
Ретробенчмаркинг — HD 2900 XT (R600)
Введение
Статья является логическим продолжением недавно опубликованной заметки о GeForce 8800 GTX, но прежде чем мы продолжим двигаться дальше, считаю нужным сделать несколько пояснений с целью не тратить ни сейчас, ни в дальнейшем время для ответов на одни и те же вопросы.
Начну с того, что отмечу, пожалуй, самый важный момент во всей этой истории — мне прежде всего интересна эволюция архитектур графических процессоров, а не все аспекты конкурентной борьбы NVIDIA и ATI/AMD на рынке видеоускорителей. Как следствие, акцент в первую очередь будет сделан на топовых полноценных оригинальных чипах двух указанных производителей, а не на их различных разогнанных или, наоборот, "заторможенных" или "обрезанных" версиях, единственной целью существования которых была максимально простая для производителя - сегментация рынка. Это не означает, что карт помладше или постарше всякого очередного оригинального "топа" в обзорах не будет, но приоритет будет отдан именно картам на полноценных оригинальных чипах, как максимальным образом раскрывающим идеи, заложенные в конкретную микроархитектуру. Именно из этих соображений первая заметка с обзором микроархитектуры Tesla была посвящена оригинальному ускорителю GeForce 8800 GTX на полноценном чипе G80, а не GeForce 8800 GTS или GeForce 8800 Ultra на "обрезанном" или слегка разогнанном G80, соответственно.
Подход с тестированием преимущественно оригинальных топовых ускорителей будет чреват тем, что периодически мы будем вынуждены, как может показаться на первый взгляд, сравнивать несравнимое — ситуации, когда новая топовая видеокарта от одного производителя уже с самого начала продаж не позиционировалась как конкурент топовой видеокарте другого, были не такими уж редкими, особенно в эпоху DirectX 10. Однако, если копнуть глубже, становится понятно, что смысл в таком подходе всё-таки есть.
- Во-первых, нужно понимать, что соображения экономического характера, зачастую просто обязывающие сравнивать "железки" одной ценовой категории, имеют принципиальное значение только для актуальных устройств, а в тестах старых образцов "железа" спустя многие годы этот аспект становится не таким уж и важным.
- Во-вторых, очень часто оригинальные версии технологически сложных устройств проектируются не исходя из какой-то заранее заложенной конечной стоимости, а лишь с целью максимально полного воплощения ключевых идей, заложенных в соответствующую архитектуру. Цену затем определяет производительность того, что получилось относительно уже имеющихся на рынке предложений, причём как предложений конкурентов, так и собственных. Причём цена может ещё и многократно корректироваться в зависимости от развития ситуации на рынке, можно даже начать открыто демпинговать, если получилось совсем плохо, плюс на основе одного оригинального устройства начать выпуск целой серии устройств в целях сегментации. Да много чего можно сделать, важно тут то, что первична именно архитектура, а экономические аспекты — вторичны, особенно спустя годы.
- В-третьих, вторичны экономические аспекты на самом деле всегда, если только нас интересуют не экономические результаты конкурентной борьбы, а в первую очередь технологии. С этих позиций сравнения оригинальных топовых решений всегда было, есть и будет уместным, так как оно показывает, за кем из конкурентов в какой-то определённый момент времени было технологическое преимущество. Смог ли он при этом извлечь из этого лидерство экономическое и какие рыночные механизмы в сложившейся ситуации задействовал технологически отстающий конкурент — эти и подобные им вопросы уже выходят за рамки чисто технических аспектов
-
реклама
Повторюсь, что столкнуть двух непосредственных конкурентов из одной ценовой категории тоже интересно, но пока в приоритете тестирование и анализ ускорителей на оригинальных полноценных чипах, без учёта позиционирования на рынке в давно ушедшие годы. Также отмечу, что разгона в этом цикле статей не будет — мало того, что испытывать живых "старичков" на прочность разгоном нет особого желания, так ещё и основная цель состоит в том, чтобы посмотреть, как оно было задумано разработчиками в оригинале. Да и практического смысла в разгоне, если честно, мало — абсолютное большинство ускорителей (особенно ускорителей топовых да ещё и спустя многие годы, когда дай бог, чтоб работало "в стоке") гонятся +/- одинаково, притом одинаково плохо. К тому же, 10-15% прибавка к частотам ядра, шейдерного блока, памяти даже если и выльется в такой же прирост игровых показателей, кардинальным образом ситуацию не изменит. Более того, в абсолютном большинстве случаев при сравнении нескольких ускорителей разгон ситуацию вообще никак не изменит, так как будет на +/- одинаковом уровне для большинства карт. А вот SLI/CrossFire решения можно будет "пощупать", но пока только те варианты, которые найду "за недорого" в двойном экземпляре и для которых хватит моего 630-Вт блока питания с двумя 6/8-пиновыми коннекторами, то есть точно не 8800 GTX и не HD 2900 XT.
R600 — рождённый в муках
Первые видеокарты с поддержкой DirectX 10 появились в продаже ещё в конце 2006 года, когда были представлены два решения из новой 8-ой по счёту серии графических ускорителей NVIDIA GeForce —GeForce 8800 GTS (640 MB) и GeForce 8800 GTX, обе на чипе G80, пускай и несколько "урезанном" в младшем GTS-ускорителе. В начале следующего 2007 года NVIDIA выпустит ещё один вариант ускорителя 8800 GTS на "урезанном" G80 с вдвое меньшим количеством памяти на борту (320 MB), а в начале третьего квартала разродится ещё и несколькими решениями начального и среднего уровня на младших чипах G84 и G86, представлявшими собой в разы урезанный чип G80. GeForce 8800 GTX уже побывал у нас на обзоре, 8800 GTS (640 MB) даст бог найду неубитую и тоже протестирую, остальное — неинтересно, так как там и памяти, а часто ещё и потоковых процессоров "маловато будет". Что-то по-настоящему интересное, особенно спустя многие годы, на рынке видеоускорителей появилось только в мае 2007 года, кода конкурент NVIDIA в лице ATI Technologies (на тот момент уже будучи графическим подразделением AMD) представил наконец свой ответ первым DirectX 10 ускорителям Хуанга и компании.
Да, ATI/AMD очень сильно (почти на полгода) затянули с выпуском ответных решений, и на столь длительную задержку безусловно повлияли сложности, связанные с приобретением ATI Technologies компанией AMD. Причём не столько с самим фактом приобретения, сколько с его конечной целью — AMD желала сфокусироваться в первую очередь на интегрированных решениях AMD Fusion, содержавших центральный и графический процессор на одном кристалле, а разработка дискретных графических ускорителей в приоритет поставлена не была. Ведь если бы приоритеты были расставлены иначе, нет особых оснований сомневаться, что даже несмотря на все перипетии, связанные с переходом ATI под крыло AMD, столь долгой задержки бы не случилось, так как для ATI новые ускорители были уже вторым поколением с унифицированной шейдерной архитектурой. Первый унифицированный видеочип был разработан ATI годами ранее для игровой консоли Microsoft Xbox 360, и если бы не сфокусированность AMD на интегрированных решениях, новое семейство дискретных графических ускорителей с унифицированной архитектурой для ПК вышло бы, надо думать, значительно раньше. С другой стороны, здесь необходимо учитывать и тот факт, что за прошедшее с момента выхода первых DirectX 10 решений NVIDIA время хоть сколь-нибудь значимого числа DirectX 10 игр на рынке ПК не появилось, так что ничего катастрофического в упомянутой задержке для AMD, по большому счёту, и не было.
реклама
Куда хуже было то, что была нарушена “многовековая” традиция, согласно которой каждый новый флагман, выпускаемый NVIDIA или ATI, превосходил предыдущий флагман конкурента — топовый продукт новой линейки в лице Radeon HD 2900 XT на полноценном чипе R600 соперничал по большей части всё-таки с GeForce 8800 GTS (640 MB), а не с 8800 GTX, и уж тем более не с выпущенной прямо перед анонсом HD 2900 XT на всякий случай, что называется "на упреждение", GeForce 8800 Ultra. В сравнении с GeForce 8800 GTS новинка AMD была в целом быстрее, паритет, а иногда и небольшое превосходство GeForce наблюдалось лишь в "тяжёлых" режимах с использованием полноэкранного сглаживания (о причинах поговорим ниже). Правда, на стороне GeForce 8800 GTS были такие не всегда маловажные факторы как меньшее энергопотребление и тепловыделение, более тихая система охлаждения и больший объём видеопамяти. Если смотреть на ситуацию без эмоций, можно констатировать, что новинка AMD обладала достойной производительностью за свои деньги, и, как следствие, без особого труда нашла своего покупателя. И с этой точки зрения провала не случилось, хотя было близко, вот только многочисленная армия фанатов ATI, ровно как и многие энтузиасты ПК-гейминга, ожидали от 2900 XT, конечно же, большего. Вот и давайте посмотри, как же так получилось, что ускоритель на новом чипе R600 не мог тягаться с вышедшим на полгода ранее топовым решением NVIDIA GeForce 8800 GTX, что заставило AMD уже на старте продаж скорректировать цену новинку до уровня GeForce 8800 GTS (640 MB) и даже чуть ниже.
Архитектура
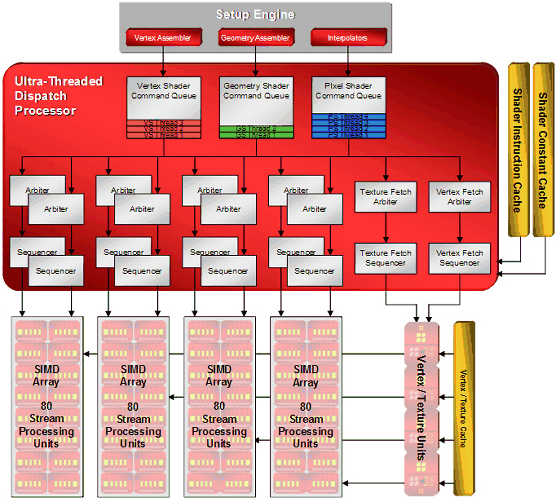
Фундаментальным исполнительным устройством графического процессора R600, основанного на микроархитектуре TeraScale, является так называемый потоковый процессор (Stream Processor, SP), представляющий собой простенькое (по сравнению с целым центральным процессором) скалярное исполнительное устройство для выполнения операций с целыми числами и числами с плавающей точкой. Конечно, как мы уже отмечали в ретро-обзоре GeForce 8800 GTX, у использования термина "процессор" применительно к этим по сути своей ALU/FPU-устройствам видны явные маркетологические корни, однако, первым так некрасиво поступил конкурент AMD/ATI в лице NVIDIA, который точно так же любил величать ALU/FPU-устройства в составе своих ускорителей потоковыми процессорами (а чуть позже ещё и CUDA ядрами), так что AMD здесь особо выбирать и не приходилось. Как говориться, с волками жить — по-волчьи выть.
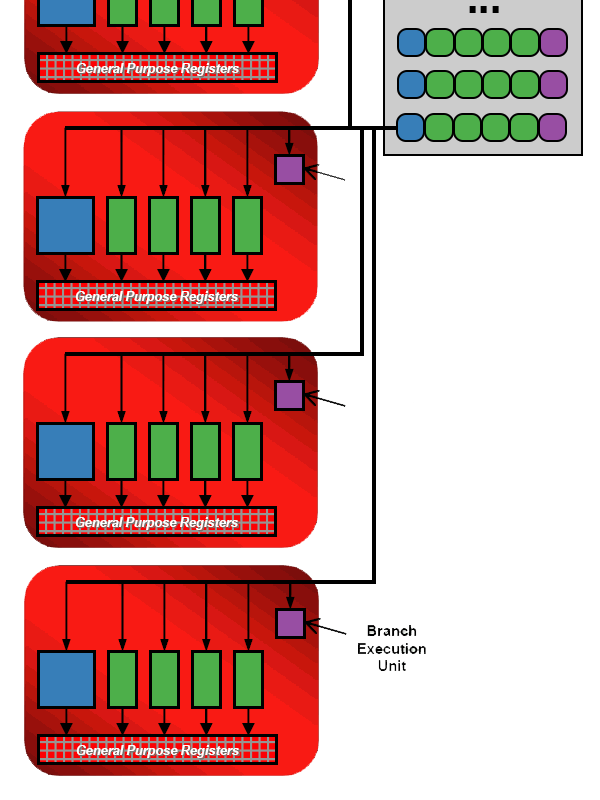
В микроархитектуре TeraScale пять потоковых процессоров совместно с устройством выполнения ветвлений (Branch Execution Unit), а также регистрами общего назначения, необходимыми для хранения данных, объединялись в блоки Stream Processing Unit (SPU).

При этом функциональность 4 "малых" потоковых процессоров и 5-ого "большого" существенно разнилась:
- Каждый из "малых" процессоров умел выполнять сложение, умножение и совмещённое умножение-сложение чисел с плавающей точкой, а также сложение целых чисел.
