типов шейдеров все ускорители с поддержкой унифицированной шейдерной модели имели унифицированную же шейдерную архитектуру.
Потоковые процессоры (SP) и мультипроцессоры (SM)
При рассмотрении архитектуры графических процессоров необходимо в первую очередь понимать, что многие привычные термины, используемые при описании архитектуры центральных процессоров, обретают здесь несколько иной смысл. Так, под потоком здесь и далее понимается вершина, пиксель или геометрический примитив (полигон), над которым необходимо выполнить соответствующую шейдерную программу, состоящую из некоторой последовательности инструкций. В чипе G80, основанном на микроархитектуре Tesla, простейшей единицей выполнения инструкций над потоком является потоковый процессор (Streaming Processor, SP), представляющий собой по сути скалярное устройство для вычислений над числами с плавающей точкой одинарной точности (FP32). Это единственное скалярное АЛУ способно посредством совмещённого умножения-сложения (MAD) выполнять сразу две операции за такт — одно сложение (ADD) и одно умножение (MUL). Кроме того, в целях реализации требований API Direct3D 10 указанное АЛУ способно также выполнять операции и над целыми числами.
Каждый потоковый процессор работает с собственным потоком, будь то вершина, примитив или пиксель, так что в сумме 128 потоковых процессоров чипа G80 могут работать одновременно со 128 потоками. Однако, необходимо понимать, что потоковые процессоры не являются независимыми вычислительными устройствами подобными ядрам центрального процессора, так как у них не хватает для этого некоторых необходимых функциональных узлов. Как минимум, потоковым процессорам недостаёт устройства выборки инструкций, так что терминологию NVIDIA, которая предпочла назвать обсуждаемые АЛУ потоковыми процессорами (а чуть позже CUDA-ядрами) здесь стоит признать неудачной. Куда больше на роль ядра в микроархитектуре Tesla годится блок, представляющий следующую ступень организации чипа G80 — потоковый мультипроцессор (Streaming Multiprocessor, SM).
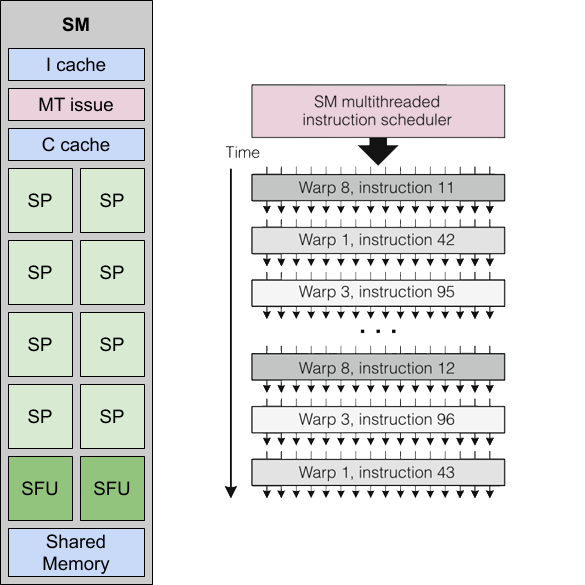
Потоковый мультипроцессор группирует 8 потоковых процессоров, 2 более сложных устройства для вычисления значений трансцендентных функций (cosx, sinx, ex) и интерполяции пиксельных атрибутов (Special-Function Unit, SFU), устройство выборки и отправки на выполнения инструкций (MT Issue), немного кэша инструкций и констант (I/C cache), а также небольшой блок общей памяти (Shared Memory). Каждое устройство SFU способно интерполировать 1 пиксельный атрибут или вычислять значения специальной функции за 1 такт.
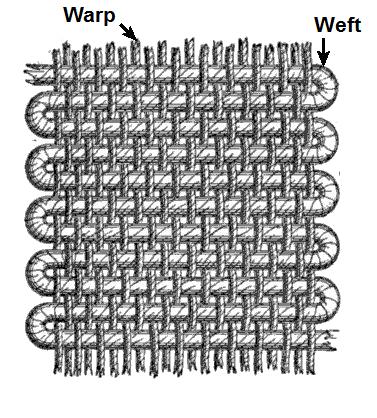
Итак, именно потоковые мультипроцессоры, а не одиночные потоковые процессоры являются независимыми устройствами выполнения инструкций. Инструкции выполняется над группами из 32 потоков, которые называются варпами (warp). Термин warp позаимствован из ткацкого дела, вот только его дословный перевод на русский язык — основа — слишком многозначен, так что для этого термина, пожалуй, будем-таки использовать кальку с английского. В ткачестве, основа (warp) — это продольная неподвижная система параллельных друг другу нитей, между которыми укладываются нити другой, поперечной системы параллельных друг другу нитей, называемой утком (weft).
реклама
Аналогия получается вполне наглядная — через варп, состоящий из 32 нитей-потоков "прокидывается" нить-программа, по одной инструкции за проход "от кромки до кромки". Точнее, каждый варп выполняется на мультипроцессоре в виде 2 групп по 16 потоков (полуварпы, half-warps), при этом простые инструкции (MAD) для каждой группы из 16 потоков могут быть выполнены на 8 потоковых процессорах за 2 такта, так что суммарно на выполнение одной такой инструкции для всего варпа тратится 4 такта. На выполнении одной более сложной инструкции, требующей использования SFU, тратится уже 16 тактов для всего варпа, так как 2 SFU способны выполнить лишь 2 специальных операции за такт.
Планировщик потокового мультипроцессора работает на вдвое меньше относительно вычислительных устройств SP и SFU частоте, при этом выполнения инструкций на SP- и SFU-устройствах планируется на чередующихся тактах — если выполнение инструкций на SP-устройствах было запланировано на текущем такте планировщика, то на следующем его такте будет запланировано выполнение инструкций на SFU-устройствах, если таковые инструкции имеются. И вот тут возникает первая проблема с эффективностью использования вычислительных блоков потокового мультипроцессора в микроархитектуре Tesla — при выполнении инструкций на устройствах SFU, устройства SP оказываются недоступны до тех пор, пока SFU не закончат свою работу. В таком случае при выполнении инструкций, которые требуют использования устройств SFU, большая часть потокового мультипроцессора простаивает. Есть и ещё одна интересная деталь: каждое устройство SFU вместо выполнения сложных специальных операций, по 1 за каждый такт, способно также выполнять и простые операции умножения MUL, сразу по 4 за каждый такт.
Тогда в случае, если требуется выполнять лишь инструкции MAD и MUL появляется интересная возможность выполнять 32 инструкции MAD за 4 такта на SP-устройствах и ещё 32 инструкции MUL на SFU-устройствах в рамках одного и того потокового мультипроцессора, используя вышеупомянутые особенности планировщика (поочерёдное планирование выполнения инструкций на SP- и SFU-устройствах и работу на вдвое более низкой частоте).
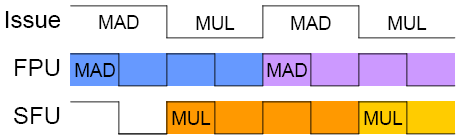
Вот именно такой режим работы потокового мультипроцессора NVIDIA в своих материалах и называла "dual issue MAD+MUL", хотя никакого второго исполнительного устройства в состав потоковых процессоров SP не входило, а MUL, как рассказано выше, выполнялся на устройствах SFU.

При таком раскладе получаем, что один потоковый мультипроцессор SM может выполнять за такт 8 инструкций ADD + 8 инструкций MUL за счёт наличия 8 потоковых процессоров SP да плюсом ещё 8 инструкций MUL на двух имеющихся SFU. А учитывая факт наличия 16 потоковых мультипроцессоров SM в полноценном чипе G80 (8800 GTX), его пиковая производительность должна была составить 16×(8+8+8)×1.35 = 518.4 GFLOPS! Мощно, конечно, но к реальности имеет очень отдалённое отношение.
И дело даже не в том, что показатели пиковой производительности выше рассчитаны из предположения выполнения идеального (с точки зрения имеющихся вычислительных блоков) кода — пиковую производительность так всегда и считают, G80 в этом отношении не уникален. Проблема в другом — из-за не самой эффективной реализации планировщика потокового мультипроцессора одновременное выполнение MAD на потоковых процессорах SP и MUL на устройствах SFU по описанной ранее схеме в G80 было практически невозможным. Даже в случае, когда устройства SFU не были заняты своими прямыми обязанностями и могли бы выполнять инструкции MUL, для реализации вышеописанной схемы "dual issue MAD+MUL" планировщик должен был уметь для одного и того же варпа на первом такте запланировать выполнение операций MAD на потоковых процессорах SP, а на следующем такте запланировать выполнение операций MUL на устройствах SFU. И как позже признает NVIDIA, с таким сценарием планирования в G80 были большие проблемы, которые будут исправлены лишь во втором поколении микроархитектуры Tesla (чип GT200). Ну а для поколения первого при расчёте пиковой производительности факт способности устройств SFU выполнять операции умножения следует всё-таки игнорировать, что приводит нас к величине 16×(8+8)×1.35 = 345.6 GFLOPS, которая обычно и указывается на многочисленных ресурсах.
