
Производительность подсистемы памяти
Эта статья была прислана на наш второй конкурс.
Меня всегда интересовал вопрос производительности всей системы памяти, но были несколько другие задачи и этот вопрос так и висел в воздухе. Все бы и заглохло, да не так давно пришлось ускорить компьютер заменой процессора Athlon с T-bird 990MHz на T-bred 1800Mhz (XP2200+) и ... как-то "не особенно". Обычные тесты показывали существенное ускорение, а реальные игры ... Сразу скажу, моя mainboard процессоры T-bred принципиально не поддерживает и пришлось править BIOS, так что были возможны любые казусы. Хороший способ разобраться - разложить все по полочкам и попробовать найти узкое место.
Условно говоря, процессорную часть компьютера можно разделить на:
- целочисленную арифметику и логику. Это классическая часть 80x86 процессора.
- арифметику с плавающей точкой. За это отвечает один и больше блоков FPU в процессоре.
- арифметико-логические расширения - MMX, SSE, 3Dnow! и т.д.
- подсистема памяти. Сюда можно включить блок ввода-вывода процессора, канал межпроцессорного обмена и контроллер памяти с самими модулями памяти.
- система кеширования, состоящая из кешей нескольких уровней (обычно первого и второго уровня) и поддержку кеширования в процессоре.
Я умышленно разделил этот и предыдущий пункт. Кеширование операции чтения (спекулятивное чтение) не может ускорить доступ к внешней памяти выше того, что может сама подсистема памяти, оно убирает паузы в обмене. Кеширование записи (отложенная запись) может несколько замаскировать время операции записи при том условии, что эти операции будут редки. Отложенная запись называется так потому, что сама операция физической записи в внешнюю память может быть отложена на некоторое время и выполниться позже. Данные на запись временно сохраняются в cache. Причем, в выполняемую программу сразу посылается признак о завершении операции записи. Это позволяет программе не тратить время на ожидание завершения операции ввода-вывода.
При постоянной записи или, что еще хуже, переписывании, кеширование записи только затормаживает процесс. Причем, чтение по случайным адресам вообще невозможно ускорить кешированием, в отличии от записи, которая может выполняться в то время, когда контроллер памяти будет не слишком занят. Т.о., если программа не часто записывает, то сами операции записи в память выполняются прозрачно, не останавливая процессор для ожидания окончания операции ввода-вывода. Проблемы возникают, когда программа начинает записывать слишком часто - отложенная запись съедает места в cache и подсистема памяти не знает, когда оптимальней перейти от незаметной к постоянной записи, что уже никак не будет невидимой и будет тормозить процессор, точнее его блок ввода-вывода. Как будет делаться и по каким правилам - целиком зависит от аппаратной реализации подсистемы памяти.
В руках программиста очень мало средств повлиять на этот механизм. Можно поменять принцип кеширования или отключить его вовсе для какого-либо региона или всей памяти, но это малоэффективно и редко используется. Как развитие, в SSE появились команды прямой записи в RAM минуя кеширование. Эффективность может составлять до 30%(по данным AMD) из-за того, что не загрязняется cache. Спекулятивность чтения заключается в чтении памяти блоками, равными размеру строки cache и в попытках начать операцию чтения следующего блока сразу по завершении ввода текущего.
реклама
Как правило, программа читает и исполняет последовательные ячейки памяти. Но это "как правило" и в этом может быть больше вреда, чем пользы. Операция чтения с участием cache выполняется аналогично записи, только "наоборот". Если процессору затребовались данные и их не оказалось в cache, то посылается запрос в контроллер памяти на чтение. После получения этого запроса, контроллер формирует адрес и начинает последовательное чтение блока из внешней памяти. Контроллер не дожидается окончания чтения блока данных, а начинает посылку в процессор по мере считывания. При поступлении в процессор они автоматически копируются в cache. И сразу возникает проблема - cache не бесконечен и поступлении новых данных приходится выкидывать старые. А если это были отложенные данные на запись и они не были записаны? Естественно, эти данные обязательно надо записать, но сейчас идет чтение ...
Вот и еще один конфликт, контроллер внешней памяти не может выполнять чтение и запись одновременно. Приходится решать проблему первоочередности операций и программа не сможет сказать "брось все, записывай", это как-то решается на уровне контроллера. Спекулятивное чтение и отложенная запись в купе со "специальными" межпроцессорными интерфейсами приводит к весьма нетривиальным результатам.
Впрочем, я забежал несколько вперед. Первый тест, про который я вспомнил, был тест SiSoftware Sandra. Сгрузив последнюю редакцию (Sandra2003), я был приятно удивлен новому тесту "Cache & Memory Benchmark". Впрочем, я еще больше был поражен, когда запустил его. 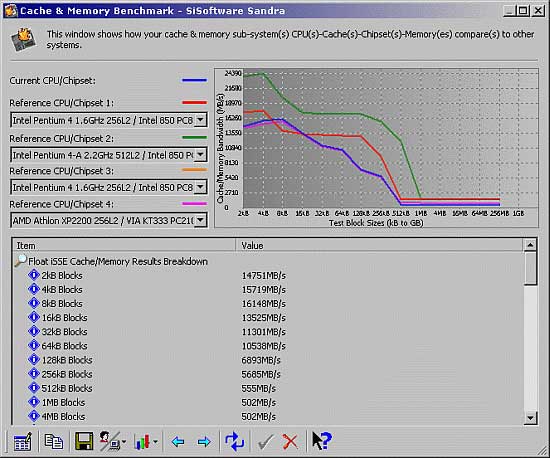 Нет, проблема не в том, что тест выполняется почти 5 минут и не в той наплевательской форме представления результата.... нет, проблема была в самих числах! Для моего процессора результаты почти совпали с образцовым Athlon XP2200+, но какие это были результаты? Получалось, что производительность cache 1 level линейно нарастает на 10%, что объяснимо маленьким размером тестового блока и в общем-то нормально, а потом спадает более чем в 1.5 раза. Простите, это как?? Про cache 2 level вообще весело - ее скорость уменьшалась от емкости как минимум на 20%. Измерения, сделанные позже показали, что цифры Sandra для cache 1 level занижены как минимум в 1.5 раза, а для cache 2 level завышены в 1.2 раза. Все это навевает мысль о "коэффициентах" и "поправках". Низкую скорость по cache 1 level можно объяснить строкой 'Float iSSE' ... но тогда надо писать, что сделали тест SSE специально для Pentium4 процессоров, а не "cache & memory benchmark". Нет ... никаких слов нет, чтоб охарактеризовать "разработчика2 этого теста.