- "Большой" процессор был способен выполнять более сложные скалярные инструкции, такие, например, как вычисление значений трансцендентных функций (sin, cos, log, и другие), а также умножать и делить целые числа, выполнять для них битовые сдвиги и операции преобразования в/из чисел с плавающей точкой.
- Кроме того, все 4 "малых" процессора могли совместным трудом выполнять операцию вычисления скалярного произведения для векторов с 4 компонентами.
-
Все 5 потоковых процессоров в составе блока SPU были способны одновременно выполнять различные независимые инструкции, так что суммарно за один такт каждый блок SPU был способен выполнять до 5 различных математических инструкций над 5 скалярными величинами. А если учесть наличие отдельного блока для выполнения ветвлений, освобождающего потоковые процессоры от выполнения соответствующих инструкций, то получается, что каждый блок SPU мог обрабатывать до 6 независимых инструкций за один такт. Здесь уже должно стать вполне очевидно, что блоки SPU годятся на роль "ядер" в графических процессорах микроархитектуры TeraScale значительно лучше, чем потоковые процессоры. Конечно, им всё ещё недостаёт множества элементов ядер центрального процессора (как минимум, устройств загрузки/выгрузки из/в память и устройства управления, способного получать инструкции из хранилища инструкций и отправлять их на выполнений), но SPU уже гораздо ближе к понятию "ядер" в привычном понимании.
реклама
SPU в чипах микроархитектуры TeraScale были объединены в SIMD-массивы по 16 штук в каждом, при этом в диспетчере потоков (Ultra-Threaded Dispatch Processor) на каждый SIMD-массив приходилось по два арбитра и секвенсора, что давало возможность обрабатывать по 2 потока инструкций на SIMD-массив. Арбитр принимает решение о том, какой из потоков инструкций, стоящих в очереди на исполнение, следует выполнить на конкретном SIMD-массиве, а секвенсор способен в целях увеличения производительности менять порядок инструкций в потоке, отправленном на исполнение. Непосредственно чип R600 содержит 4 описанных SIMD-массива и способен, таким образом, выполнять до 8 потоков инструкций одновременно. Единственное ограничение заключалось в том, что всякий отдельно взятый SPU из конкретного SIMD-массива мог выполнять инструкции только над одним потоком данных. Под потоком данных здесь, как и ранее, понимается вершина, полигон или пиксель, над которым необходимо выполнить некоторую шейдерную программу. Обратите также внимание, что очереди команд для каждого типа шейдеров (вершинный, геометрический и пиксельный) раздельные.
В использовании параллелизма на уровне данных посредством SIMD нет, конечно же, ничего нового — сама задача 3D-рендеринга предполагает обработку большого множества однотипных данных одним потоком команд, так что все графические процессоры эксплуатируют этот подход. А до появления графических процессоров в первую очередь именно для ускорения 3D-рендеринга в процессоры центральные внедряли различные наборы SIMD-расширений, такие, например, как Intel MMX и AMD 3DNow! Куда интереснее то, что AMD в графических процессорах микроархитектуры TeraScale использовала достаточно интересный вариант параллелизма на уровне инструкций, известный как VLIW (Very Large Instruction Word, очень длинная машинная команда).
При использовании архитектуры VLIW одна процессорная инструкция содержит набор операций, которые должны выполняться параллельно различными независимыми исполнительными устройствами. От классических суперскалярных архитектур, популярных среди x86-процессоров, VLIW отличается тем, что управление исполнительными устройствами здесь осуществляется явным образом на уровне машинного кода. В составе суперскалярных процессоров также можно встретить несколько одинаковых исполнительных устройств, но машинный код пишется и выглядит так, будто бы такое исполнительное устройство всего одно, а уже в процессе исполнения одновременно, например, в течение одного такта, на нескольких одинаковых исполнительных устройствах может быть выполнено несколько независимых инструкций. Тот факт, что задача распределения работы между исполнительными устройствами в суперскалярном процессоре решается динамически на аппаратном уровне, сильно усложняет устройство процессора и может быть чревато ошибками.
В процессорах VLIW указанная задача решается статически на стадии компиляции, так что в получаемых машинных инструкциях уже явно указано, какую команду должно выполнять каждое исполнительное устройство. По этой причине длина инструкции может достигать 128 или даже 256 бит, отсюда и название подхода. Преимущество VLIW подхода заключается в значительном упрощении архитектуры процессора, ведь в нём задача распределения исполнительных устройств переложена на компилятор. Недостаток же состоит в том, что зачастую бывает трудно или вообще невозможно получить при компиляции поток инструкций, оптимальным образом использующий имеющиеся аппаратные блоки. Во-первых, инструкции в некотором коде никоим образом не обязаны присутствовать именно в той пропорции, в которой наличествуют в процессоре способные их выполнить исполнительные устройства, а во-вторых, одновременное выполнение инструкций невозможно в случае, когда выполнение одной зависит от результатов второй. Как следствие, код для VLIW-процессора обычно обладает невысокой плотностью, из-за большого количества пустых инструкций для простаивающих исполнительных устройств. Это снижает эффективность процессора и увеличивает размеры программ.
реклама
Конкретно в случае микроархитектуры TeraScale первого поколения каждое слово машинной команды может содержать до 6 независимых инструкций, 5 математических и 1 управляющую — ровно столько, сколько независимых исполнительных устройств имеется в составе каждого блока SPU. В идеальном сценарии всякая очередная длинная машинная команда исполняемого шейдерного кода содержит ровно указанное выше количество инструкций. Тогда в рамках SIMD подхода легко и просто получается параллельно выполнить такую команду на множестве блоков SPU, которые при этом будут использованы максимально эффективно — ни один из 5 потоковых процессоров, ровно как и устройство выполнения ветвлений, простаивать не будет.
Вот только подобный идеальный сценарий реализуется не так уж и часто. Для создания максимально оптимального потока инструкций необходим качественный оптимизирующий компилятор (в случае графических процессоров, компилятор шейдеров), а также определённые оптимизации со стороны приложений. Это в общем то история всех VLIW-архитектур процессоров, как графических, так и центральных — их высокая теоретическая эффективность зачастую оказывается трудно достижимой в реальности, так как даже при использовании сложного оптимизирующего компилятора получаемый поток машинных инструкций редко бывает даже близок к оптимальному.
Вот так и получалось, например, что в играх Radeon HD 2900 XT, имевший в своём составе целых 320 потоковых процессоров (4 SIMD-массива из 16 блоков SPU по 5 потоковых процессоров в каждом) уступал флагману NVIDIA GeForce 8800 GTX/Ultra, который мог похвастаться лишь 128 потоковыми процессорами. Конечно, необходимо помнить, что шейдерные процессоры в решении NVIDIA работали на более чем удвоенной (относительно ядра) частоте, но этого всё равно было бы мало, если бы потоковые процессоры AMD частенько не простаивали из-за невозможности всякий раз набрать необходимое для полной их загрузки количество независимых инструкций. Вот и ещё один показательный пример, почему никогда не стоит сравнивать разные архитектуры ни по количеству исполнительных блоков, ни по пиковой теоретической производительности. Тут, конечно, можно возразить, что ведь не играми едиными, и даже несмотря на то, что речь идёт об игровой карте, этот аргумент имеет право на жизнь. Всё дело в том, что уже в те годы поистине огромная производительность графических процессоров в расчётах как с плавающей точкой, так и целочисленных, а также гибкость появившихся унифицированных шейдерных архитектур дали сильный толчок к применению GPU в различного рода неграфических (например, научных) расчётах.
Причём, оба производителя игровых решений, и ATI/AMD, и NVIDIA, уже выпускали специализированные для неграфических расчётов ускорители, основанные на той же самой архитектуре, что и игровые карты. Так, ATI ещё на базе чипа прошлого поколения R580, использовавшегося в игровых картах Radeon X1900 GT/XT/XTX и X1950 XT/XTX, успела выпустить специализированную для неграфических расчётов карту Stream Processor, оснащённую целым гигабайтом GDDR3-памяти вместо привычных для игровых решений 256/512 МБ. Новый же чип R600 обладал ещё большей вычислительной мощью, унифицированной архитектурой с впервые в истории ATI/AMD публично опубликованным набором инструкций, а все потоковые процессоры выполняли операции над числами одинарной точности да ещё и с соблюдением стандарта IEEE 754. Ну просто сказка для неграфических расчётов! Специализированное решение FireStream 9170, правда, вышло лишь в конце 2007 года и уже на обновлённом 55-нм RV670, но сути дела это особо не меняет. На тот момент уже ставшая традиционной ставка ATI/AMD в первую очередь на математические вычисления (операции над пикселями и вершинами) сильно пригодилась в неграфических расчётах. Однако, протестировать скорость неграфических расчётов на R600 для целей сравнения с G80 особо и нечем, так как поддержка API OpenCL появилась только в R700 (Radeon HD 4000), а в R600 и его 55-нм обновлении RV670 (Radeon HD 3000) использовался свой толком так и недоделанный проприентарный API Close To Metal.
Что же касается игр, то в них толку от огромной теоретической математической мощи R600 было немного по нескольким причинам. Во-первых, в реальных игровых приложениях 100% эффективное использование VLIW-архитектуры было фантастикой. Во-вторых, в R600 имел место сильный дисбаланс между мощью шейдерного блока и блока текстурирования — на 320 потоковых процессоров приходилось всего (суммарно) 16 блоков адресации текстур и столько же блоков фильтрации. Для сравнения — в G80 на 128 потоковых процессоров приходилось 32 блока адресации текстур и 64 блока фильтрации. Указанный дисбаланс зачастую приводил к более низкой производительности R600 по сравнению с G80, особенно в "тяжёлых" режимах, например, режимах с включенной 16-кратной анизотропной фильтрацией. Наконец, в-третьих, инженерами ATI/AMD было принято странное решение отказаться от аппаратной реализации в ядре ускорителя алгоритма определения итогового цвета пикселя путём усреднения цветов всех соответствующих ему субпикселей при использовании мультисемплинга (MSAA). Эту часть процесса сделали программируемой и "сбросили" её выполнение на потоковые процессоры. С одной стороны такой подход был более гибким и позволял реализовывать свои собственные алгоритмы сглаживания, с другой — даже классический алгоритм MSAA отнимал очень много ресурсов потоковых процессоров, сводя на нет все преимущества от их большого числа. Особенно странным это решение выглядит на фоне наличия у R600 512-битной шины, которая при условии аппаратной реализации усреднения цвета субпикселей могла сделать MSАА очень дешёвым в плане использования ресурсов ускорителя.
Вообще используемая в R600 двунаправленная (512 бит на чтение и 512 бит на запись) кольцевая шина с восемью 64-битными каналами памяти чисто технически, конечно, до сих пор впечатляет.
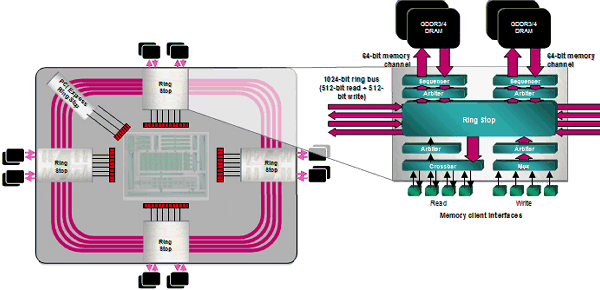
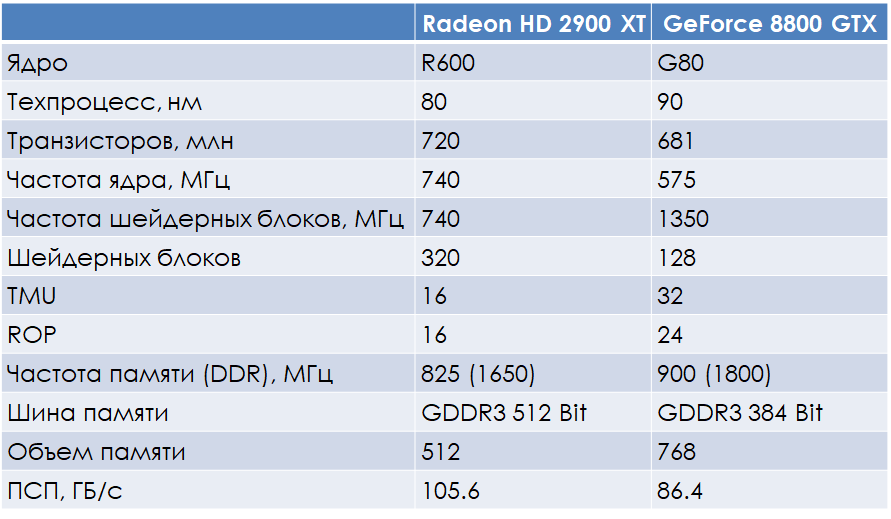
Даже при использовании сравнительно недорогой GDDR3-памятии на частоте 828 МГц такое решение обеспечивало пропускную способность в 105.6 ГБ/с, в то время как GeForce 8800 GTX с 384-битной шиной при использовании схожей GDDR3-памяти даже на более высокой частоте в 900 МГц демонстрировал куда более скромный результат пропускной способности, равный 86.4 ГБ/с. Добиваться цифр Radeon 2900 XT по пропускной способности можно было и с 384-битной шиной, что NVIDIA и сделала в GeForce 8800 Ultra, но для этого потребовалась гораздо более дорогая GDDR3-память, работавшая на частоте в 1080 МГц. Был, однако, у такой мощной шины и недостаток — столь сложная архитектура удорожала производство и без того недешёвого чипа.