Tекстурно-процессорные кластеры
Если рассматривать различные уровни организации вычислительных и управляющих блоков в чипе G80 с точки зрения максимальной близости к понятию ядра (в том смысле, в котором этот термин используется в отношении центральных процессоров), то и потоковым мультипроцессорам, строго говоря, кое-чего до почётного звания ядер недостаёт. А именно, им не хватает устройств для загрузки данных (в первую очередь текстур) из памяти и выгрузки данных обратно в память. Блоками, выполняющими указанные функции оснащается лишь следующая ступень организации чипа G80 — текстурно-процессорный кластер (Texture/Processor Сluster, TPC). Каждый такой кластер объединяет в себе 2 потоковых мультипроцессора, текстурный модуль и необходимую управляющую логику.
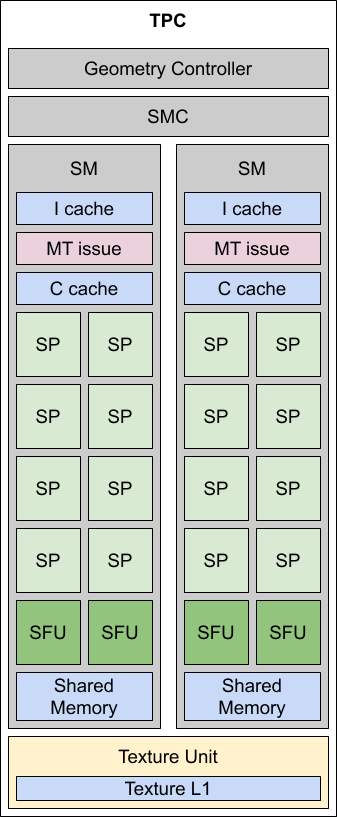
Таким образом, если уж что и называть "ядром" в микроархитектуре Tesla, используя этот термин в его устоявшемся в мире центральных процессоров значении, то такой вот кластер TPC. Конечно, на момент выхода G80, ядро, способное выполнять 32 инструкции над числами с плавающей точкой одинарной точности (FP32) за такт, было значительно более "широким", чем ядра всех актуальных на тот момент центральных процессоров x86. Например, современники G80, процессоры Intel микроархитектуры Core, могли похвастаться возможностью выполнять лишь 8 обсуждаемых инструкций за такт на ядро (SSE4). Да и ядер под одной крышкой могли предложить на тот момент только пару, а ни разу не 8, так что даже более высокие частоты не спасали центральные процессоры от значительно меньшей производительности. Так, пиковая FP32-производительность 2-ядерного Core 2 Extreme X6800 из той эпохи с частотой 2.93 ГГц составляла "всего" 2×2.93×8 = 46.88 GFLOPS, что на порядок ниже 345.6 GFLOPS у G80.
Но вернёмся к G80. Каждый блок текстурирования, входивший в состав кластера TPC, включал в себя 4 блока адресации и 8 блоков фильтрации текстур, а также кэш (текстур) первого уровня, при этом и блоки, и кэш работали на частоте ядра (575 МГц). Текстурные блоки в G80 были обособлены от потоковых процессоров — вычисления на последних могли выполняться одновременно с работой над текстурированием, в то время как предыдущие архитектуры вынуждали ядро прервать вычисление и ждать выборки и обработки текстуры, а лишь затем продолжить работу с шейдером.

Помимо собственного L1-кэша у кластеров TPC имелся также доступ к L2-кэшу и регистрам общего назначения, что было сделано для обеспечения упомянутой в начале статьи потоковой обработки данных — данные, обработанные всяким кластером TPC при выполнении определённого шейдера выгружались в общий кэш, откуда могли быть вычитаны другим кластером TPC и обработаны во время выполнения другого шейдера. Таким образом, итоговая диаграмма чипа G80 получается примерно такой, как показано ниже.
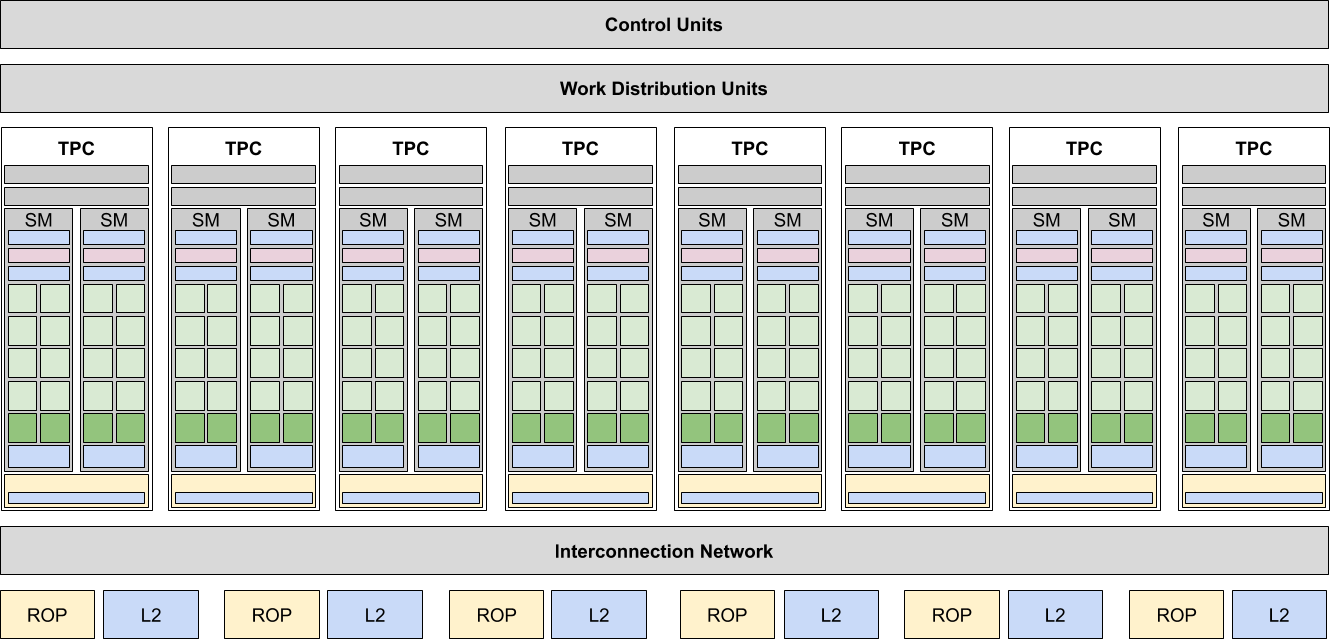
На этом, самом высоком логическом уровне организации чипа можно (при желании) заметить определённое сходство с предыдущими неунифицированными архитектурами, так как несмотря на новый унифицированный подход к 3D-рендерингу, многие закономерности процесса рендеринга остались в силе. Например, пиксели, расположенные на экране рядом друг с другом, проходят обычно одинаковый путь через конвейер независимо от архитектуры графического процессора, а значит по-прежнему имеет смысл обрабатывать пиксели квадами (фрагментами 2×2 пикселя). Только в новой унифицированной архитектуре место процессоров квадов, служивших верой и правдой долгие годы, заняли кластеры TPC — ранее каждый пиксельный процессор квадов состоял (минимум) из четырёх 4-компонентных векторных ALU для вычислений с плавающей точкой (по одному ALU на пиксель), теперь же их место заняли 16 скалярных ALU. То есть, условно говоря, каждый 4-компонентный векторный ALU был "разбит" на 4 скалярных, но так же как и ранее блок, обрабатывающие 4 квада пикселей снабжаются собственными текстурными блоками (4 TA, 8 TF) и L1-кэшем текстур. И так же, как и ранее "процессоры квадов" полностью независимы друг от друга вплоть до возможности полного физического исключения для создания урезанных версий старшего чипа.
Что же касается старшего полноценного чипа G80, то в его состав входило 8 кластеров TPC, каждый из которых содержал 16 потоковых процессоров SP и 4 блока TMU (4 TA + 8 TF), а также 6 "широких" блоков растеризации, способных обрабатывать по 4 пикселя каждый. Итоговая конфигурация полноценного чипа G80, таким образом, в формате SPs:TMUs:ROPs выглядела как 128:32:24. Имелось также 6 независимых контроллеров памяти (по одному на каждый широкий блок растеризации и L2-кэша), каждый шириной 64 бита и обслуживающий 128 МБ GDDR3-памяти на частоте 900 МГц, что давало 8800 GTX 384-битную шины памяти и 768 МБ GDDR3-1800 памяти на борту.