Нет, проблема не в том, что тест выполняется почти 5 минут и не в той наплевательской форме представления результата.... нет, проблема была в самих числах! Для моего процессора результаты почти совпали с образцовым Athlon XP2200+, но какие это были результаты? Получалось, что производительность cache 1 level линейно нарастает на 10%, что объяснимо маленьким размером тестового блока и в общем-то нормально, а потом спадает более чем в 1.5 раза. Простите, это как?? Про cache 2 level вообще весело - ее скорость уменьшалась от емкости как минимум на 20%. Измерения, сделанные позже показали, что цифры Sandra для cache 1 level занижены как минимум в 1.5 раза, а для cache 2 level завышены в 1.2 раза. Все это навевает мысль о "коэффициентах" и "поправках". Низкую скорость по cache 1 level можно объяснить строкой 'Float iSSE' ... но тогда надо писать, что сделали тест SSE специально для Pentium4 процессоров, а не "cache & memory benchmark". Нет ... никаких слов нет, чтоб охарактеризовать "разработчика2 этого теста.
Кстати, у меня нет никакого доверия и к тесту скорости памяти. Если предыдущая редакция Sandra2001 показывала весьма реалистичную скорость в 452MB/sec, то новая 830MB/sec. Простите, но на моей связке CPU-chipset-RAM невозможно получить чтение со скоростью большей 810MB/sec. Еще интересное наблюдение ... При тестировании на производительность памяти Sandra 2001 для этого (Athlon XP2200) и предыдущего (Athlon 900) процессора показывала практически одинаковую