Что ещё было примечательного в архитектуре? Пожалуй, можно отметить также программируемый аппаратный блок тесселяции, доставший R600 в наследство от графического процессора Xbox 360. Правда, аппаратная тесселяция не являлась частью требований Direct3D 10, а с требованиями Direct3D 11 эта реализация позже окажется несовместимой, так что пользы было не то чтобы много, но тем не менее.

В общем же технология повторила судьбу предыдущего проприетарного тесселятора ATI TruForm, будучи практически не использованным в игровой индустрии. Разве что были какие-то консольные порты с Xbox 360, в которых этот новый тесселятор хоть как-то использовался на практике, но крупных проектов я точно не припомню.
Краткое сравнение R600 и G80
Для целей сравнения архитектур первых унифицированных решений NVIDIA и ATI/AMD будет полезно свести их к некоторому "единому знаменателю", но прежде отметим, что в абсолютном большинстве случаев математические инструкции значительно преобладают над инструкциями ветвления, поэтому наличие блоков выполнения ветвлений можно во многих случаях игнорировать. Например, архитектуру TeraScale также нередко называют VLIW5-архитектурой, где 5 как раз и отражает факт наличия 5 математических вычислительных устройств в каждом потоковом процессоре. Безусловно, оснащение каждого блока SPU отдельным блоком выполнения ветвлений даёт R600 определённые преимущества над G80 — в целом шейдеры с большим числом переходов должны легче даваться именно R600. Разве что надо ещё принимать во внимание VLIW-архитектуру, которая может многое и здесь "подпортить", но, как минимум, статические переходы в большом количестве должны вызывать у R600 меньшие проблемы, чем у G80.
Как бы то ни было, и помимо ветвлений есть множество аспектов производительности, не сводимых к количеству потоковых процессоров и блоков текстурирования и растеризации — эффективность работы различных планировщиков, наличие и эффективное использование всевозможных кэшей, и много ещё чего, но в самом первом приближении будет достаточно взглянуть на следующую схему.
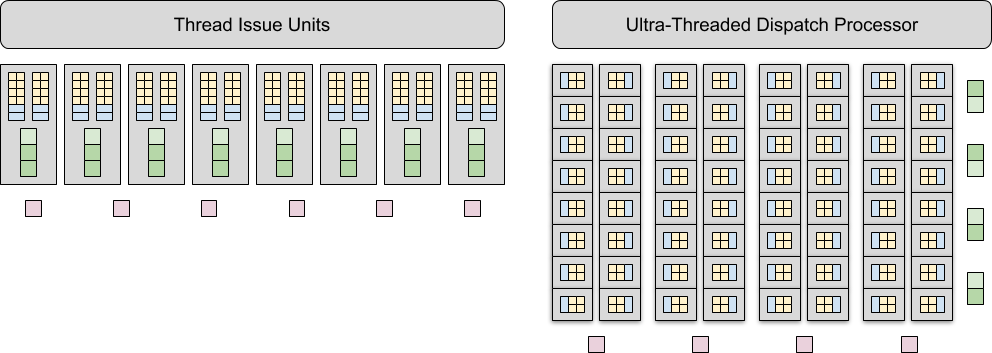 Упрощённые блок-схемы чипов G80 (слева) и R600 (справа)
Упрощённые блок-схемы чипов G80 (слева) и R600 (справа)
На схеме выше различные блоки графических процессоров G80 и R600 изображены следующим образом:
- Простые арифметические исполнительные устройства, способные выполнять 1 операцию MAD за такт — маленькие жёлтые квадраты.
- Более сложные устройства для вычисления значений трансцендентных функций и некоторых других задач — синие прямоугольники.
- Блоки адресации текстур — маленькие светло-зелёные квадраты, объединённые по 4 штуки в квадраты побольше.
- Блоки фильтрации текстур — маленькие тёмно-зелёные квадраты, также объединённые по 4 штуки в квадраты побольше.
- И, наконец, "широкие" блоки растеризации (способные обрабатывать по 4 пикселя) — большие фиолетовые квадраты.
-
Сразу бросается в глаза и уже упомянутая превосходящая конкурента (в теории) математическая мощь R600 (за счёт большего количества потоковых процессоров), и также обозначенный выше дисбаланс между этой мощью и возможностями блоком текстурирования и растеризации. Кроме того, не стоит забывать и о более высоких частотах работы потоковых процессоров в G80 — 1350 МГц против 743 МГц у R600, а также о меньшем КПД VLIW-архитектуры. В целом же, можно сказать, что основное различие между Tesla и TeraScale заключается в том, на каком уровне каким образом и насколько широко используется параллелизм. При этом обе архитектуры используют как параллелизм данных (data parallelism), так и параллелизм задач (task parallelism). Параллелизм данных реализован в рамках классического SIMD-подхода, когда одна инструкция выполняется одновременно несколькими потоковыми процессорами сразу над несколькими потоками в смысле пикселями, вершинами или примитивами, параллелизм задач подразумевает возможность выполнения нескольких различных потоков инструкций (шейдеров) на нескольких группах потоковых процессоров в рамках модели параллелизма на уровне потоков (thread-level parallelism, TLP). Ну а в микроархитектуре TeraScale используется ещё и параллелизм на уровне инструкций (instruction-level parallelism) в рамках VLIW-подхода.
В итоге, получается следующая картина: чип G80 способен обрабатывать 128 потоков (в смысле пикселей, вершин или примитивов) за такт, а R600 всего 64. Однако, потоковые процессоры G80 способны выполнять только одну инструкцию MAD за такт над потоком, а потоковые процессоры R600 — до 5 таких инструкций, если только они независимы друг от друга. Таким образом, в наилучшем для R600 случае (все 5 инструкций независимы друг от друга) этот чип способен выполнять 320 инструкций за такт, а в худшем (5 зависимых инструкций) — всего 64. Получается, что G80 способен выполнить 128 × 1.35 = 172.8 миллиардов инструкций MAD в секунду, а R600 — 64 × 0.743 = 47.5 и 320 × 0.743 = 237.8 миллиардов инструкций MAD в секунду в худшем и лучшем случаях, соответственно. То есть, в теории, чип R600 может быть в лучшем случае быстрее G80 почти на 40%, а в худшем — медленнее более чем на 70%.
Карта
 HD 2900 XT на своём законном месте — позади 8800 GTX.
HD 2900 XT на своём законном месте — позади 8800 GTX.
За качественными фотографиями карты вновь отсылаю к обзорам прошлых лет, благо дизайн и платы, и системы охлаждения у практически всех без исключения HD 2900 XT был референсный. Отличия заключались лишь в наклейках на пластиковом кожухе системы охлаждения. К нам на экзекуцию, например, попала карточка от Palit с изображением какой-то воинственного вида кибер-лягушки. В референсном варианте на красный пластиковый кожух были нанесены серебристые языки пламени, что, среди прочего, вполне прозрачно намекало, что холодной карта не будет. :D

HD 2900 XT чуть короче 8800 GTX, но смотрится также массивно, да и в общем настолько же тяжёлой и является. Печатная плата красного цвета, как и почти полностью её накрывающий прозрачный пластиковый кожух. И вот тут не знаю, то ли я пал жертвой синдрома "раньше и трава была зеленее", то ли дизайн в красном цвет действительно так хорош, то ли сказалась усталость от чёрно-белого дизайна последних лет, то ли всё это вместе взятое и ещё что, но я прямо в восторге от внешнего вида HD 2900 XT. Дайте нам красных, зелёных, синих, да каких угодно карт в 2020! Осточертел уже этот массовый чёрно-белый "дизайн", в лучшем случае разбавленный неуместными РГБ-гирляндами. Но не будем о больном, а продолжим изучать карту. В правом верхнем углу на фото выше видно наличие двух разъемов для дополнительного питания: одного 6-контактного и одного 8-контактный. Если мне не изменяет память, это была первая видеокарта с 8-контакным разъёмом, что создавало определённые трудности. Например, в 8-контактную колодку можно было воткнуть просто ещё один обычный 6-контактный разъем, и карта прекрасно работало в номинальном режиме, но разгон в таком случае был заблокирован на программном уровне. Переходник с 6- на 8-контактов в тот момент был большой редкостью, так что если его не положили, спасало замыкание двух контактов, остававшихся свободными при использовании двух 6-контакных кабелей или использование для разгона сторонних утилит.
С обратной стороны карты имеется металлический бекплейт, который придаёт конструкции дополнительную жёсткость, плюс через термопрокладки отводит тепло от микросхем памяти, расположенных на задней стороне, да ещё и защищает многочисленные мелкие электронные компоненты от повреждений.

В основе системы охлаждения лежит медный радиатор, закрытый пластиковым кожухом сверху и металлической пластиной (своего рода "фронтплейтом") снизу, на которой, как и на бекплейте, имеются термопрокладки для контакта с микросхемами памяти.

Микросхемы производства компании Hynix расположены с обеих сторон платы, как уже было сказано выше. Маркировка чипов — HY5RS573225A FP-1, а их номинальное время доступа равно 1.0 нс (2000 МГц теоретической частоты). Медный радиатор состоит из основания, выходящих из него 3 тепловых трубок и ребёр, плотно набранных на трубках. Охлаждается радиатор небольшой и шумной при 3D-нагрузках турбиной. При этом шумит турбина прилично даже на невысоких оборотах по умолчанию, при которых температура в нагрузках слегка переваливает за 80 °C.

Можно, конечно, выкрутить обороты турбины и сбить несколько градусов, вот только чем быстрее крутится турбина, тем отчётливее видеокарта начинает напоминать ярко-красный болид Ferrari из королевских гонок не только внешне, но и по звуковому сопровождению. Ну а на полных оборотах это уже, скорее, реактивный самолёт, проносящийся мимо. Так что если сравнивать c GeForce 8800 GTX, то Radeon HD 2900 XT можно назвать, скорее, громкой, чем горячей — температурный режим примерно одинаковый, а вот шума от карты ATI/AMD заметно больше.
Тесты
Unigine Tropics
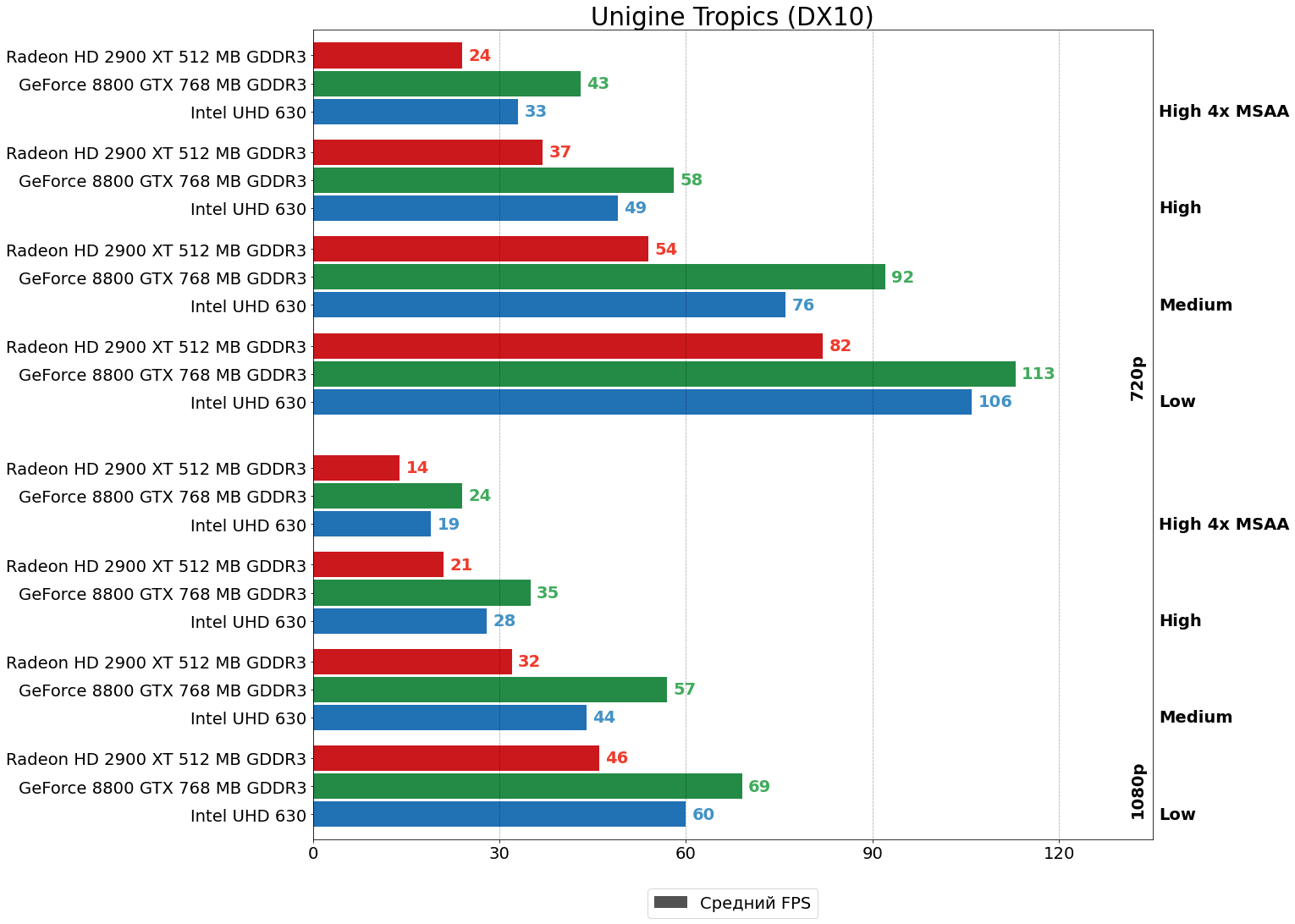
Тотальный разгром "красной" карты — преимущество 8800 GTX над HD 2900 XT в бенчмарке от наших соотечественников составляет 35–75% в HD-разрешении и 50–80% в FHD. Максимальный разрыв наблюдается на средних настройках и высоких настройках со сглаживанием. Но отчаиваться пока рано — это всё-таки "синтетика", причём, как мы уже видели ранее, не всегда точно отображающая реальную картину игровой производительности.