Карта
К нам на тесты заглянула карточка, производителя которой олды c лёгкостью узнают по наклейке "с мужиком". Всё верно, у нас в руках продукт давно уже почившей американской BFG Technologies.

Каюсь, что это за персонаж такой не знаю, но присутствовал он в различных цветовых вариациях на многих картах от BFG. На 8800 GTX, например, "мужик" был голубым, но в 2000-х никаких дополнительных смыслов в этом никто не искал, так что и мы теперь не будем. Надо заметить, что большинство карточек 8800 GTX имели референсный дизайн не только печатной платы, но и системы охлаждения и отличались только подобными красочными наклейками. Собственно, по причине идентичности конструкции большинства 8800 GTX, не буду вас мучить моими низкокачественными фотографиями, сделанным "на мобилку", посмотрите лучше, если интересно, фотографии в старых профессиональных обзорах.
Референсная система охлаждения турбинного типа, однако, турбина сравнительно больших размеров и работает на сравнительно небольших оборотах, а потому кулер в целом тихий, даже спустя годы и при высокой нагрузке. Радиатор под пластиковым кожухом оснащён тепловыми трубками и имеет медную пластину, соприкасающуюся с ядром, а всё остальное выполнено из алюминиевого сплава. В FurMark температуры после чистки системы охлаждения и нанесения свеженькой GD900 не поднимались выше 85 °C, при этом у турбины был ещё неплохой запас по скорости вращения.

В момент выхода GeForce 8800 GTX на рынок сложилась парадоксальная ситуация — первый 3D-ускоритель с поддержкой DirectX 10 уже можно было купить, но ни игр “под” эту новую версию графического API, ни даже самой Windows Vista, для которой DirectX 10 должен был стать эксклюзивом, ещё представлено не было. По этой причине в обзорах новинки проводили её сравнение с флагманами предыдущих поколений, и в той ситуации это было более чем уместно. И уже на фоне флагманов прошлого было отчётливо видно, что новый топовый ускоритель NVIDIA получился неимоверно мощным — 8800 GTX опережал, и зачастую значительно, не только топовые одночиповые Radeon X1950 XTX и GeForce 7900 GTX, но и двухчипового монстра GeForce 7950 GX2! В дальнейшем с выходом Windows Vista и появлением DirectX 10 игр ситуация сильно не поменялась — 8800 GTX был настолько хорош на момент выхода, что серьёзных конкурентов по игровой производительности у него не было долгое время. Только через год у NVIDIA появится GeForce 8800 GTS 512 на чипе G92, который в целом не уступал герою сегодняшнего обзора, а чуть позже и по сути разогнанный вариант этой карты в лице GeForce 9800 GTX, который уже в целом обгонял 8800 GTX, но преимущество было не столь существенным. По-настоящему сместить 8800 GTX с трона одночиповых решений смогла только GeForce GTX 280, вышедшая в июне 2008!
Конечно, необходимо учитывать тот факт, что дела у конкурента NVIDIA в то время шли откровенно плохо, так что привычной острой конкуренции на рынке графических ускорителей не было, но, тем не менее, глядя на то, как GeForce 8800 GTX продержался на вершине более года, можно утверждать, что потенциал у карты был хороший. А насколько именно хороший мы сегодня и увидим. Тестировать будем на частотах референсной 8800 GTX, для чего уберём небольшой заводской разгон.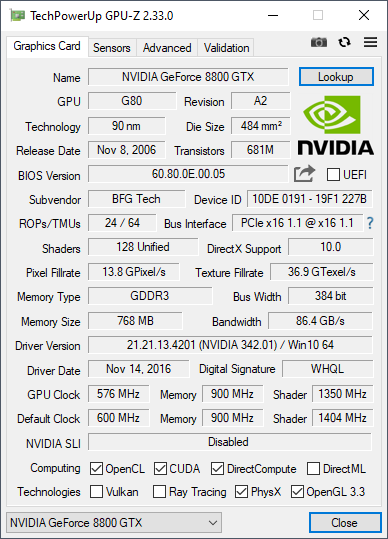
Раскрывать потенциал будем аж на Windows 10, так как установить полноценно работающую Windows 7 на плату с чипсетом Z390 оказалось жутко геморройно. Тестовый стенд всё тот же — материнская плата GIGABYTE Z390 GAMING SLI и процессор i5-9600K в небольшом разгоне до 4.8 ГГц на все 6 ядер. Оперативная память 2x16 ГБ Ballistix Sport LT (BLS16G4D32AESE), разогнанная до 3733 МГц с первичными таймингами 16-20-20-40. Windows 10 установлена на SSD, игры — на HDD.
Будет, безусловно, интересно понаблюдать за схваткой 8800 GTX с конкурентами из прошлого, но не в этот раз. На подготовку материала даже по одной карте уходит много времени — достаточно много, по моему мнению, чтобы результаты были оформлены в отдельную статью. Поэтому конкурент пока будет другой, посовременнее, и те, кто прочитал хотя бы один мой обзор видеокарт из прошлого или хотя бы обратил внимание на состав тестового стенда, уже знают, кто сегодня составит 8800 GTX компанию. Всё верно — Intel UHD 630 в очередной раз выходит на тропу войны.
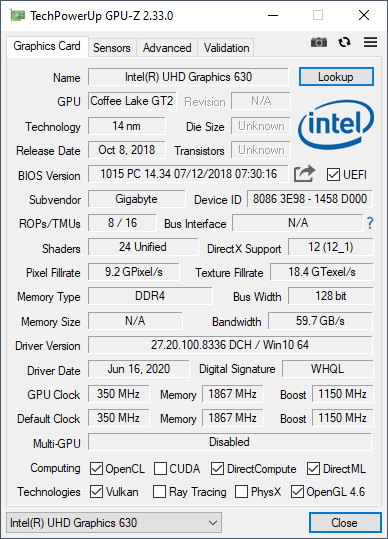
Когда-нибудь (дай бог, совсем скоро) Intel начнёт встраивать нормальную "графику" в свои процессорах, а заодно (опять же, дай бог) опубликует нормальные спецификации на свои интегрированные графические процессоры. Потому что на данный момент разобраться в потоке сознания под названием Intel Open Source HD Graphics and Intel Iris Plus Graphics Programmer's Reference Manual — практически непосильная задача. Допустим, описание чисто вычислительного аспекта архитектуры ещё более-менее поддаётся расшифровке, но что касается текстурирования и растеризации — тёмный лес какой-то. Например, у нас чип UHD 630, это Gen9.5 GT2 с 24 исполнительными блоками Execution Unit (EU). Каждый блок EU содержит 2 устройства для вычислений над числами с плавающей точкой, каждое из которых способно выполнять 4 инструкции MAD за такт. Таким образом, получаем, что каждый блок EU способен выполнить 8 инструкций MAD за такт, то есть максимум 16 инструкций над числами с плавающей точкой за такт, а весь чип 24×16=384 указанных инструкций за такт. Тогда показатель пиковой производительности на максимальной частоте в 1.15 ГГц составит 384×1.15=441.6 GFLOPS. Эта цифра сходится с тем, что можно увидеть в различных источниках. А вот каким образом программисты GPU-Z решили, что в UHD 630 8 блоков растеризации и 16 текстурных блоков — вот это для меня загадка, здесь придётся просто довериться авторам известной утилиты.

Но в целом картина получается похожей на правду, и если указанные характеристики верны, то UHD 630 должен быть быстрее 8800 GTX, но преимущественно на низких настройках и в низком разрешении — на "тяжёлых" текстурах и большом числе пикселей "встройку" будет "задушена" низким числом TMU и ROP-блоков. Но это в теории, да ещё и полагаясь на не совсем понятно откуда взявшиеся данные о количестве блоков растеризации и текстурирования. Чтобы проверить, как дела будут обстоять на практике, как и ранее, была отобрана дюжина популярных игровых проектов на различных "движках" со встроенными бенчмарками. Конечно же, на сей раз отбирались проекты прошлых лет, поддерживающие DIrectX 10 ускорители как посредством собственно DIrectX 10 API, так и посредством API DIrectX 11. Тестирование проводилось в 2 разрешениях (HD и FHD) и, как и ранее, на нескольких вариантах настроек графики. Не обошлось и без синтетических тестов, с которых, собственно, и начнём.