производительность в 450MB/sec. Выходит, что Sandra смотрит исключительно скорость линейного чтения. Кстати, другие программы, например HWiNFO32 прекрасно чувствуют смену процессора и она показывает индекс в 320 для старого и 450 для нового процессора. Складывается ощущение, что Sandra просто умножает в 1.7 раза. Косвенным подтверждением может служить цифра в 502MB/sec, выданная "Cache & Memory Benchmark" для размера блока больше размера cache 2 level. Sorry, но и эта цифра вранье. Скорость линейного чтения в 1.36 раза выше. Для точного ответа на вышесказанное надо провести "reverse engineered", но, простите, мне не хочется терять время на _это_. Есть еще более простое решение - считывать частоту FSB, умножать на 8 и говорить, что Memory Benchmark = XXXMHz/sec. А что, ничуть не хуже. Всегда, когда в тестах на производительность появляются "поправки" и "компенсация", будьте внимательны - это попытка обмануть или скрыть свою некомпетентность.
Впрочем, не все так плохо. Есть программы, честно показывающие производительность памяти и cache. Если бы мне сразу попалась Cache Burst 32, то я бы ничего и делать не стал. Уверен, что таких программ множество, только мне почему-то никак не везло. Короче, повторилась причина, предшествовавшая появлению TestMem1 и TestVRAM.... ну да ладно, разобраться все же важнее.
Производительность подсистемы памяти, тестирование с помощью BenchMem.
BenchMem формирует графики двух типов:
- - скорость cache 1 & 2 level