3DMark Vantage
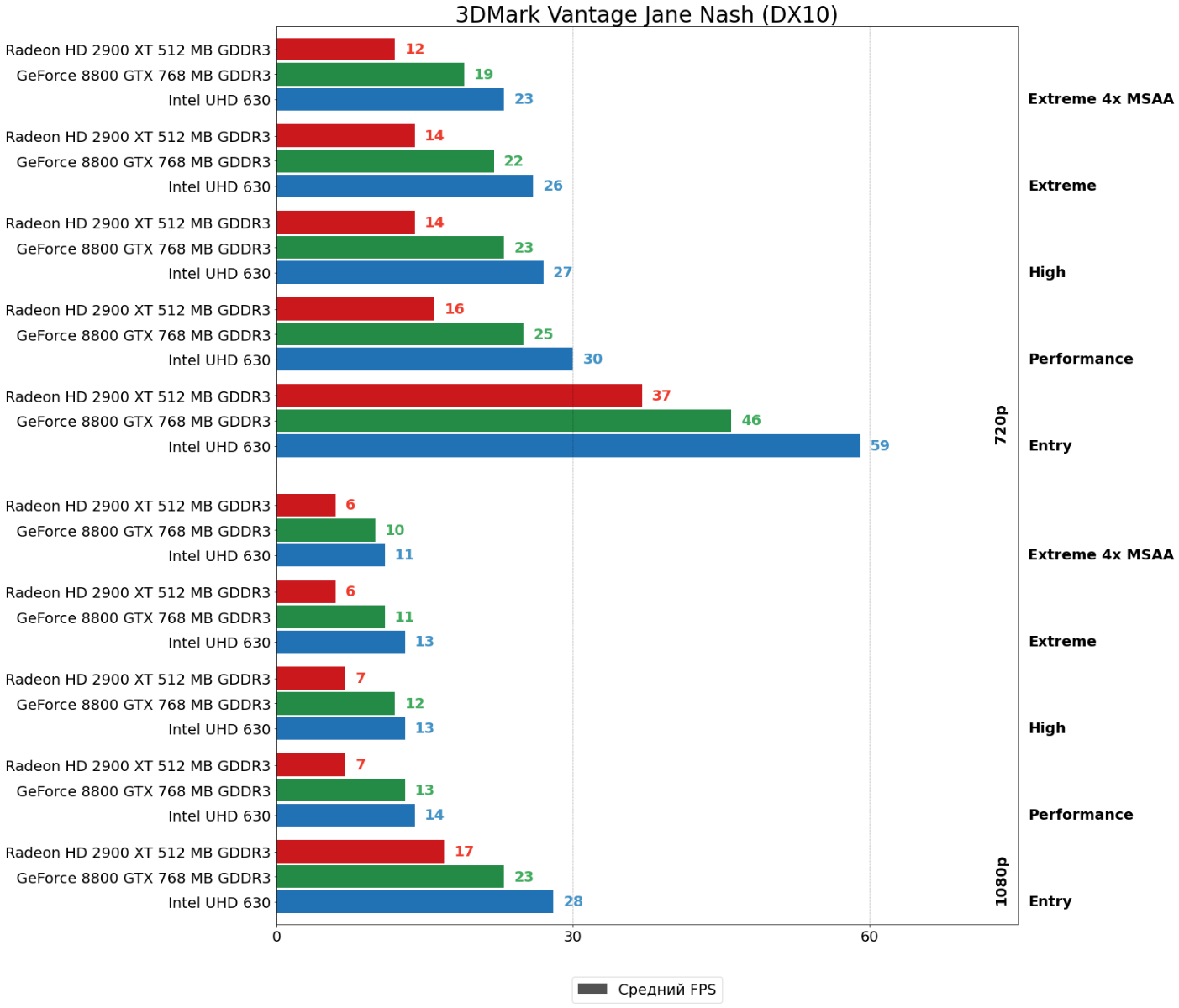
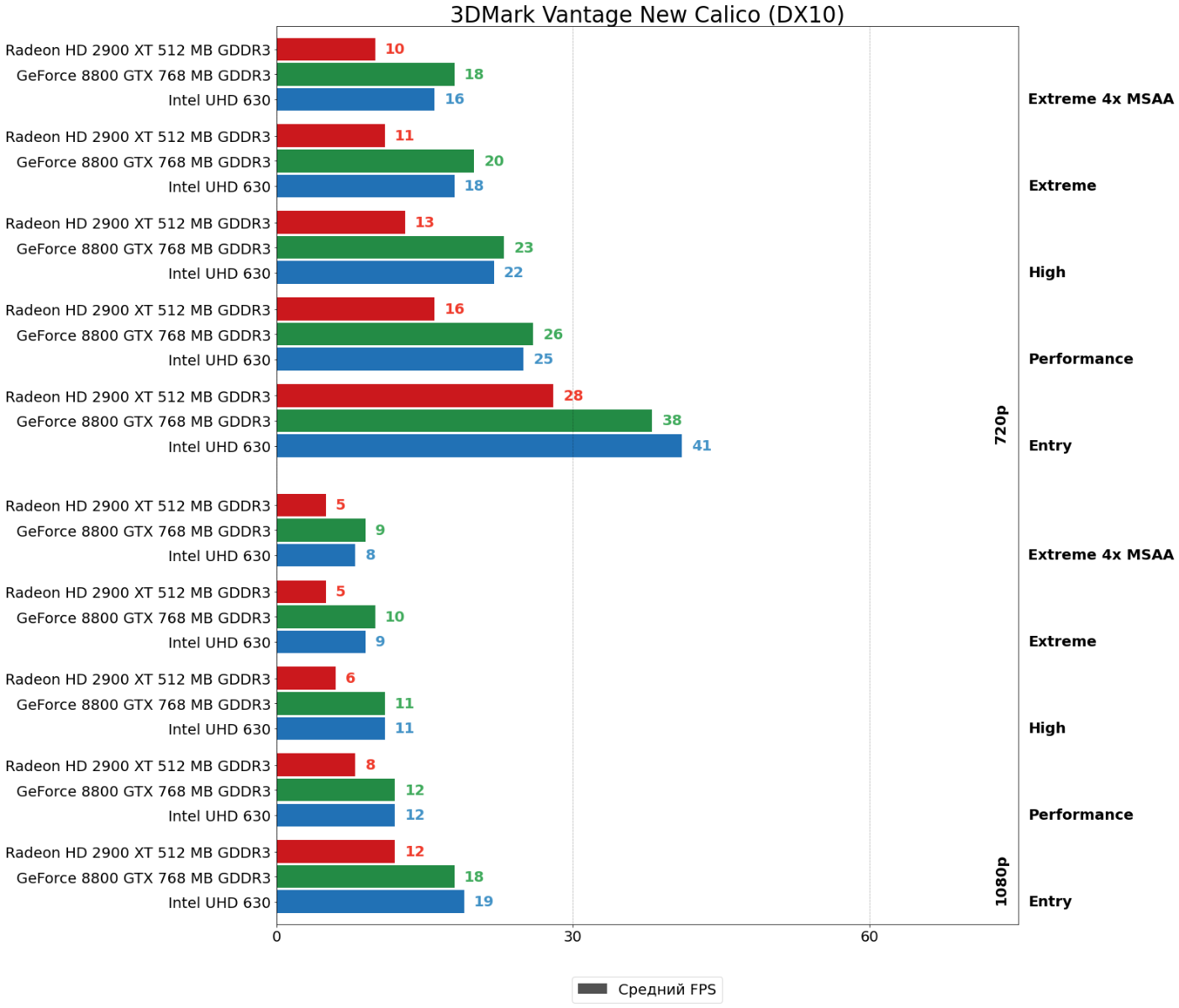
Оба теста 3DMark Vantage, впрочем, демонстрируют туже плачевную для HD 2900 XT картину — 8800 GTX отрывается от ускорителя AMD на внушительные 40–100%!
3DMark Cloud Gate
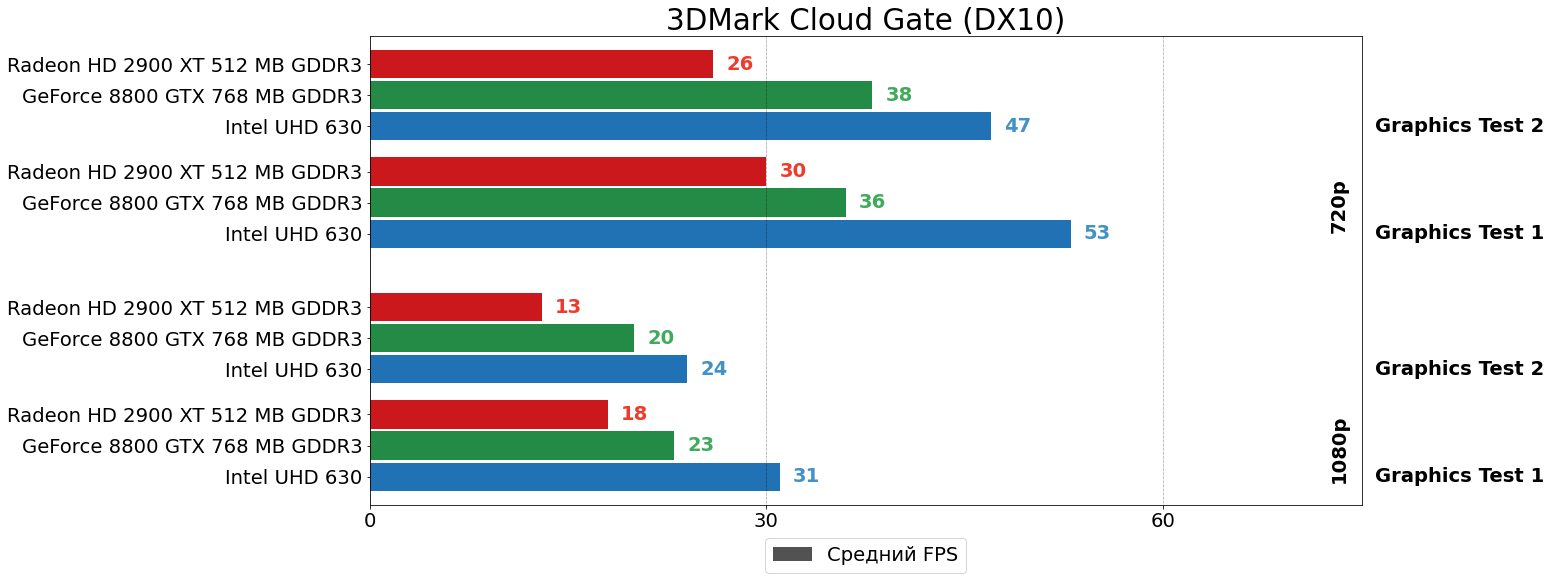
И, наконец, тест Cloud Gate из актуальной версии пакета 3DMark также солидарен с коллегами по цеху, впрочем, цифры превосходства 8800 GTX над HD 2900 XT здесь скромнее — 20–45% в разрешении HD и 30–60% в FHD. Но да хватит уже синтетических тестов, давайте лучше уже посмотрим наконец, насколько всё плохо будет в играх и будет ли?
Call of Juarez (Chrome Engine 3, 2007)

Так-так, что это тут у нас? В первой же игре результаты совершенно не похожу на таковые в синтетических тестах — HD 2900 XT, конечно, по-прежнему отстаёт от 8800 GTX, но отставание составляет максимум 20% за исключением разве что показателя 1-ого процентиля FPS в режиме со сглаживанием, по которому "красная" уступает уже 40%. Но в целом, в Call of Juarez дела у HD 2900 XT на фоне 8800 GTX обстоят значительно лучше, правда обольщаться не стоит, ведь эту игру NVIDIA не раз публично обвиняла в различных умышленных пессимизациях производительности специально "под" свои карты. Так что, возможно, в Call of Juarez не у HD 2900 XT дела обстоят хорошо, а у 8800 GTX плохо.