Тесты
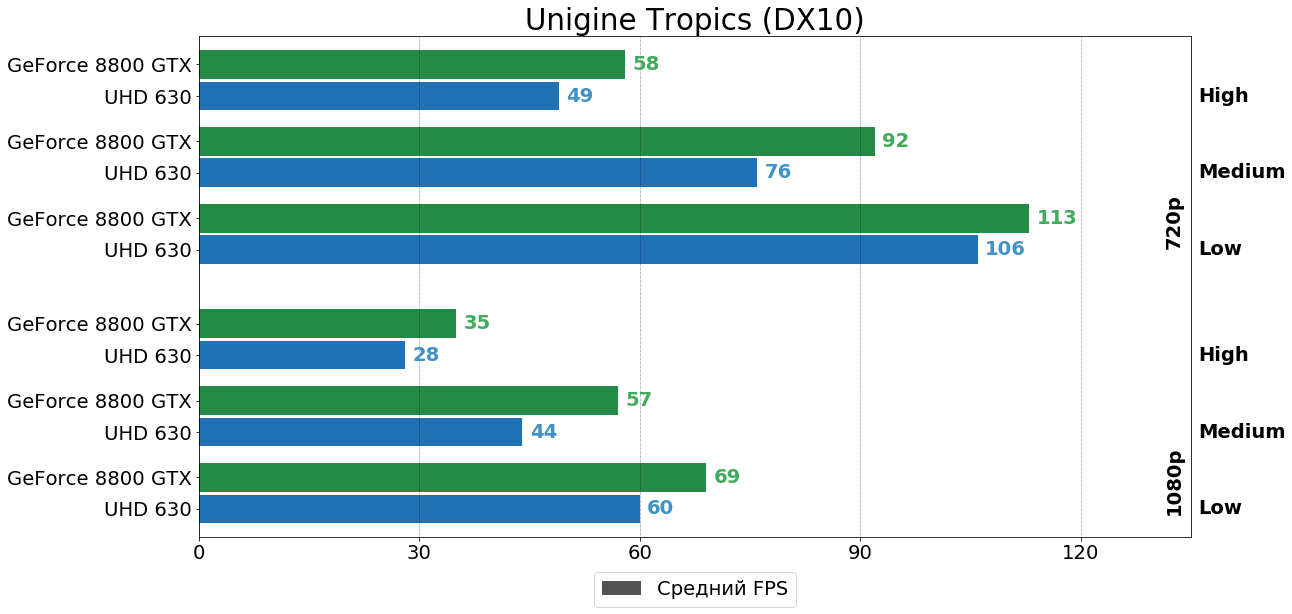
Unigine Tropics
 3DMark Vantage
3DMark Vantage
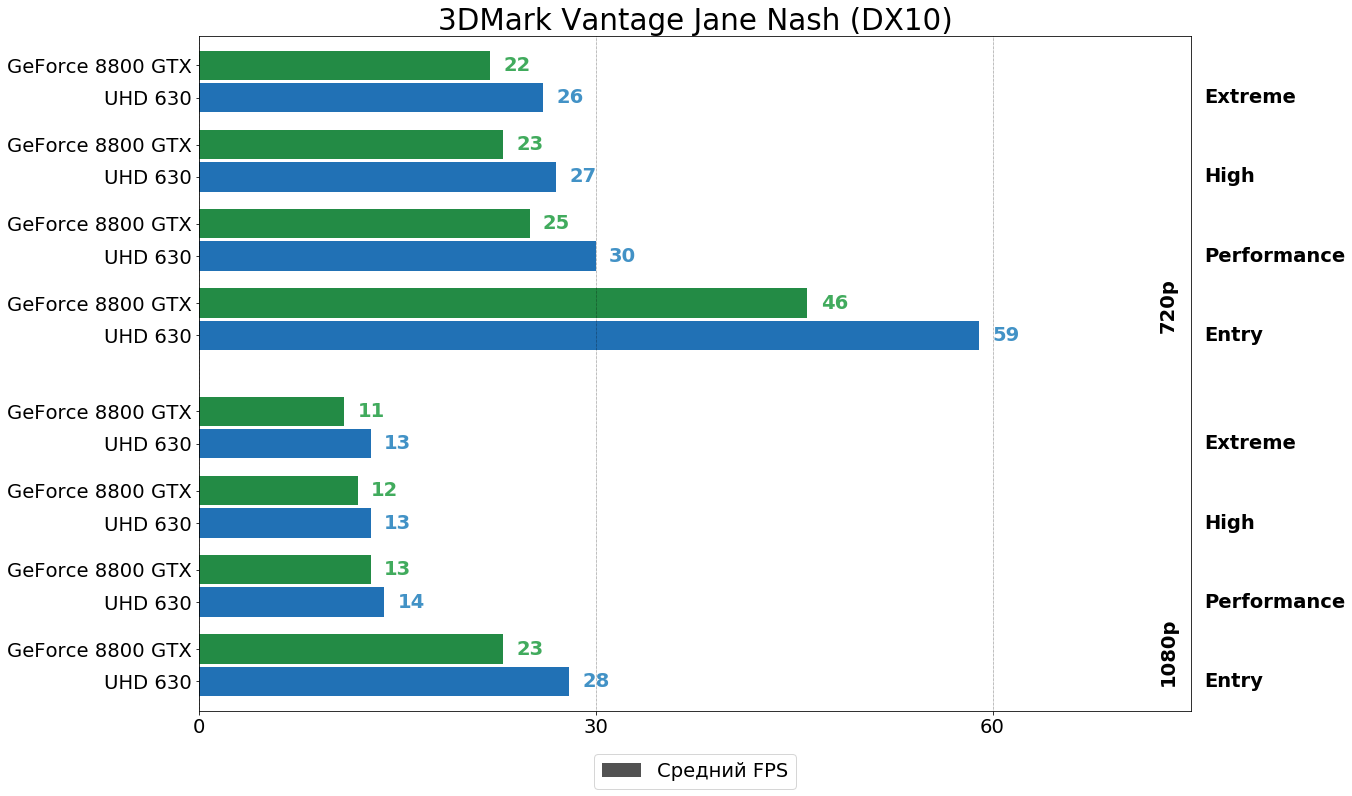

Старый-добрый Unigine Tropics на "движке" Unigine 1-ой версии отдаёт предпочтение 145-Вт монстру из прошлого, а вот в 3DMark эпохи DirectX 10, напротив, впереди "встройка" от Intel. Обратите внимание, что в 3DMark в Entry настройках Post-Processing Scale был установлен равным 1:2, как и в остальных пресетах, а не 1:5, как это было сделано разработчиком бенчмарка. В оригинальном варианте набор настроек Entry ну слишком уж слабо нагружает ускорители и годится разве что для "встроек" тех лет.
3DMark Cloud Gate

В тесте Cloud Gate из актуальной версии 3DMark вновь превосходство на стороне UHD 630, но это всё "синтетика", а как оно будет в реальных играх мы ещё посмотрим. Однако, одно можно сказать точно уже сейчас — легко участникам тестирования в играх точно не будет. Кто бы не оказался впереди по итогу, на многое рассчитывать не приходится: в HD возможно что-то получиться и на средних настройках, а вот в FHD — дай бог "на минималках".
Call of Juarez (Chrome Engine 3, 2007)
 Call of Juarez вышла ещё в 2006 году, но поддержкой DirectX 10 обзавелась только в 2007, причём поначалу только в виде отдельного бенчмарка. Игра стало одной из первых, в которой визуальные отличия DirectX 10 версии просто таки бросались в глаза в отличие от множества других проектов, где изменения приходилось искать в буквальном смысле с лупой. В целом наблюдаем небольшое преимущество UHD 630, особенно заметное на высоких настройках.
Call of Juarez вышла ещё в 2006 году, но поддержкой DirectX 10 обзавелась только в 2007, причём поначалу только в виде отдельного бенчмарка. Игра стало одной из первых, в которой визуальные отличия DirectX 10 версии просто таки бросались в глаза в отличие от множества других проектов, где изменения приходилось искать в буквальном смысле с лупой. В целом наблюдаем небольшое преимущество UHD 630, особенно заметное на высоких настройках.