- - производительность чтения и записи.
В программе нет ничего экстраординарного, странно что никто не додумался до простой идеи померить скорость доступа от смещения по адресам. Думаю, первый график не нуждается в специальных комментариях, а второй - на графике выводится скорость чтения или записи для разного "прыжка" по адресам. Например, позиция 1Kb означает, что следующий доступ смещен от текущего на 1Kb в сторону большего адреса и его скорость равна соответствующим позициям графиков. Значения с отрицательными числами соответствуют смещению нового адреса в сторону уменьшения адресов. Цифра 0 обозначает прямое последовательное потоковое чтение (и запись). Отдельные всплески, кроме зоны около 0, означают случайную синхронизацию в связке CPU-...-RAM, что и вызывает всплеск производительности.
реклама
Первая проверка - производительность от процессора и chipset'а.
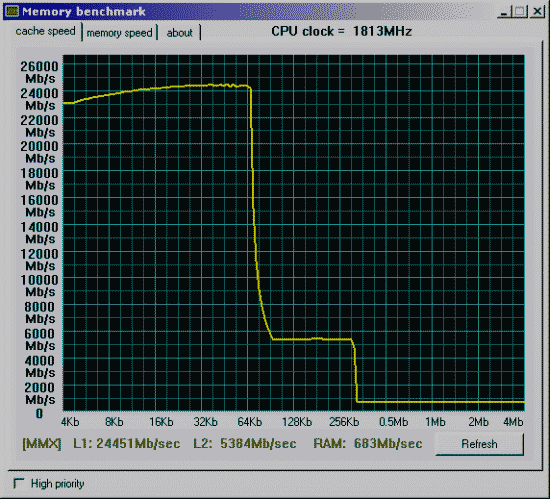

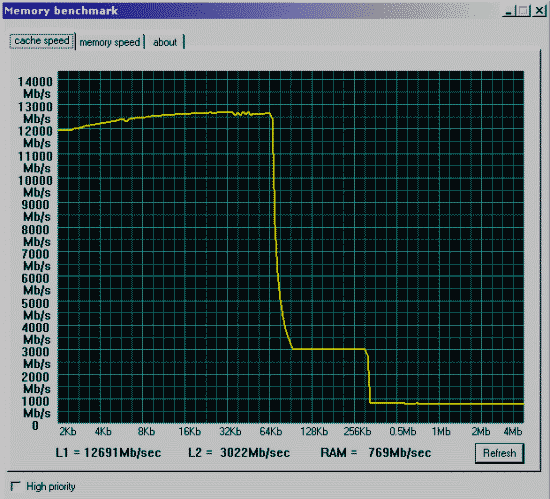

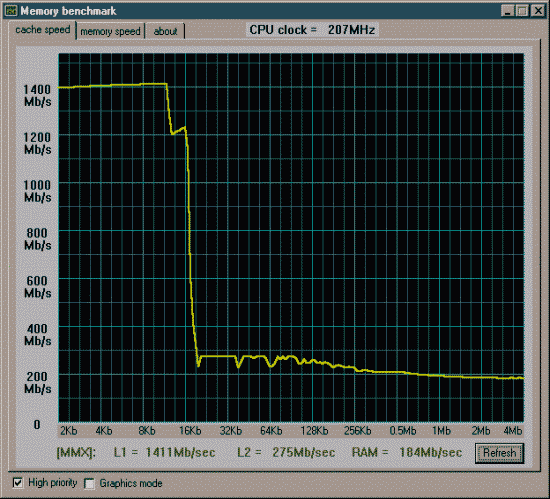
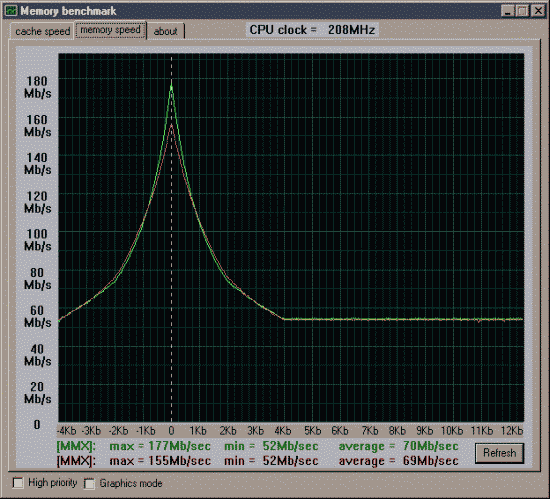

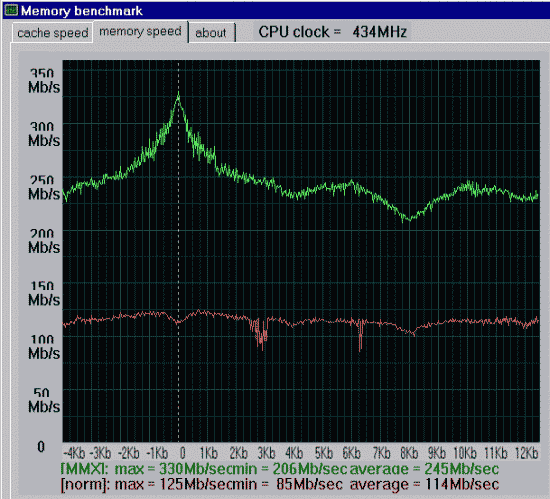

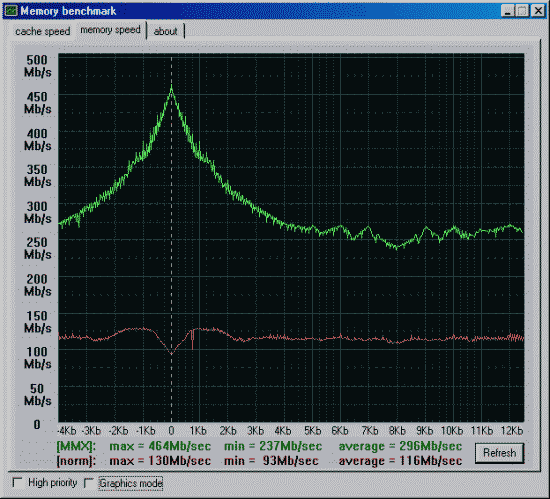
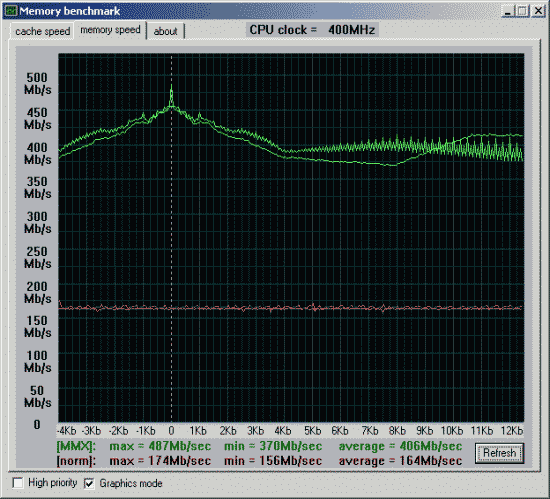
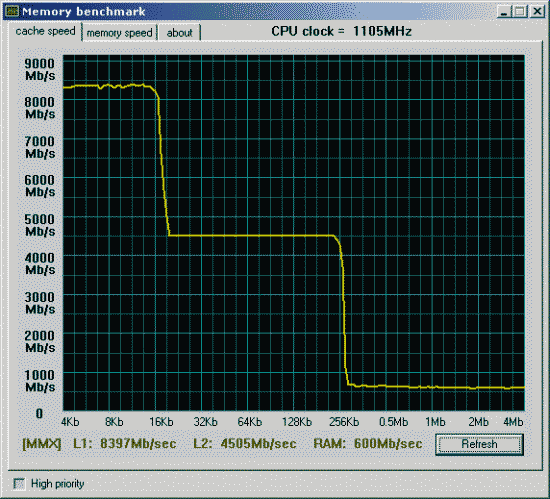
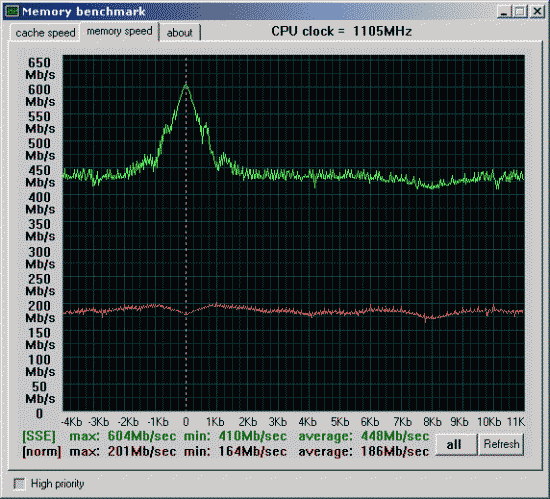
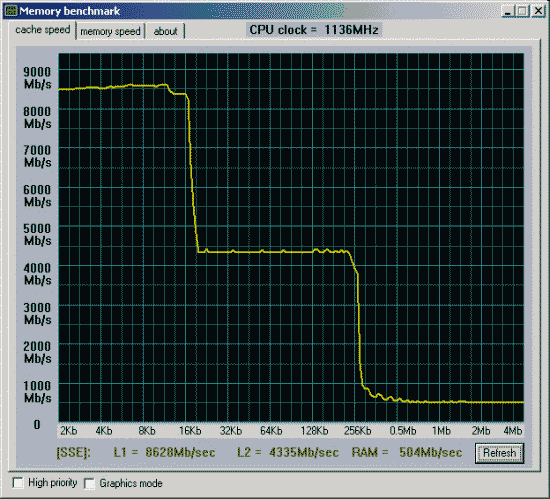
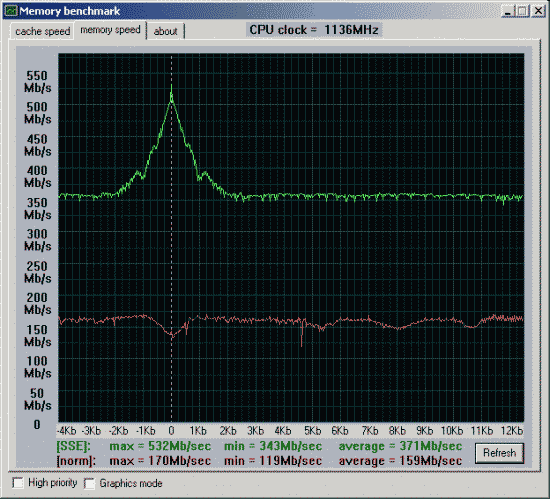
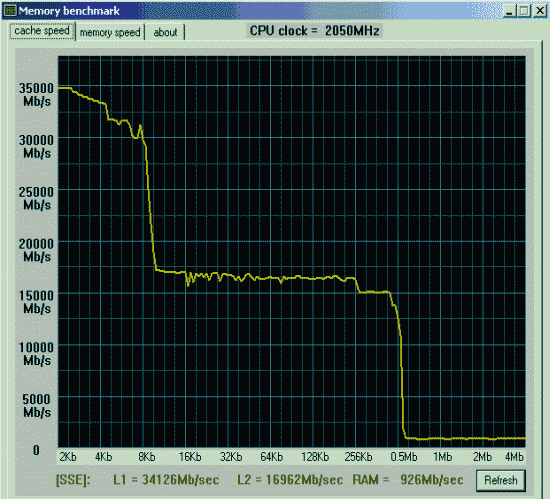
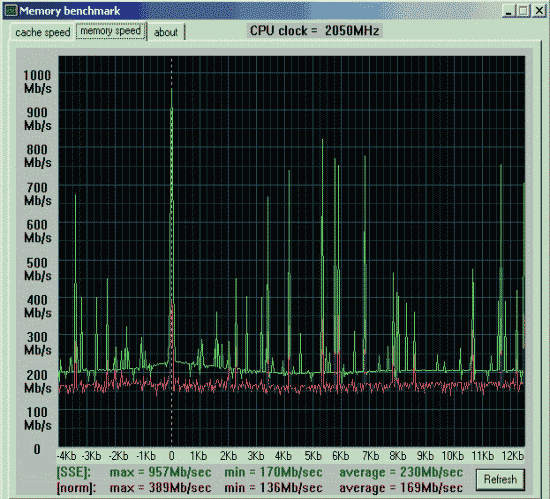
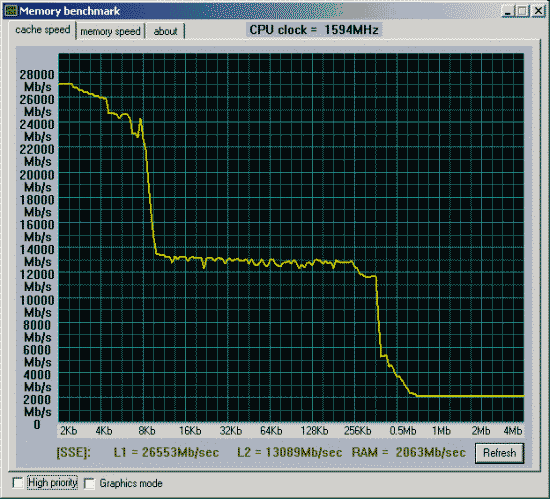
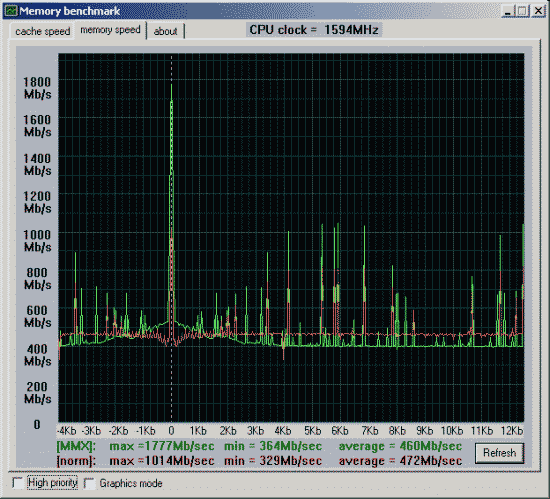