Crysis (CryEngine 2, 2007)
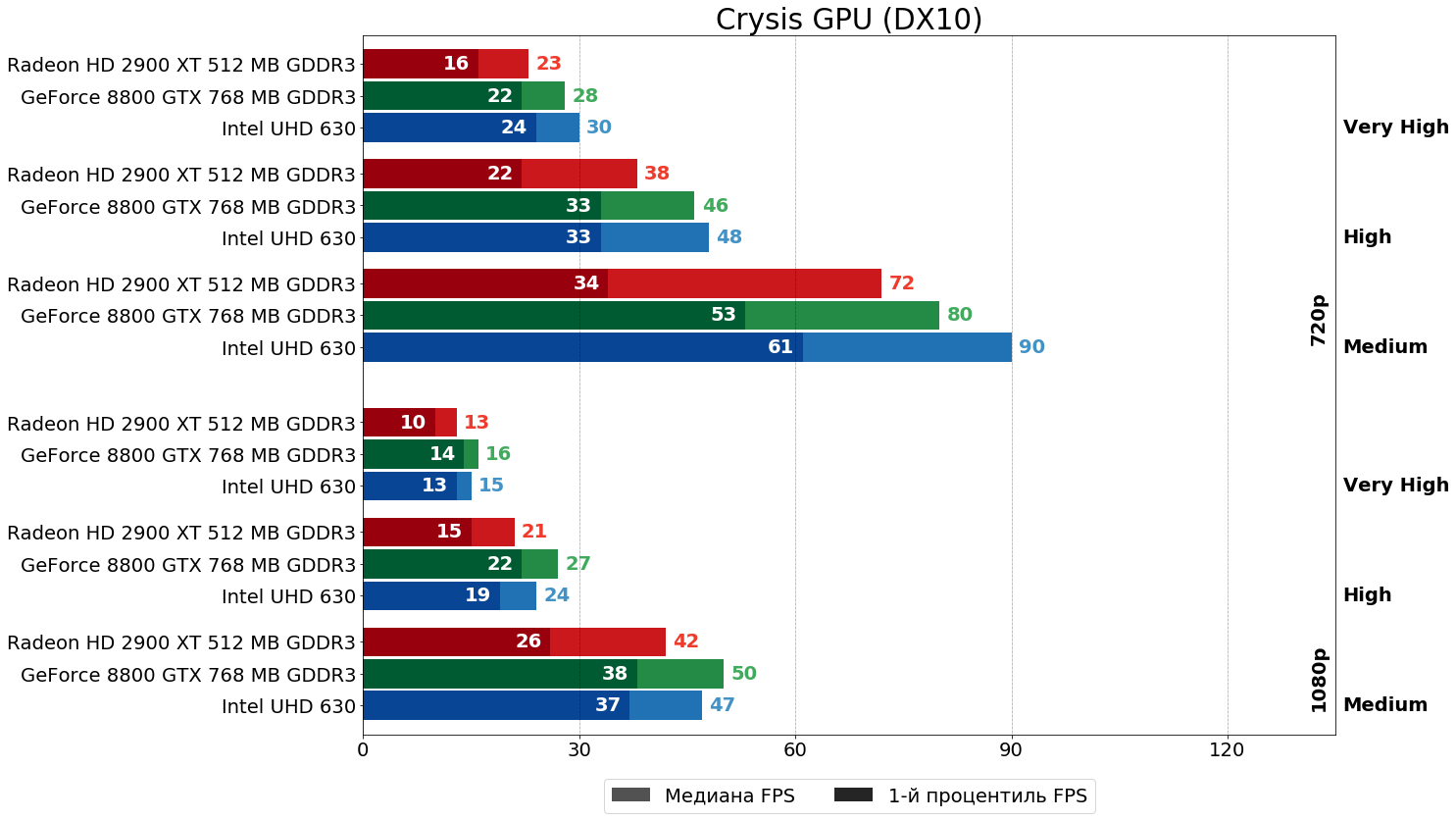
И уже в следующей игре отставание HD 2900 XT от 8800 GTX существеннее — 10–30% проигрыша по средним показателям и 40–50% по минимальным.
Far Cry 2 (Dunia Engine, 2008)
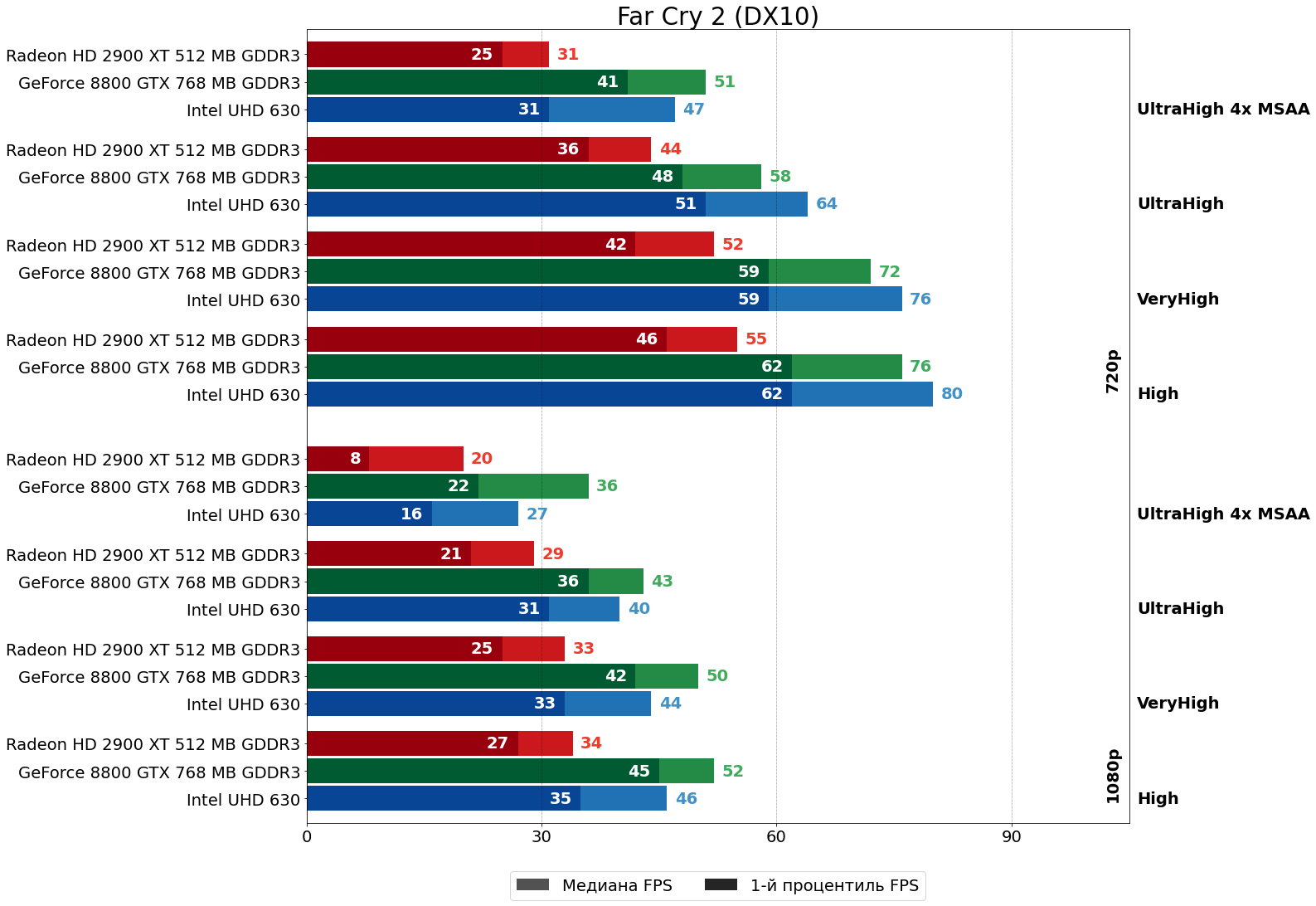
В Far Cry 2 дела у HD 2900 XT обстоят совсем плохо — превосходство 8800 GTX составляет 30–40% и 50–70% в HD и FHD, соответственно. И это без сглаживания MSAA, включение которого уже просто отправляет "красную" карту в низшую лигу — 65–70% отставания от 8800 GTX в HD и 80–70% в FHD.
S.T.A.L.K.E.R. Call of Pripyat (X-Ray Engine 1.6, 2009)
 В/на Зоне дела у HD 2900 XT в целом ещё хуже — 8800 GTX убегает вперёд на 30–120% в HD-разрешении и 40–100% в FHD. Получается, права была NVIDIA, обвинявшая поляков из Techland в умышленном "притормаживании" своих видеокарт в Call of Juarez? Или права была-таки AMD, многократно утверждавшая, что в DirectX 10 играх у её карт всё плохо, так как игры поголовно оптимизированы под архитектуру графических решений конкурента? Кстати говоря, если даже дело было и так, как утверждала AMD, то винить в сложившейся ситуации никого кроме самой себя компания не могла — а чего, собственно, в AMD ждали, отстав с выпуском своих DirectX 10 ускорителей от конкурента на целых пол года? Что разработчики игр будут непонятно сколько сидеть без дела, пока AMD не соизволит "выкатить" свои карты? Но давайте всё-таки двигаться дальше.
В/на Зоне дела у HD 2900 XT в целом ещё хуже — 8800 GTX убегает вперёд на 30–120% в HD-разрешении и 40–100% в FHD. Получается, права была NVIDIA, обвинявшая поляков из Techland в умышленном "притормаживании" своих видеокарт в Call of Juarez? Или права была-таки AMD, многократно утверждавшая, что в DirectX 10 играх у её карт всё плохо, так как игры поголовно оптимизированы под архитектуру графических решений конкурента? Кстати говоря, если даже дело было и так, как утверждала AMD, то винить в сложившейся ситуации никого кроме самой себя компания не могла — а чего, собственно, в AMD ждали, отстав с выпуском своих DirectX 10 ускорителей от конкурента на целых пол года? Что разработчики игр будут непонятно сколько сидеть без дела, пока AMD не соизволит "выкатить" свои карты? Но давайте всё-таки двигаться дальше.
А дальше у нас будут игры уже "под" DirectX 11, поддерживающие DirectX 10 ускорители за счёт концепции уровней поддержки, о которой было рассказано в предыдущей статье. И тут у нас, кстати говоря, появляется интересная возможность проверить вышеупомянутый тезис AMD о тотальной оптимизации игр поколения DirectX 10 под решения NVIDIA. Всё дело в том, что в момент выхода следующей 11-ой версии API DirectX, AMD и NVIDIA поменялись ролями — теперь уже AMD первой выпустит очень сильные карты (Radeon HD 5000), а NVIDIA расслабившись за пару лет, окажется совершенно не готовой к серийному производству ускорителей с поддержкой этого API (GeForce 400). Так что уж для новых DirectX 11 играх тотальные обвинения AMD в оптимизации всего и вся под решения конкурента точно не пройдут. Здесь уж если кому и жаловаться, так это NVIDIA, но опять же, виновата в первую очередь компания, задерживающая выход на рынок своих ускорителей, а не разработчики игр, оптимизирующие под то, что уже есть "здесь и сейчас".