Crysis (CryEngine 2, 2007)
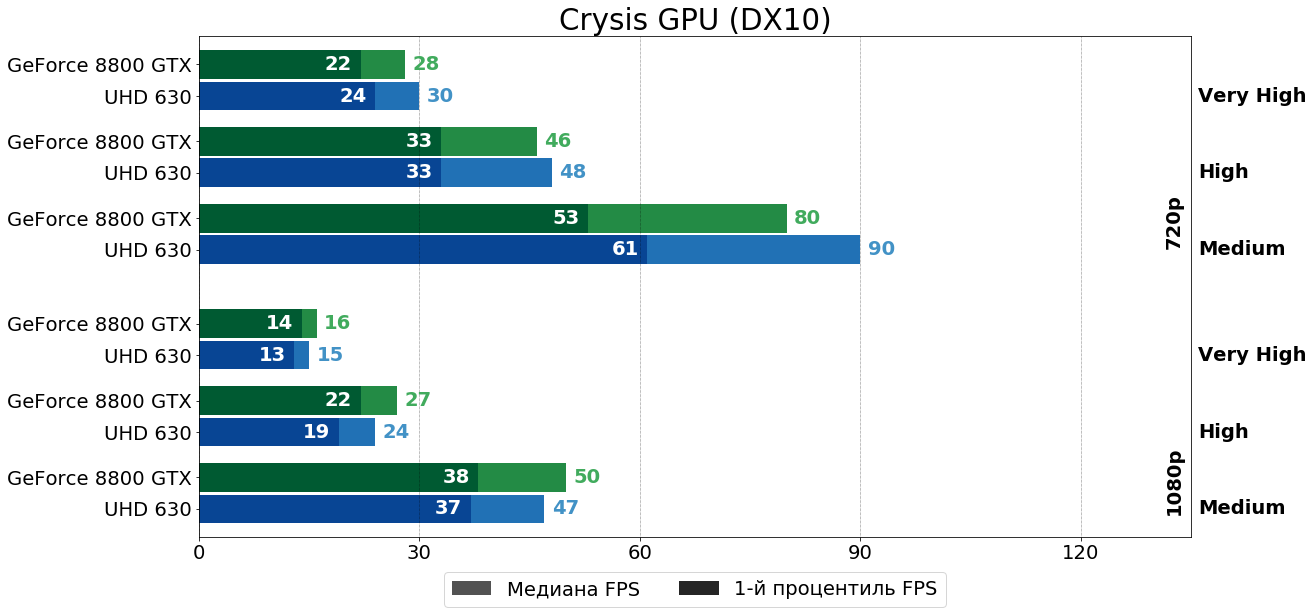
Сколько игр не тестируй, а на вопрос But can it run Crysis? ответить ты обязан. Конечно, в отличие от Call of Juarez, Crysis, как и многие другие игры тех лет, не сильно отличался по уровню картинки в режиме DirectX 10, но в отличие от многих других игр дело обстояло так только потому, что выглядел Crysis просто потрясающе и при использовании "старого" DirectX 9 API. Правда, минимальные настройки было решено отбросить, так как их вышесказанное не касалось — на минимальных настройках игра ни разу не выглядела как технологический шедевр. Да и FPS на нормальных картах в таком режиме "зашкаливал", так что начинаем со средних настроек и видим, что в HD-разрешении небольшая победа за UHD 630, а в FHD вперёд немного вырывается уже 8800 GTX.
Far Cry 2 (Dunia Engine, 2008)
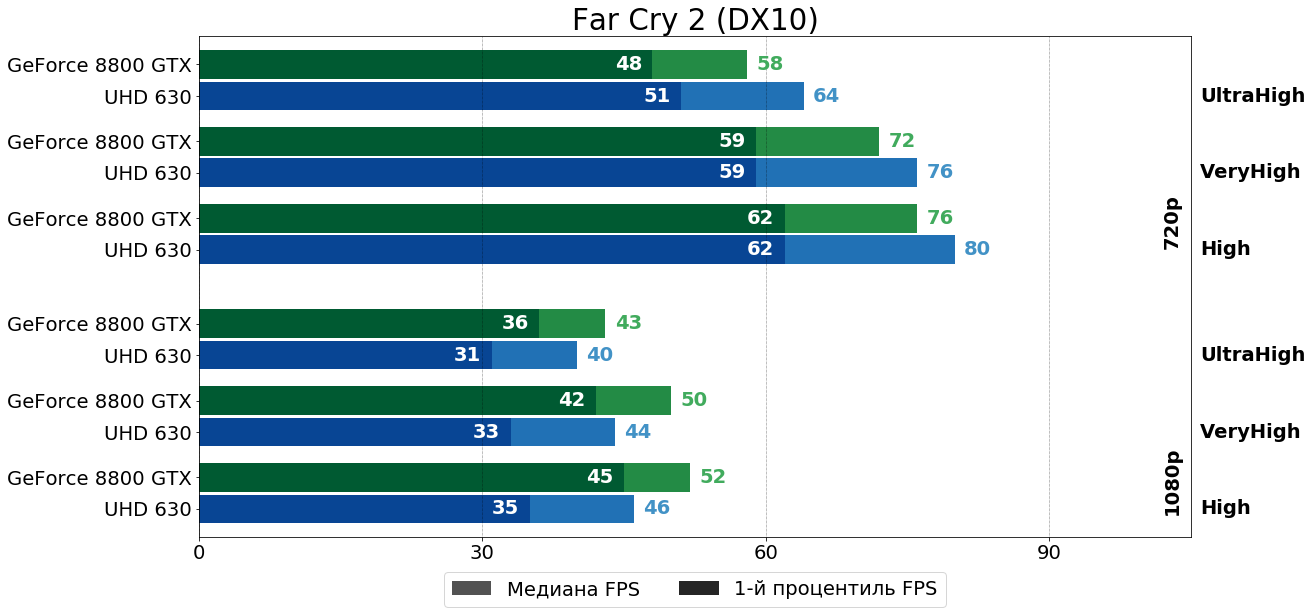
Ещё один, на этот раз прямой, потомок Far Cry, демонстрирует похожую картину производительности — в HD "встройка" Intel чуть быстрее, а в FHD, напротив, уже заметно медленнее. Здесь, кстати, также пропускаем низкие и даже средние настройки, так как там и DirectX 10 не используется, и FPS на нормальных картах огромный.
S.T.A.L.K.E.R. Call of Pripyat (X-Ray Engine 1.6, 2009)
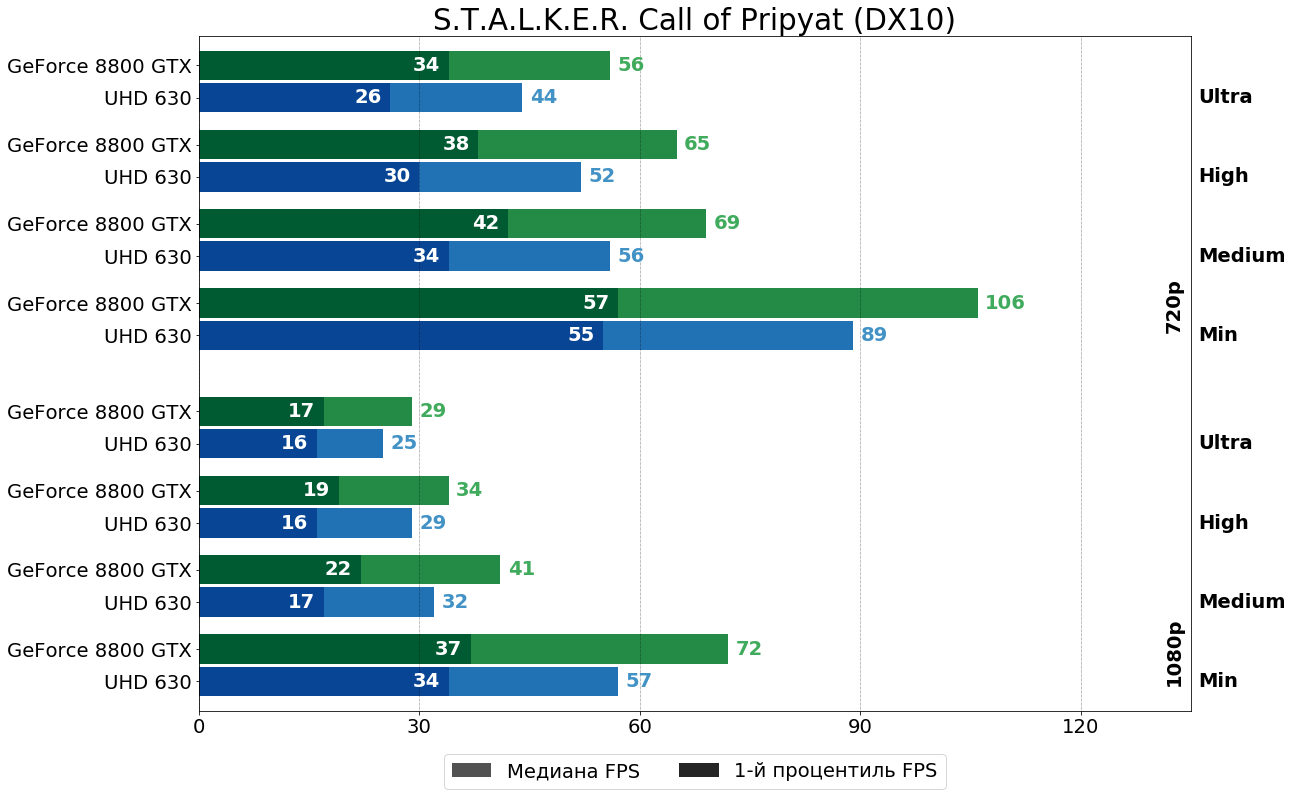 В последней (шучу-шучу, крайней) части столь любимой на постсоветском пространстве серии игр S.T.A.L.K.E.R. победа однозначно за 8800 GTX, пускай в "тяжёлых" режимах разница и не так велика. Как стало известно совсем недавно, Зов Припяти не будет последней игрой в серии, рано или поздно нас ждёт S.T.A.L.K.E.R. 2. Однако, хоть в чём то, но S.T.A.L.K.E.R. Call of Pripyat таки будет последним — это будет последняя игра в нашем тестировании, разработанная "под" DirectX 10. Дальше будут только игры уже "под" DirectX 11, поддерживающие DirectX 10 ускорители за счёт концепции уровней поддержки, о которой было рассказано в теоретической части.