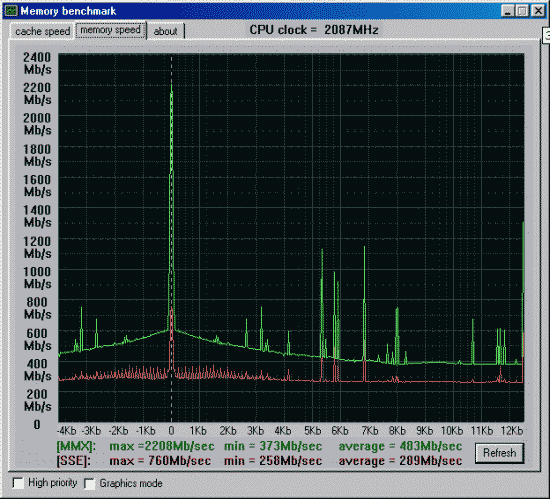
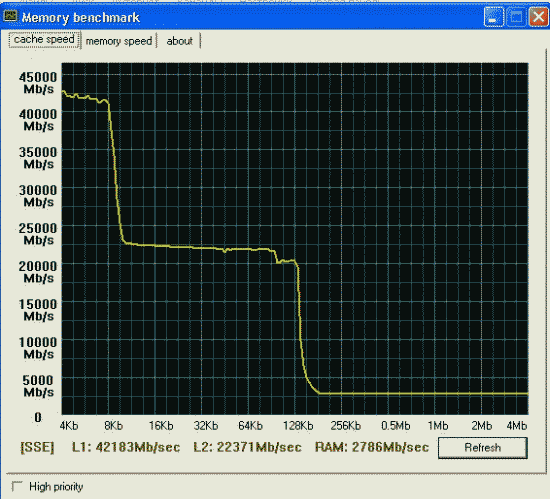
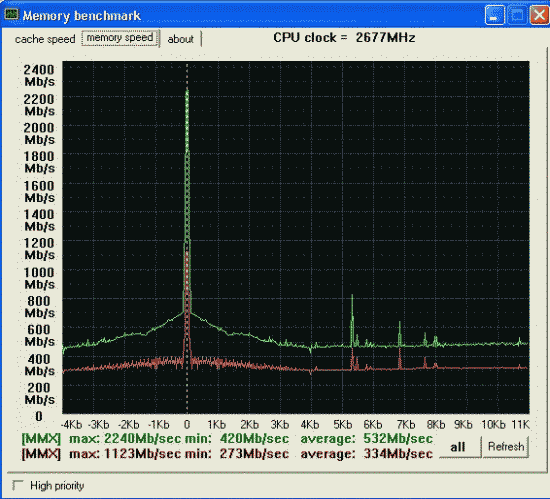
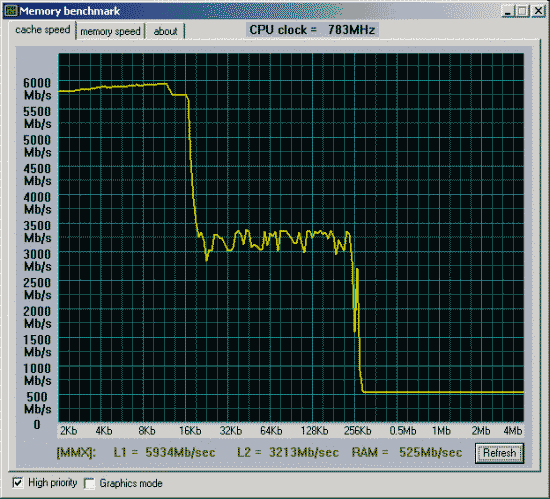
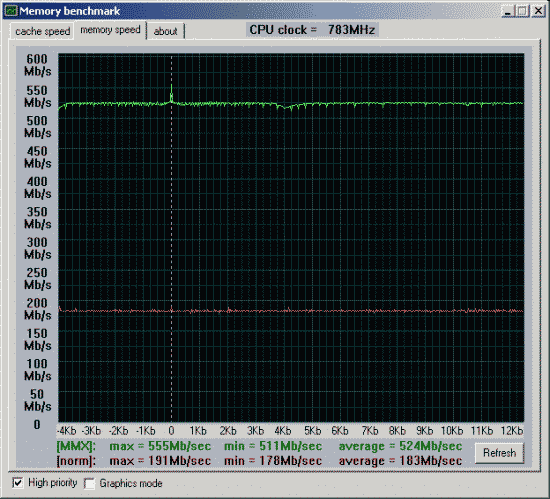

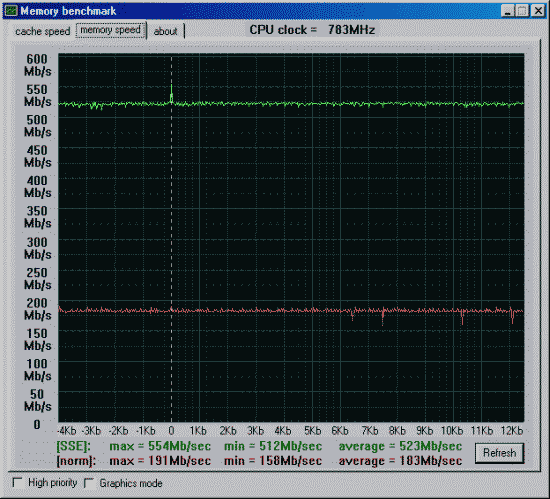
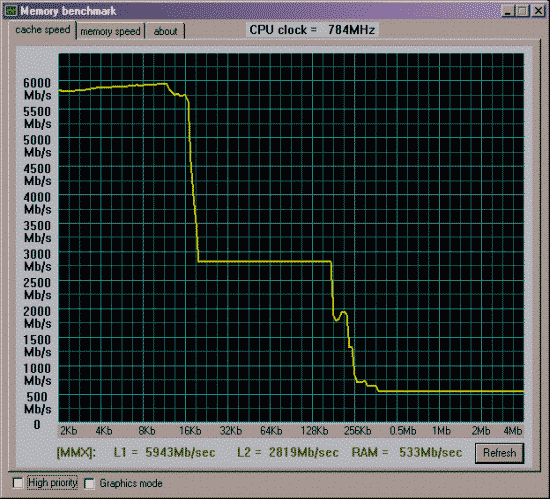

Вторая проверка - производительность от частоты и синхронности памяти.
| Процессор Pentium3 600EB 256Kb L2(Cu-mine) как 133*4.5=600MHz. Mainboard i815EP, status 2090h (supports back-to-back trans., received master abort, fast timing), revision 02h, bus latency 0 SDRAM на 100MHz и асинхронно частоте процессора. |
|
Процессор и mainboard те же, SDRAM на 133MHz и синхронно частоте процессора.
|
|
Все то же, но тайминги установлены в FAST (2-2-2).
|
|
Процессор и mainboard те же, частота FSB процессора увеличена до 150MHz. SDRAM на 150MHz и синхронно частоте процессора.
|
|
Процессор тот же, заменена mainboard. Mainboard VT82C694 Apollo Pro 133A, status 2210h (received master abort, medium timing), revision C4h, bus latency 0. |


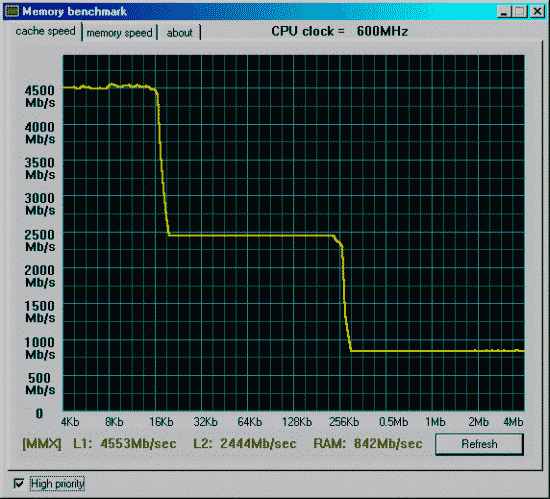
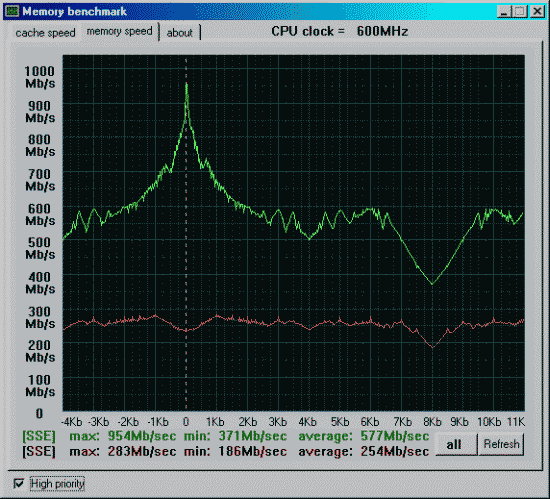
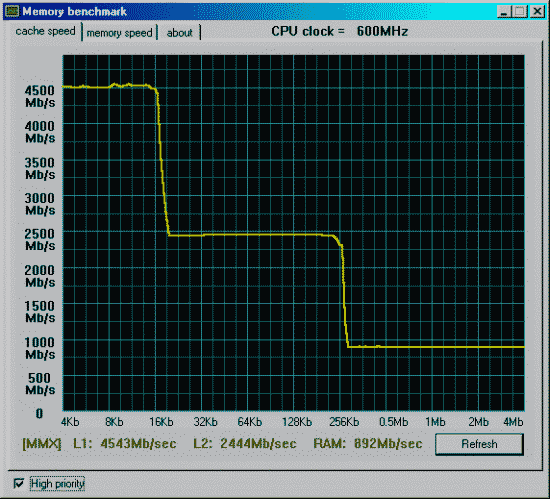
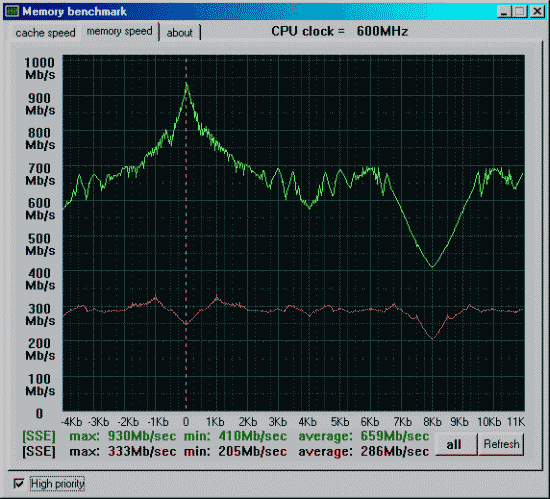
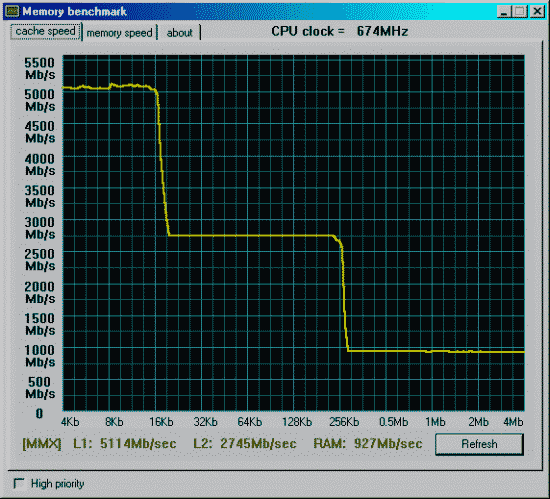
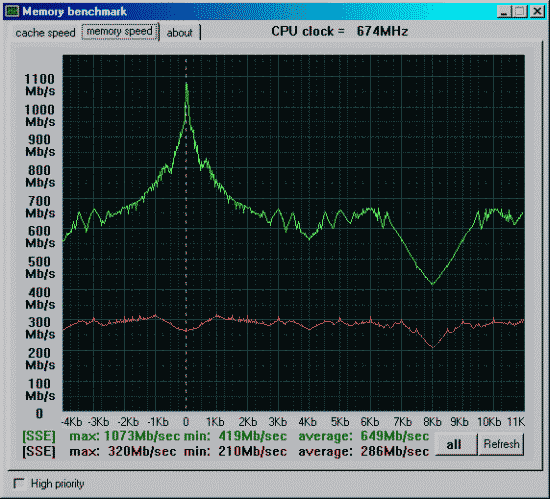
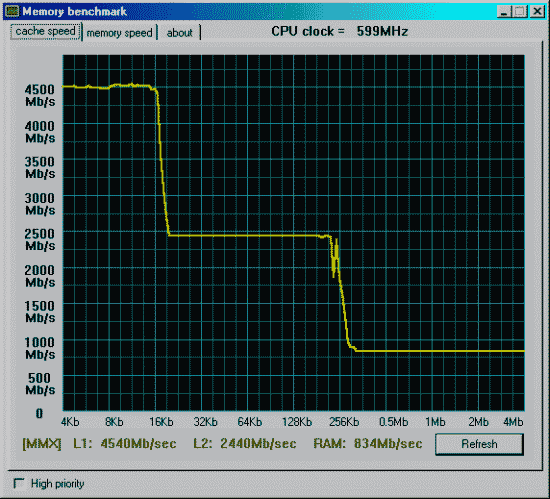
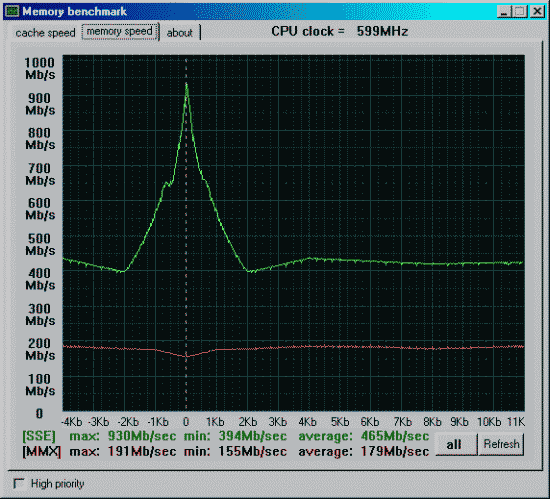
Данные приведены для размера тестового блока 64 байта.
Как комментарий к вышесказанному, если в Athlon XP выключить 'advanced speculative caching', то:

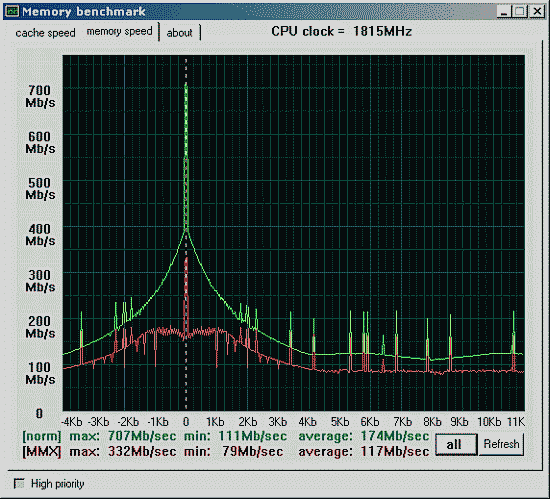
И ... не хотел связываться с "самой любимой фирмой", но предвижу множество вопросов. Добавлю графики для размера блока обмена в 64-байта на AM750, VIA KT133 и KT266:

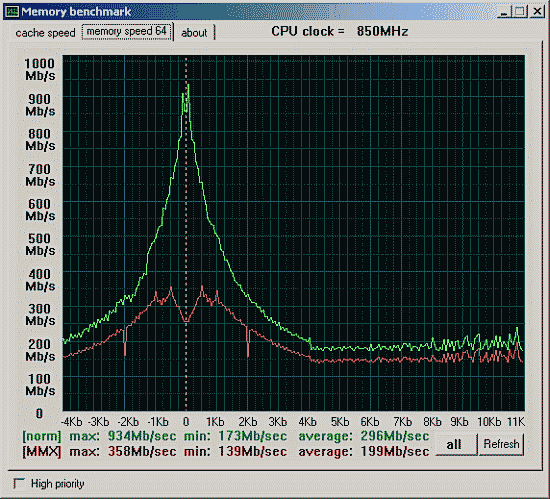
Анализ графиков, вид графиков.
Вид кривых определяются политикой управления банками и станицами SDRAM. Например, у VIA четко прослеживается кратность 4Kb, а это как раз размер страницы для модуля DIMM. У AM750 падение скорости в области 8Kb обусловлено схожей причиной, но его вызывает не контоллер, а система кеширования, наследство страничного выравнивания Alpha 21264.
Анализ графиков, частота и тайминги памяти.
Одна из составных частей этого тестирования - проверка влияния синхронности и таймингов памяти на быстродействие подсистемы памяти. Рассматривается один и тот же процессор Pentium 600EB на mainboard i815PE. Приняты обычные, стандартные установки для этого варианта процессор-mainboard, т.е. процессор и SDRAM на частоте 133MHz, тайминги памяти в BIOS default (3-3-3).
Наблюдения:
- Отношение линейной скорости записи к линейной скорости чтения неизменно для всех случаев.
- Установка таймингов в "fast" кроме увеличения линейной скорости, в значительно большей степени увеличивает среднюю скорость. Если для частоты 133MHz(fast) скорость линейного чтения несколько меньше SDRAM на 150MHz, то скорость среднего чтения для 133(fast) превышает этот параметр для 150MHz(normal).