Metro 2033 (4A Engine, 2010)
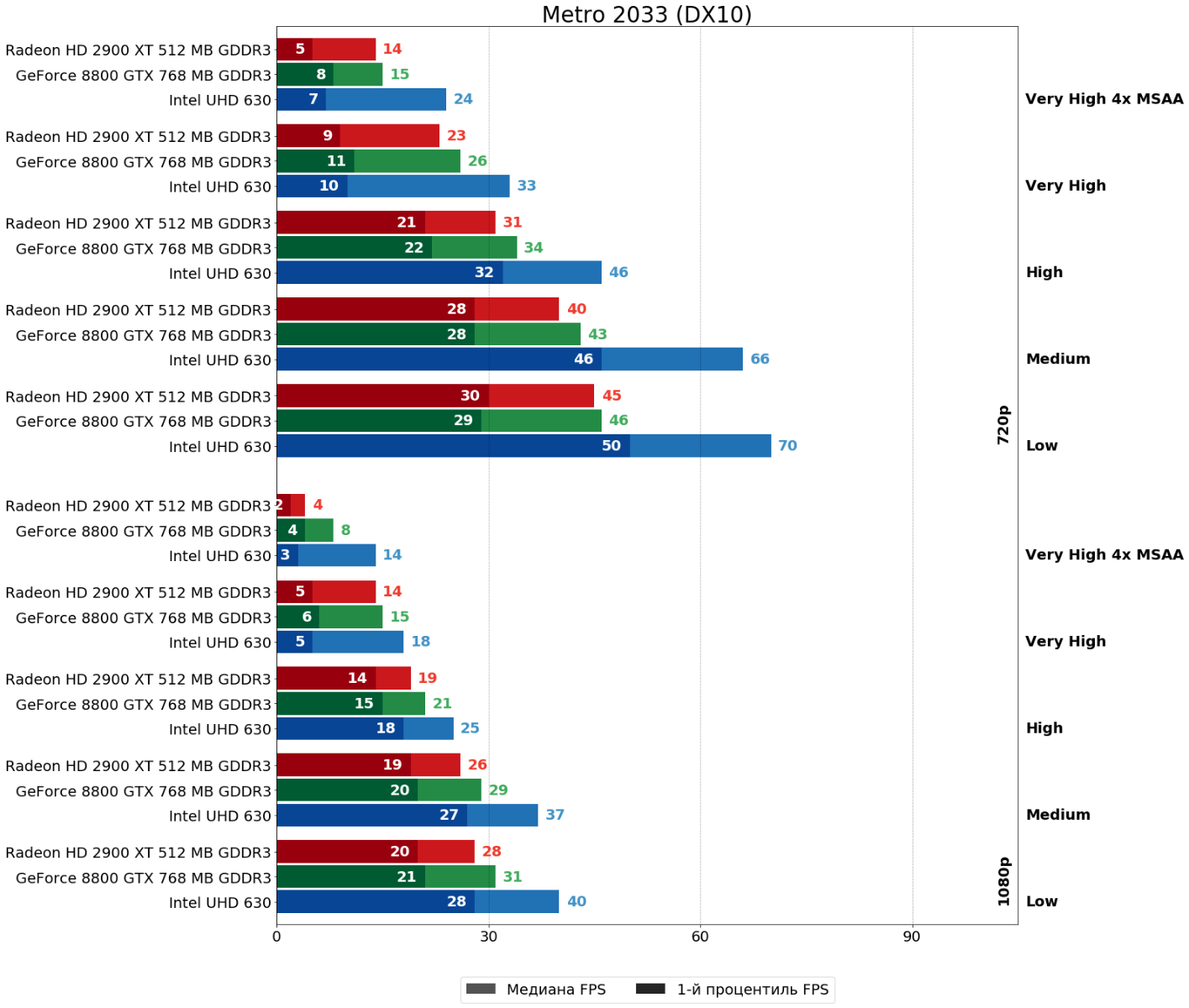 В оригинальной Metro 2033 всё действительно намного лучше — 8800 GTX всё ещё впереди, но всего на 10–15%. Исключение — очень высокие настройки со сглаживанием в FHD, где 8800 GTX быстрее вдвое, правда, толку с этого с практической точки зрения ровно ноль, так как FPS и там, и там неиграбельный. NVIDIA Advanced PhysX, естественно, был отключен, чтобы не давать картам NVIDIA незаслуженного преимущества.
В оригинальной Metro 2033 всё действительно намного лучше — 8800 GTX всё ещё впереди, но всего на 10–15%. Исключение — очень высокие настройки со сглаживанием в FHD, где 8800 GTX быстрее вдвое, правда, толку с этого с практической точки зрения ровно ноль, так как FPS и там, и там неиграбельный. NVIDIA Advanced PhysX, естественно, был отключен, чтобы не давать картам NVIDIA незаслуженного преимущества.
Total War Shogun 2 (TW Engine 3, 2011)
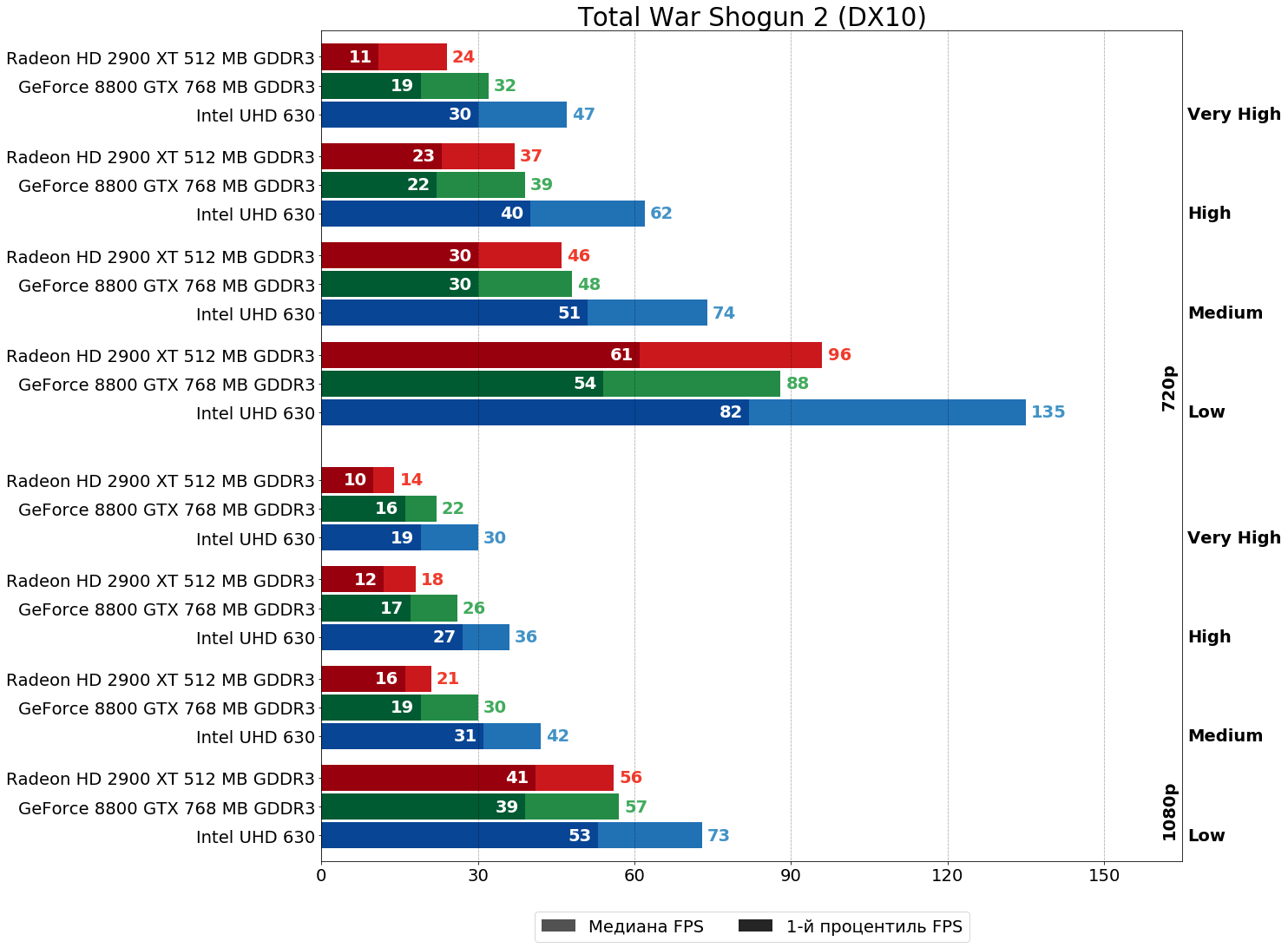
В Total War Shogun 2 ускорителю HD 2900 XT вообще удаётся местами вырваться вперёд, пускай и незначительно — в HD-разрешении за исключением очень высоких настроек победа за "красной" картой. На очень высоких и в FHD за исключением низких настроек впереди уже вновь ускоритель NVIDIA — всё-таки блоков ROP и TMU в R600 положили маловато, это уже совершенно очевидно.
Sniper Elite V2 (Asura Eingine, 2012)
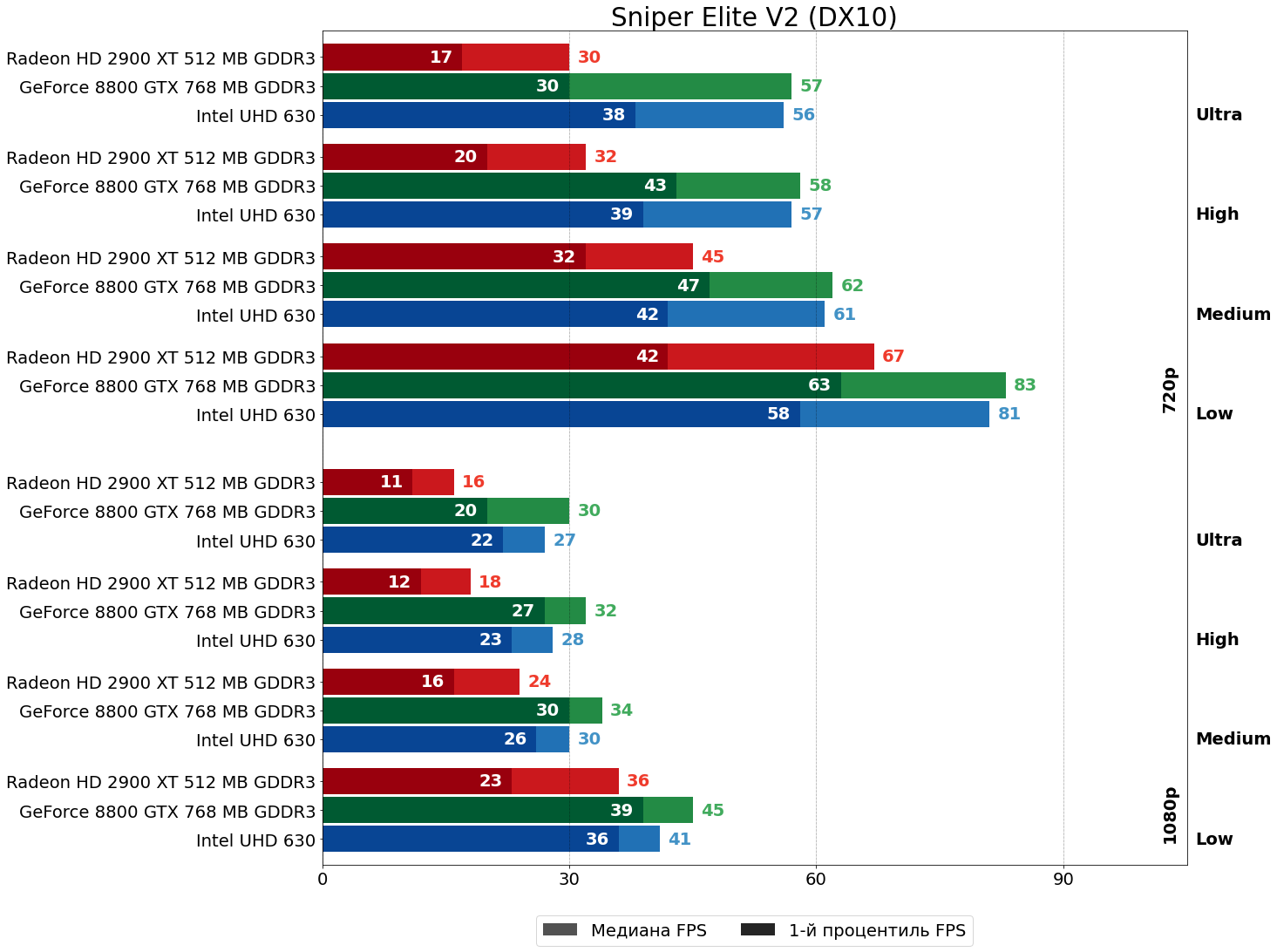
А вот во второй части Sniper Elite всё вновь очень плохо для HD 2900 XT — преимущество 8800 GTX огромно, в некоторых режимах более чем двукратное.