В последней (шучу-шучу, крайней) части столь любимой на постсоветском пространстве серии игр S.T.A.L.K.E.R. победа однозначно за 8800 GTX, пускай в "тяжёлых" режимах разница и не так велика. Как стало известно совсем недавно, Зов Припяти не будет последней игрой в серии, рано или поздно нас ждёт S.T.A.L.K.E.R. 2. Однако, хоть в чём то, но S.T.A.L.K.E.R. Call of Pripyat таки будет последним — это будет последняя игра в нашем тестировании, разработанная "под" DirectX 10. Дальше будут только игры уже "под" DirectX 11, поддерживающие DirectX 10 ускорители за счёт концепции уровней поддержки, о которой было рассказано в теоретической части.
Metro 2033 (4A Engine, 2010)

Ну и раз уж мы тут разнастальгировались по "нашему" игрострою, то не пройдём мимо и первой части серии игр Metro, благо Metro 2033 даже в 2010 шутки с видеокартами не шутила. UHD 630 здесь сильно впереди в HD-разрешении и незначительно лучше в FHD.
Total War Shogun 2 (TW Engine 3, 2011)

Следующий, 2011, год представляет очередная часть Total War, и в разработке британской The Creative Assembly UHD 630 вновь "на коне", причём в HD-разрешении прям совсем без шансов для "старичка" в лице 8800 GTX.
Sniper Elite V2 (Asura Eingine, 2012)
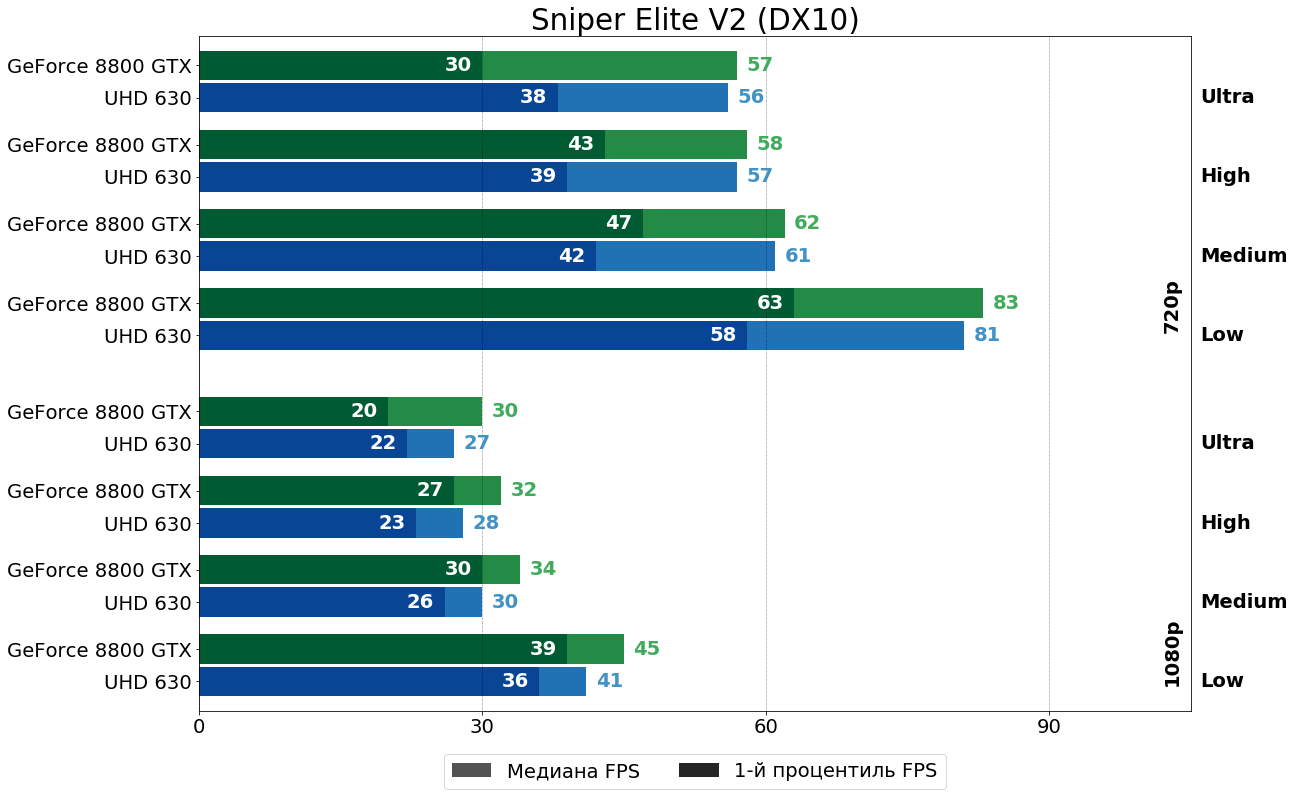
Не дать проклятым нацистам довести до ума ракетную программу и запустить ракету на Лондон одинаково хорошо получится и на UHD 630, и на 8800 GTX. В FHD незначительно преимущество за "старичком", но в целом +/- ровно.
Hitman Absolution (Glacier 2, 2012)
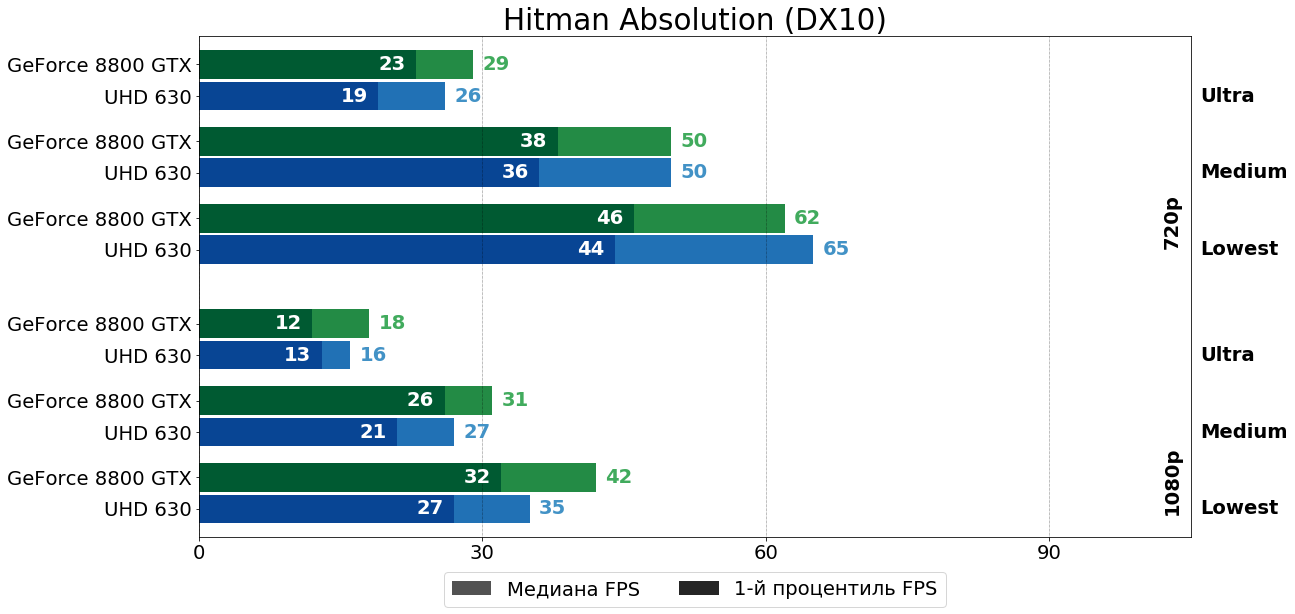
Аналогичным образом выглядит картина производительности и в Hitman Absolution — в HD особой разницы не наблюдается, а в FHD предпочтительнее смотрится 8800 GTX.