- При установке частоты SDRAM асинхронно и меньше процессора, наблюдается этот же эффект, только со знаком "-".
Причина происходящего достаточно проста - для случая асинхронного обмена нужны лишние такты шины на синхронизацию, а ускорение в режиме 133MHz(fast) - меньшим количеством тактов контроллера SDRAM для операций с памятью.
Немного теории.
Какие факторы влияют на производительность подсистемы памяти? Основной элемент - контроллер внешней памяти, остальные составляющие:
- - для обычных chipset'ов однотипные контроллеры имеют близкие параметры. Это хорошо видно на представленных графиках для процессоров семейства Pentium2. Да, конечно, разные фирмы вложили свое понимание в систему взаимодействия с модулями памяти. Особенно выделяется VIA.
- - блок ввода-вывода процессора. К сожалению, процессор "не выбирают".
- - интерфейс от процессора или межпроцессорный интерфейс. В так называемых "новых" процессорах есть специальный канал взаимодействия между множества однотипных процессоров и периферийных устройств. Сказать, что он никак не влияет на скорость подсистемы памяти - значит сказать "ничего". Посмотрите графики на Celeron и Pentium2/3, в которых межпроцессорный интерфейс был в зачаточной форме и новейшие процессоры Pentium4 и Athlon. Впрочем, чаша сия не минула и Pentium2-chipset'ы. Посмотрите на графики i815(с hub'овой структурой) и BX для одного и того же процессора.
- - система FIFO.
Т.о., без FIFO передача данных между активными устройствами теряет всякий смысл из-за ре-синхронизаций и ожидания. С этим злом приходится мириться. Я не зря говорил о "достаточном" размере FIFO, если его размер недостаточен, то передатчик будет работать медленнее из-за постоянного переполнения и ожидания готовности приемника. Впрочем, чрезмерно большой FIFO так же вреден - данные, положенные в FIFO обязательно будут переданы приемнику, а если процессор сгенерировал новые данные по тому же адресу? Да и ... он начнет дублировать работу cache. И, процессор не может динамически управлять работой FIFO, чтоб говорить о срочности данных на передачу. Например, процессору надо прочитать данные, а весь FIFO забит данными из контроллера памяти в процессор. Нет, это не те данные, которые сейчас так нужны процессору, а так называемое спекулятивное чтение - предполагаемое последовательное чтение. И что? .... процессору придется вначале забрать весь этот ненужный мусор прежде, чем дождется нужных. Блок ввода-вывода будет простаивать. Чем бОльше FIFO, тем дОльше ему придется ждать.При случайном чтении это один из важнейших факторов, тормозящих обмен. В своих chipset'ах nForce NVidia специально предусмотрела борьбу с подобным злом - chipset умеет обнаруживать случайный доступ и отключать ненужное, вредное спекулятивное чтение. Как с этим же борются другие фирмы, у меня нет данных. Думаю - никак.
Но и это не самое неприятное - для межпроцессорного интерфейса таких FIFO между процессором и контроллером внешней памяти ДВА. Один между блоком ввода-вывода процессора и межпроцессорным интерфейсом, второй - между ним и контроллером внешней памяти. И вот это-то и особенно неприятно!
Попробую привести аналогию. Представим передачу данных процессор-память как механическую систему передачи усилия. Процессор характеризуется быстрыми и относительно редкими посылками данных, а контроллер памяти - весьма медленное устройство с постоянной и очень низкой скоростью. Для нашего примера: процессор как бы "толкает" медленный контроллер. Для современных процессоров, скорость работы блока ввода-вывода, если судить по производительности cache 1 level, никак не меньше 25GB/sec, а контроллера внешней памяти - порядка 1-2GB/sec, что подтверждает правильность приведенной модели. Т.к. выбрана механическая модель, то эквивалентом FIFO будет пружина, а межпроцессорного интерфейса - некая масса. Причем, эта "масса" переменной величины и зависит от интенсивности другого обмена самого CPU, AGP/PCI устройствами Bus Mastering, да и возможное наличие второго процессора не улучшают ситуацию. Мне кажется, аналогия с "массой" достаточно корректна - процессор пытается передать данные, а шина занята, что вызывает накопление данных в FIFO, т.е. "пружина сжимается". Положим, что процессор периодически записывает данные с пиковой скоростью в 25 раз быстрее контроллера внешней памяти. Ok!, поехали ...
Вариант №1 - без FIFO.
Процессор пошлет данные, контроллер начнет записывать, затем процессор пошлет еще данные, а контроллер все еще пишет _те_ данные. Процессор (т.е. программа) будет ждать окончания операции от контроллера и так все операции. Как известно, для современных процессоров, операция ввода-вывода из внешней памяти самая продолжительная операция, за ее время может выполниться до тысячи обычных операций. Иначе говоря, процессор будет просто стоять и ждать, многопоточность и многоконвейерность его не спасут - в других потоках так же попадутся команды ввода-вывода.
Вариант №2 - один FIFO.
Сценарий такой-же, но результат сильно отличается. Процессор отправляет данные на запись, они попадают в FIFO и сразу же забираются контроллером. При повторной записи из процессора данные снова кладуться в FIFO, а процессор возвращается признак выполненности операции записи. Т.е., процессор (читай - программа) продолжает работать без каких-либо остановок. Для нашего механического примера, если процессор толкает пружину(FIFO) на 1/25 ее максимального усилия. Цифра 1/25 берется как отношение скоростей процессора и контроллера. Когда процессор записывает данные в FIFO, то пружина как бы сжимается; когда контроллер выбирает данные из FIFO, то пружина ослабляется. Если процессор записывает в FIFO слишком много, то пружина сожмется до предела и вся система перейдет к варианту №1. Т.о., если процессор будет записывать не очень часто, то буфер FIFO не заполняется и операция записи для него выполняется незаметно. Конкретно для примера - если процессор хочет записывать не выше скорости контроллера _в_среднем_, проблем не возникает. В реальной работе, система находится в состоянии постоянного перехода вариантов 1 и 2, а эффективность FIFO выражаетсмя в несинхронности процессов.
Вариант №3 - два FIFO и межпроцессорный интерфейс (МИ).
Один FIFO между процессором и МИ, второй между МИ и контроллером. Узел процессор-МИ и узел МИ-контроллер работают аналогично варианту №2, но тут есть проблемы. Любая пружина характеризуется усилием и длиной. Для FIFO этим является стратегия записи/выборки и размер буфера FIFO. Для пружины в узле процессор-МИ и узле МИ-контроллер эти параметры разные. Что произойдет, когда процессор "стукнет" новыми данными? Пружина 1 сожмется и передаст энергию пружине 2, которая начнет передавать усилие контроллеру. Но часть энергии из пружины 2 вернется назад и ... в точке их соединения возникнут колебания. Нечто подобное происходит и с реальными FIFO.