Hitman Absolution (Glacier 2, 2012)
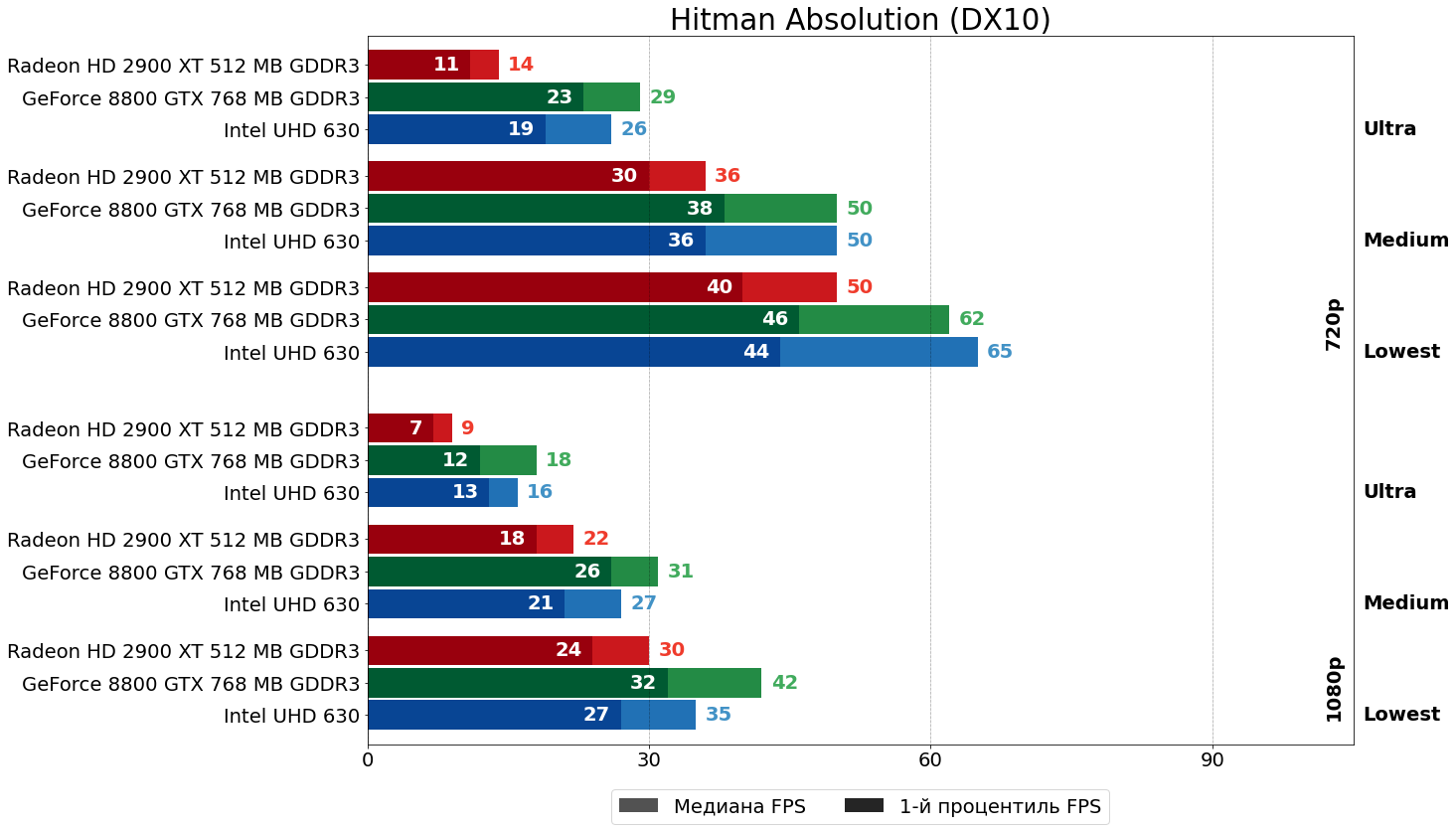
Такая же удручающая для "красной" карты картина и в Hitman Absolution — большой отрыв 8800 GTX от конкурента, вплоть до более чем двукратного на ультра-настройках.
BioShock Infinite (Unreal Engine 3, 2013)
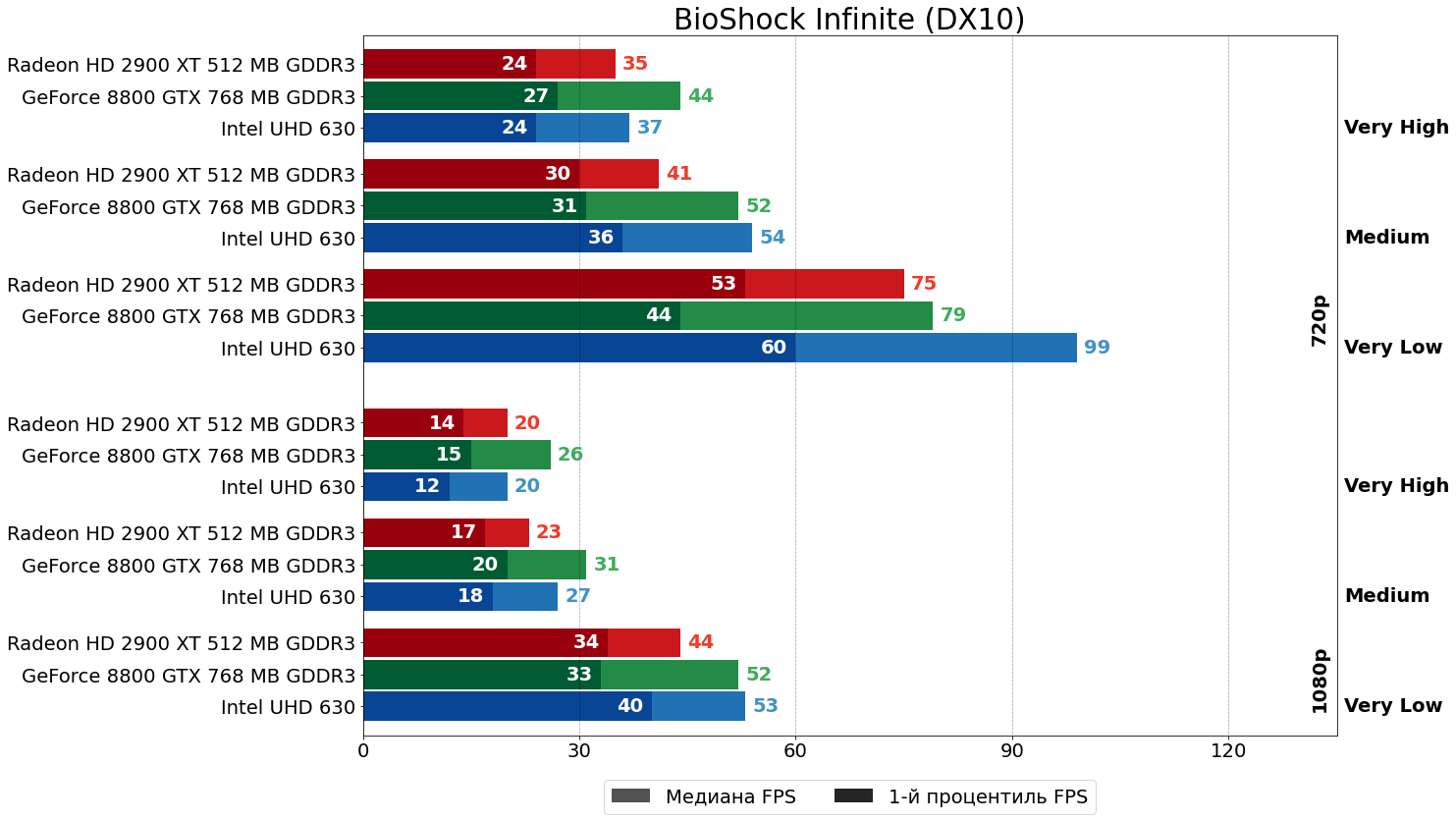
А вот BioShock Infinite к HD 2900 XT на фоне предыдущей пары игр крайне лоялен: 20–30% отрыв 8800 GTX от конкурента — ни разу не приговор.
Tomb Raider (Crystal Engine, 2013)
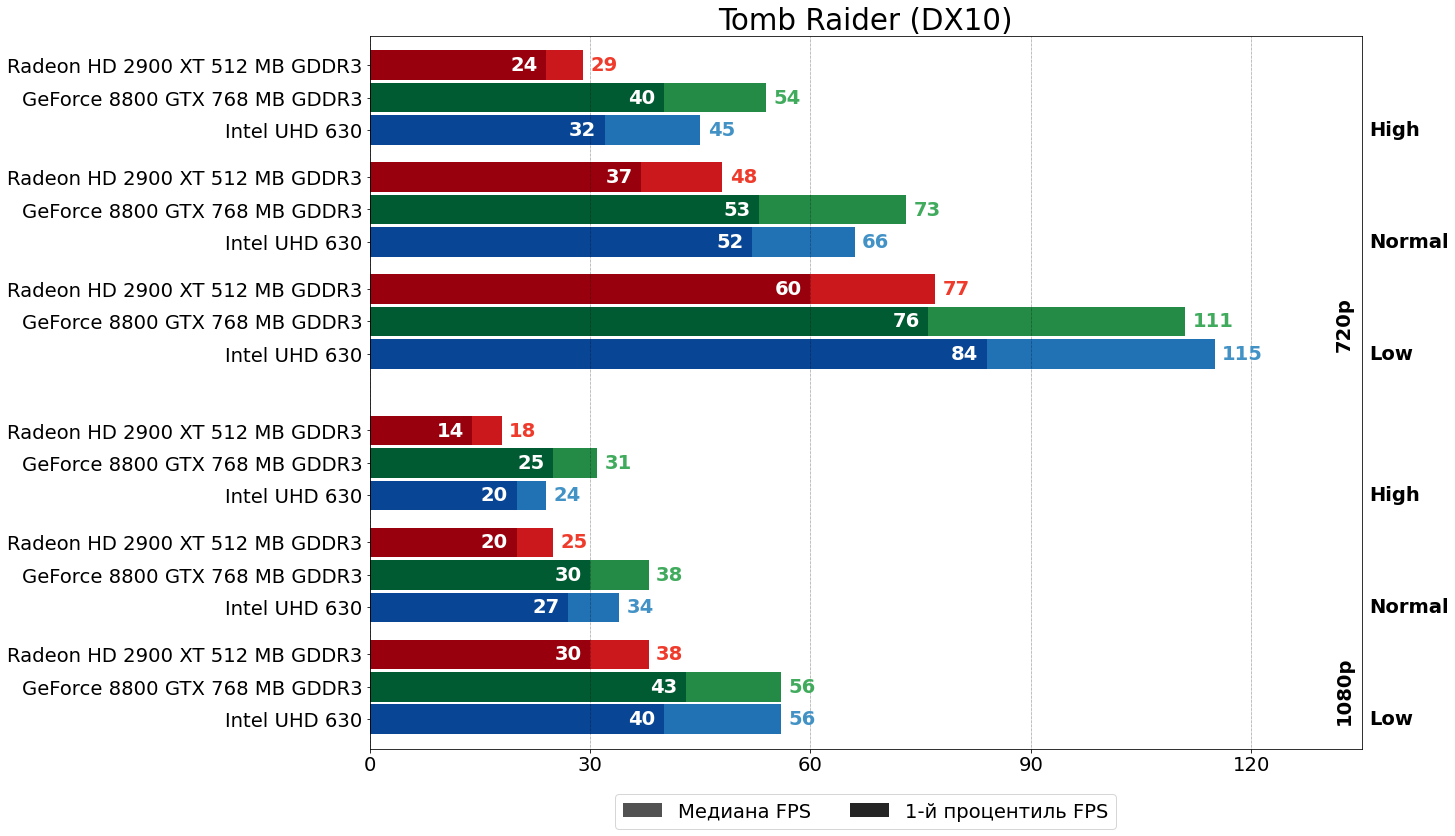
А вот мисс Крофт, напротив, вполне однозначна в своих предпочтениях — 8800 GTX вновь впереди на внушительные 30–90%.
F1 2014 (EGO Engine, 2014)

Королевские гонки от Codemasters всё выглядит неплохо для HD 2900 XT (всего 10–25% отставания от 8800 GTX) вплоть до ультра-настроек в FHD-разрешении, где преимущество 8800 GTX по минимальным показателям резко возрастает до трёхкратного. Включение сглаживания в такой ситуации окончательно приговаривает HD 2900 XT.