BioShock Infinite (Unreal Engine 3, 2013)
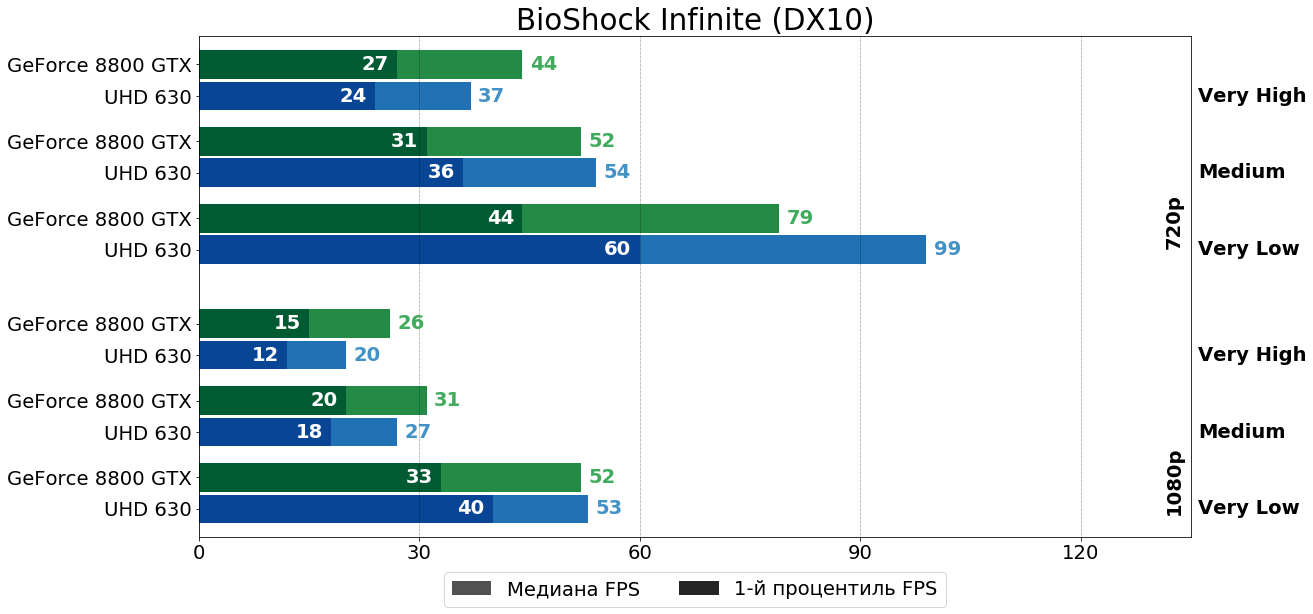
В BioShock Infinite чем "тяжелее" режим, тем лучше себя проявляет 8800 GTX, но в общем и целом вновь можно говорить о паритете.
Tomb Raider (Crystal Engine, 2013)
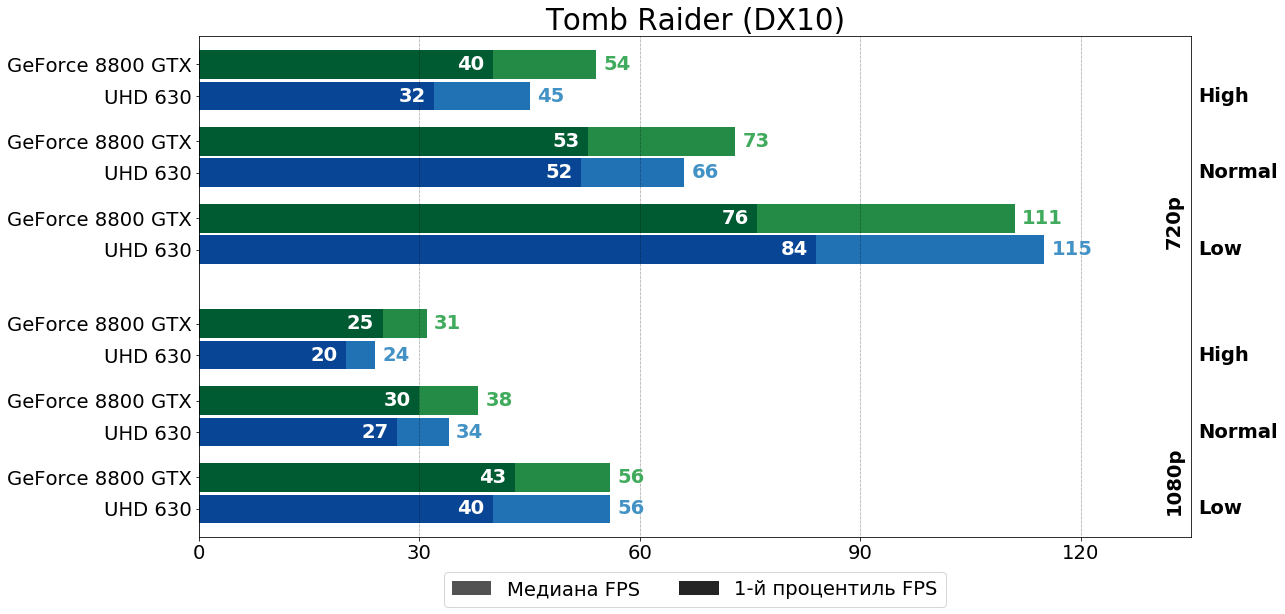
Похожим образом ведёт себя и Мисс Крофт — на низких настройках соперники демонстрирую практически идентичную производительность, но "чем дальше в лес", тем лучше результаты 8800 GTX.
F1 2014 (EGO Engine, 2014)
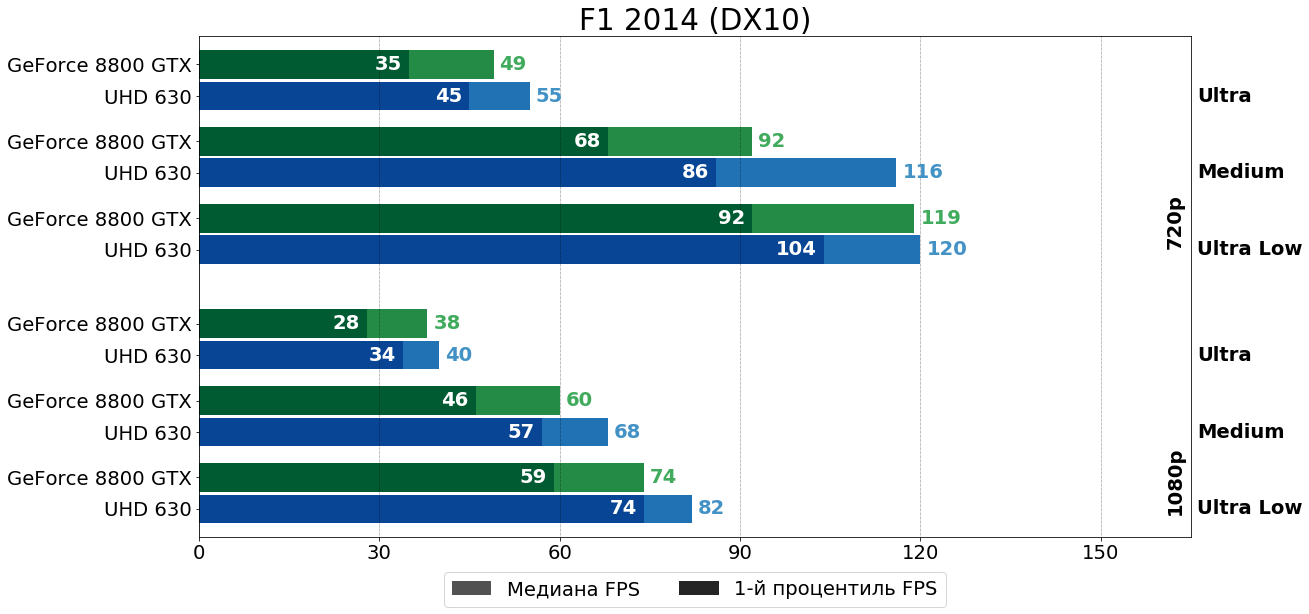
Последние "покатушки" Codemasters на старенькой постгеновской (или теперь получается уже правильно говорить постпостгеновской) версии "движке" EGO Engine симпатизируют современной "встройке" — UHD 630 заметно быстрее во всех режимах.
Grand Theft Auto V (RAGE, 2015)
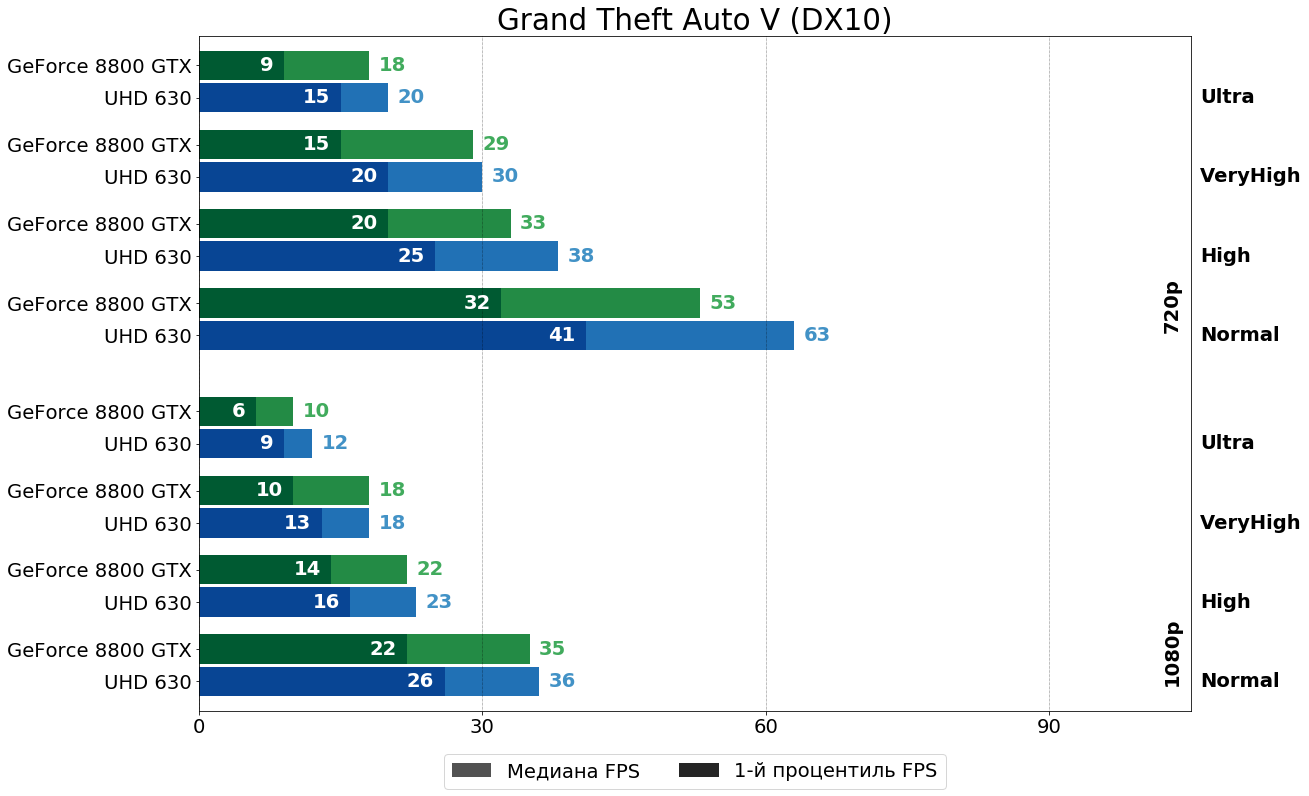
Последняя из тестируемых игр — юбилейная (пятнадцатая по счёту) игра, не побоюсь этого слова, великой серии, самая дорогостоящая по затратам на разработку и маркетинг в истории и одна из самых популярных в истории, уступающая по продажам лишь Tetris и Minecraft. И вновь преимущество за UHD 630, пускай местами и чисто номинальное.
Среднегеометрические результаты
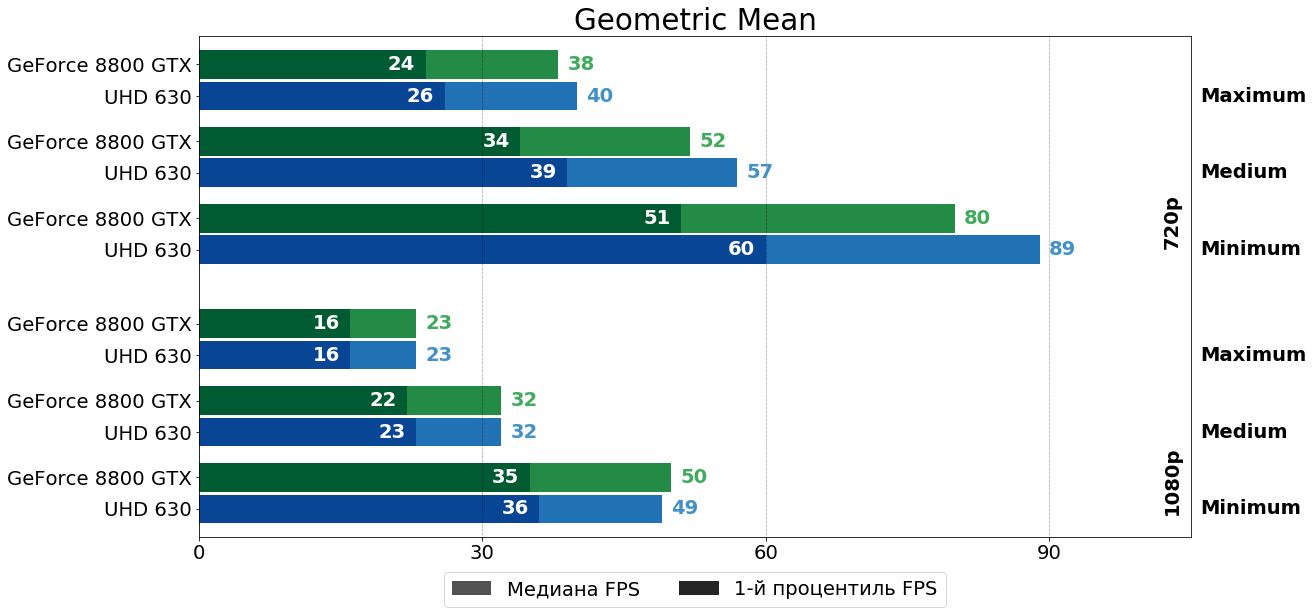
В завершении столь всеми любимая "средняя температура по больнице" по всем игровым тестам, лишь резюмирующая и так уже очевидный для всех просмотревших единичные тесты вывод: в HD разрешении Intel UHD 630 впереди на 2–10 FPS, а в FHD — почти идеальное равенство.
Выводы
- Та, о которой большинство ПК-геймеров могли только мечтать в 2006, та, которая ставила на колени все предыдущие "топы" (а заодно вставала и сама, причём даже в SLI, но то перед лицом Crysis на ультра-настройках, а это не считается), GeForce 8800 GTX, спустя годы находится на одном уровне производительности с "встройкой" Intel. Можно по-разному относится к этому факту: многие видавшие виды миллениалы смахнут скупую слезу под "Виват, король, виват!", зумеры — лишь злорадно посмеются над всем происходящим. Ну а если серьёзно, то даже не знаю чего в упомянутом факте равенства 8800 GTX и UHD 630 можно увидеть больше — неумолимого хода технического прогресса или бездарности Intel, догонявшей видеокарту 2006 года, пускай и топовую да ещё и в своих "встройках", но всё же больше 10 лет.
- Технические характеристики UHD 630, приведённые в таблице и взятые из вывода утилиты GPU-Z, кажутся похожими на правду — как и ожидалось, "встройка" быстрее "считает", но испытывает проблемы на высоких настройках графики и в высоких же разрешениях из-за малого количества TMU и ROP.
- Можно сколько угодно ругать 3DMark за множественные недочёты, но этот бенчмарк был и остаётся чертовски неплохой "синтетикой", крайне редко демонстрирующей несоответствующие действительности цифры по крайней мере относительной производительности. Вот и в этот раз результаты как старого 3DMark Vantage, так и (сравнительно) нового 3DMark Cloud Gate значительно ближе к результатам игровых тестов, чем, например, то, что показал Unigine Tropics.
Основные источники информации
- [overclockers.ru] Обзор новой графической архитектуры NVIDIA GeForce 8800
- [iXBT.com] NVIDIA GeForce 8800 GTX (G80). Часть 1, 2, 3.
- [ferra.ru] nVIDIA GeForce 8800: революция свершилась! Часть первая: архитектура G80
- NVIDIA Tesla: A Unified Graphics and Computing Architecture (PDF, 1.2 МБ)
- [Beyond3D] NVIDIA G80: Architecture and GPU Analysis
- [Beyond3D] NVIDIA G80: General Performance Analysis
- [AnandTech] NVIDIA's GeForce 8800 (G80): GPUs Re-architected for DirectX 10
- [WikiChip] Intel Gen9.5 Microarchitecture
Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.