Grand Theft Auto V (RAGE, 2015)
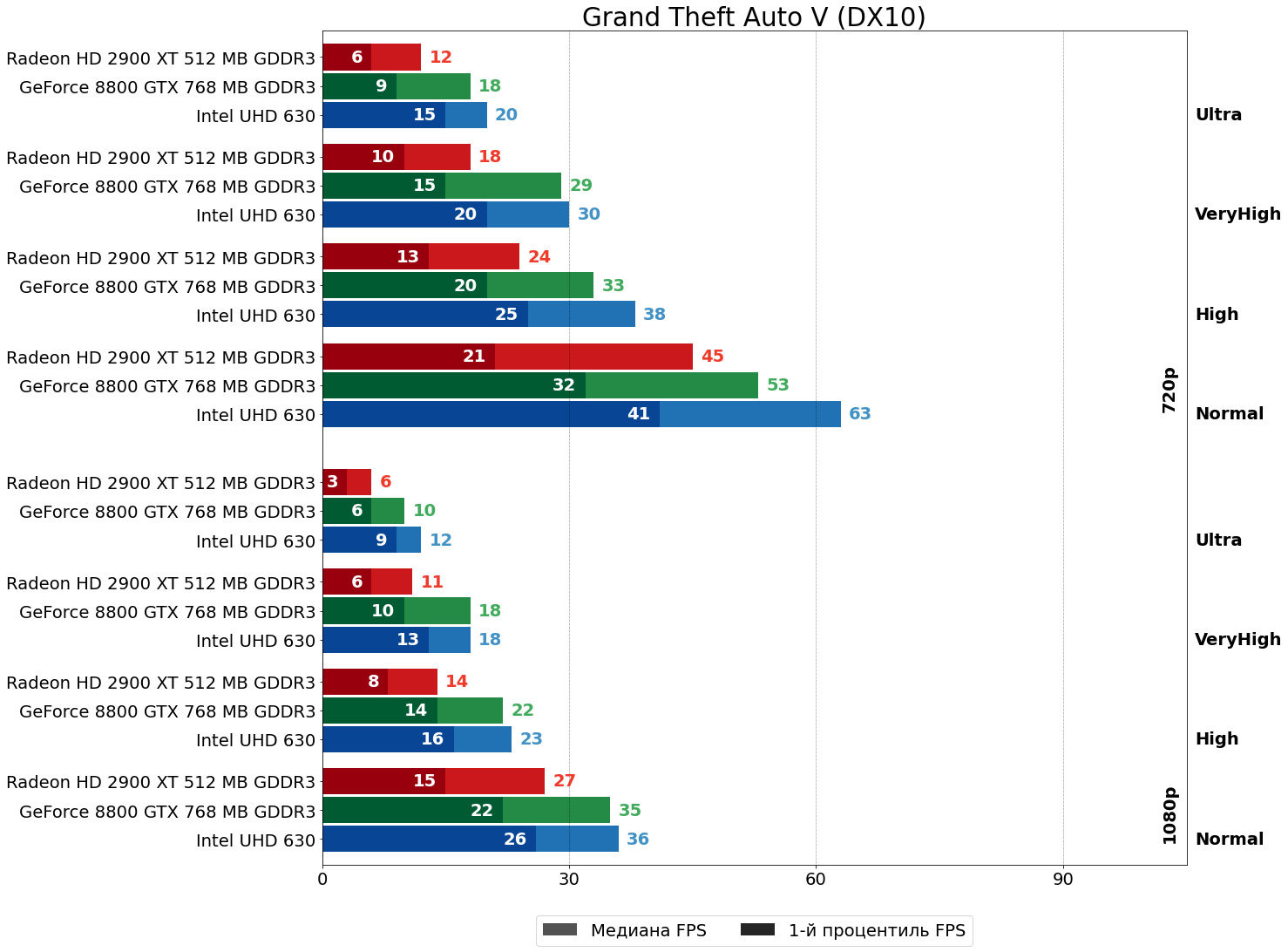
И, наконец, GTA V также симпатизирует карте NVIDIA — в HD-разрешении 8800 GTX впереди на 20–50%, а в FHD уже на 30–120%. Получается, в целом, что и в более поздних играх, за некоторыми исключениями, ускоритель NVIDIA показывает себя значительно лучше решения AMD, так что вряд ли в эпоху DirectX дело было в поголовной оптимизации игр под "зелёные" карты, архитектуры TeraScale у ATI/AMD просто вышла послабее Tesla от NVIDIA.
Среднегеометрические результаты и выводы
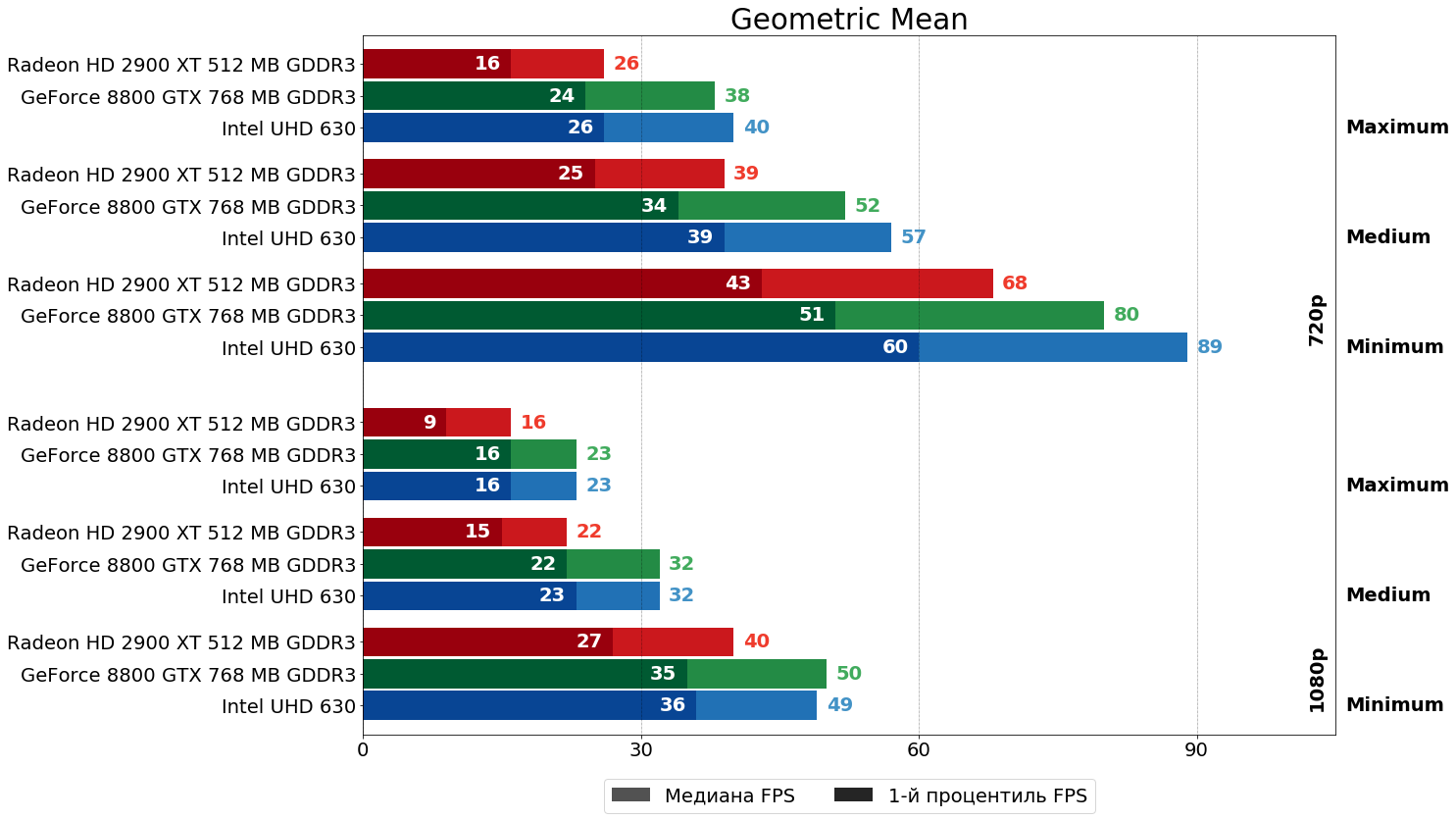
Пришло время поговорить о средних показателях и сделать выводы. По набору из 12 игровых проектов превосходство 8800 GTX над HD 2900 XT составило от 20% до 50% в HD-разрешении и от 25% до 80% в FHD-разрешении, причём отрыв растёт при движении от низких настроек к высоким. Напомню, что по нашим прикидкам из теоретической части чип R600 может быть в лучшем случае быстрее G80 почти на 40%, а в худшем — медленнее более чем на 70%, так что на практике, как видим, чаще реализуется сценарий близкий к худшему для R600.
Кроме того, в этот раз в 5 игровых проектах в дополнение к ультра-настройкам был также протестирован режим ультра-настроек со сглаживанием 4x MSAA. В среднем по 5 таким игровым тестам получается следующая картина влияния сглаживания MSAA на производительность.
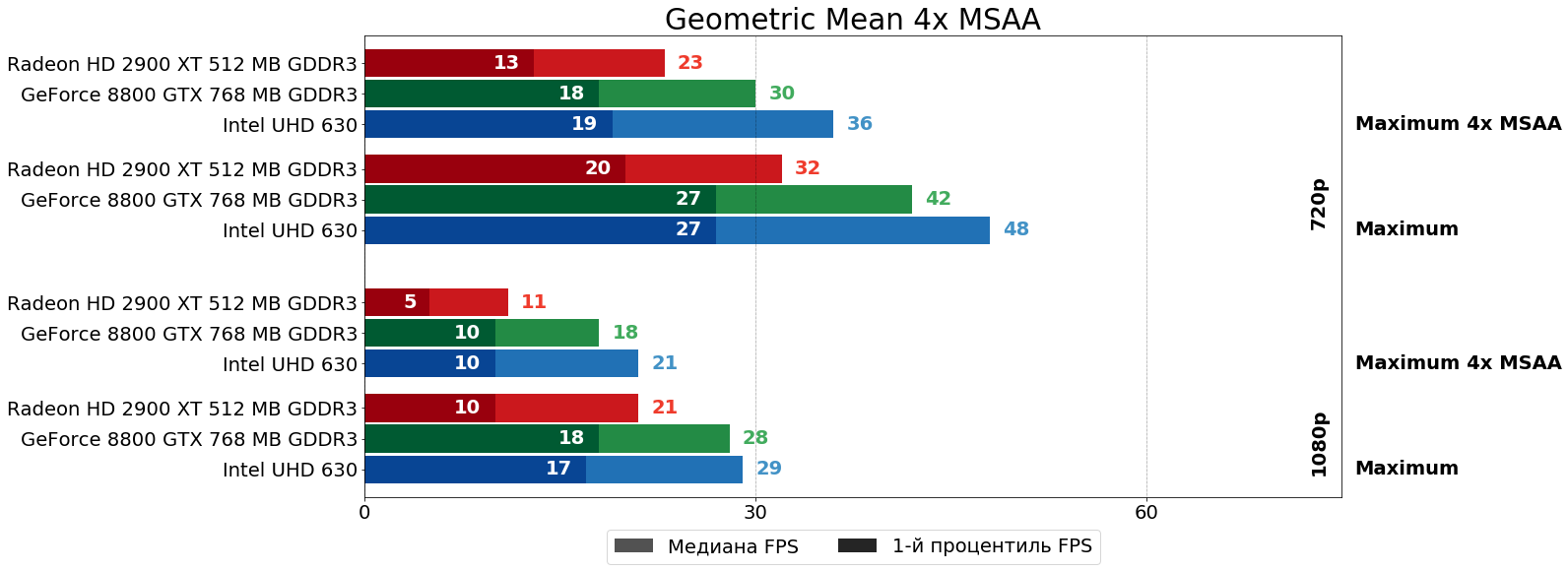
Можно видеть, что и так существенное отставание HD 2900 XT от 8800 GTX в самом "тяжёлом" графическом режиме (на максимальных настройках в FHD-разрешении), ещё больше усугубляется включением сглаживания MSAA — после активации 4x MSAA отставание "красной" карты по среднему и минимальному показателям увеличивается с 33% и 80% до 64% и 100%, соответственно. В HD-разрешении существенного роста указанных показателей не наблюдается, так как, по всей видимости, шейдерной мощи у R600 одновременно для выполнения и кода шейдеров, и заключительных этапов 4x MSAA здесь ещё хватает. Отметим также, что "встройка" Intel при включении MSAA не "просела гораздо сильнее", чем 8800 GTX, как писалось в комментарии к предыдущей статье, а даже отчасти наоборот немного увеличила свой отрыв от 8800 GTX. Возможно, "встройка встройке — рознь" и Gen9.5 уже не так плохо справляется с MSAA.
Если же вернуться к Radeon HD 2900 XT, то, как мы уже неоднократно отмечали, этот первый для ATI/AMD 3D-ускоритель, основанный на унифицированной шейдерной архитектуре и ориентированный на рынок ПК оказался значительно слабее решения конкурента NVIDIA. Конечно, всё это было прекрасно известно уже в момент выхода Radeon HD 2900 XT на рынок — отсюда и позиционирование карты как конкурента "урезанной" GeForce 8800 GTS, а не полноценной GeForce 8800 GTX. Однако, определённые надежды и сама компания AMD, и её верные поклонники возлагали на оптимизацию драйверов, которая должна была со временем поднять КПД VLIW-архитектуры, а также на смещение акцента игровых проектов в вычисления, что максимально раскрыло бы сильные стороны архитектуры TeraScale. Но не случилось. Причём, не случилось, по всей видимости, ни того, ни другого, ни чего-бы то ни было ещё, что позволило бы Radeon HD 2900 XT хоть сколь-нибудь нагнать GeForce 8800 GTX — и в более поздних проектах за редкими исключениями "красная" карта отстаёт от "зеленой", причём в целом также существенно, как и на старте.
Основные источники информации
- [overclockers.ru] На полгода позже, на 20-мм короче, на 25% медленнее и на 40% дешевле: блиц-тест AMD Radeon HD 2900 XT
- [overclockers.ru] О Radeon HD 2900 XT 512 Mb без эмоций: тесты против GeForce 8800 GTS 640 Mb
- [overclockers.ua] Radeon HD 2900 XT – новый флагман от AMD
- [iXBT.com] Долгожданный ответ AMD/ATI в виде целого семейства DirectX 10 ускорителей, в том числе и RADEON HD 2900 XT (R600). Часть 1, 2, 3, 4.
- [ferra.ru] Свершилось! Архитектура Radeon HD 2000 – достойный ответ конкуренту
- [ferra.ru] Тестирование Radeon HD 2900XT: у них получилось!
- [Beyond3D] AMD R600 Architecture and GPU Analysis
- [AnandTech] ATI Radeon HD 2900 XT: Calling a Spade a Spade
Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.