Один общеизвестный FIFO - это уже стандартный COM-порт на микросхеме 16550. Конечно, эту микросхему как отдельное устройство давно не ставят, ее интегрировали в chip MultyIO (микросхема устройств ввода-вывода). Приемный FIFO 16550 имеет длину на 14 и более посылок и настраивается по времени выдачи запроса на съем данных. Этот параметр очень важен, если установить его слишком малым, то эффективность системы падает - переход процессора на обработку запроса и возврат к прерванной программе выполняется весьма ощутимое время. Если установить его равным всей величине FIFO, то легко можно потерять данные из-за переполнения буфера FIFO. Выходят из положения так - оставляют небольшой запас на максимальное время от выдачи запроса до начала съема данных процессором из FIFO. Хочу обратить внимание на слово "максимальное" - если это время будет превышено, то FIFO переполнится.
Теперь, если предположить идиотскую ситуацию, что для повышения эффективности поставили еще один FIFO между 16550 и процессором. Вроде бы это должно устранить все-все неприятности, ведь второй FIFO гарантирует высокую скорость съема. Вот теперь можно сравнить ожидаемое время для обоих случаев: в обычном режиме минимальное и максимальное время реакции процессора достаточно точно известно и предсказуемо и не очень сильно меняется; со вторым FIFO минимальное время почти 0, а максимальное? Хочется сказать "0", но не получится - процессор может быть занят "по максимуму", данные на вход FIFO могут приходить в разном темпе.
К чему привела эта идиотская конфигурация? Время от запроса до начала съема данных меняется скачком от 0 до весьма ощутимой величины. Эта величина даже больше первого случая, ведь во втором FIFO остались данные от предыдущего запроса. Еще проблема усугубляется тем, что запас в FIFO 16550 оставили небольшим. Ну, в самом деле, если второй FIFO быстренько все заберет, то зачем разбазаривать основной? Вот и ... при неудачном стечении обстоятельств два FIFO "сломают" друг друга. Для первого варианта, без второго FIFO, этого бы не произошло - процессор бы просто останавливал обмен данными выдачей специальных сигналов. При этом ничего особенного не случится, данные не потеряются, только скорость приема несколько упадет.
Замечу от себя - нет большей гадости, чем разнородные FIFO, работающие друг на друга. В результате, пропускная способность в канале процессор -...-контроллер стала достаточно непредсказуемая, что усугубляется спекулятивностью работы с памятью и ... Вы не забыли про PCI/AGP устройства? Да, их загрузка контроллера памяти несопоставимо меньше процессорного, но это только "в среднем". "Импульсные" нагрузки по МИ очень хорошо "раскачивают" всю систему.
Немного выводов, процессоры.
Ну что сказать ... все плохо. Intel и AMD увлеклись многопроцессорными системами и это сказалось. Впрочем, о AMD позже. Вспоминается Pentium3 с BX и становится скучно. Про микропроцессорный интерфейс я уже много сказал, думаю, добавить больше нечего. Единственно на что хочется обратить внимание - Intel при упрощении процессоров из Pentium в Celeron не только укорачивает cache 2 level, но и убирает улучшенное управление кешированием. Это хорошо заметно по приведенным графикам, Pentium2-400 (slot1, 512KB cache) имеет нормальную кривую производительности, а Celeron-500 значительно хуже. И там и там был один и тот же chipset BX.
Intel, chipset's
AMD честно созналась, что chipset'ы не умеет делать и ее трогать не стоит, возьмем Intel. Все почему-то считают, что лучшие chipset'ы, особенно в связке с своими процессорами, делает Intel. Так ли это?
Ok!, беру их сегодняшнее творение i845pe и начинаю сравнивать с конкурентами. С VIA? ... как в том анекдоте "...я столько не выпью!". Остается SIS, благо появились mainboard на chipset'е SIS655.
Если посмотреть графики и таблицу, то i845pe имеет почти равную потоковую скорость чтения, но в 1.5 раза меньшую потоковую скорость записи. Для не-потокового, случайного доступа к памяти i845pe проигрывает SIS 31% и 39% для чтения и записи. Особенно удручает крайне низкая эффективность работы прочессора в режиме случайного доступа с DDR.Т.о., операции со случайным доступом идут в 5(!) раз медленнее линейного. Если программа довольно часто нуждается именно в случайном доступе, то производительность всей системы будет определяться этими числами. Этим грешат не только разные базы данных, но и игры. Смешно, но подчас DDR+i845pe будет работать медленнее, чем Pentium3+BX. Впрочем, уже не смешно. Реальное тестирование программных продуктов на разных платформах показывало где-то похожую тенденцию. Я не мог понять причины, теперь все ясно, увы.
В SIS655 сильное падение при переходе к случайному доступу обусловлено ее 128-и битным интерфейсом и вполне естественно. Ну, в самом деле, если шина к памяти стала в 2 раза шире, то это вынуждает обмениваться блоками удвоенной величины, а программы пытаются оперировать блоками одинарной длины. Короче говоря, повторяется проблема RIMM'ов. При последовательном доступе размер блока не имеет значения.
Впрочем, даже в таком неудобном режиме SIS быстрее i845pe по всем параметрам, правда всего на 30-50%. Впрочем, Sandra оперирует только одним параметром - скоростью линейного чтения, где слегка подразогнанный i845pe может обогнать SIS655. Все пользуются именно этой самой Sandra..... у Вас никаких мыслей не возникает?
next... Если сравнить i845pe с i850, то все становится на свои места. Самая эффективная работа с памятью у RIMM, и это говорит, что лозунг Intel'а "RIMM любой ценой" был воплощен в жизнь "на все 100" - ни с чем другим процессор Intel Pentium4/Celeron не может работать. Складывается ощущение, что оптимизация именно под RIMM с его специфическим "сериальным" обменом легла краеугольным камнем в архитектуру всего Pentium4. Chipset i845 был сделан как подачка, Intel не хотела вводить поддержку DDR SDRAM в свою продукцию и уступила только под сильным давлением рынка.
Сейчас Intel заявляет, что полностью переходит на DDR. Что же ... это как-то внушает оптимизм, вдруг следующее поколение процессоров и chipset'ов будет работать нормально? Нет, не ждите ничего хорошего от Prescott и i72**-i865 chipset'ов! Для этого придется действительно переделывать процессор, а Intel'у это не выгодно. Проще гнать "мегагерцы". AMD.
Первый процессор, сделанный фирмой AMD независимо от Intel, был К6. Интересный процессор с очень неплохими характеристиками, если не учитывать его математический сопроцессор. Впрочем, если вспомнить, что этот процессор был куплен у NexGen, то становится понятна его несбалансированность - у 6x86 NexGen вовсе FPU отсутствовал. AMD приделала недостающий FPU и сделала это весьма плохо. К6 очень сильно проигрывал Pentium в реальных расчетных приложениях, а в играх особенно. Основное отличие Pentium и K6 в том, что блок FPU Intel был интегрирован в состав процессора и мог работать независимо и совместно с основным процессором. У К6 с этим дело обстояло значительно хуже - его модуль FPU был механически вложен в состав процессора так же, как это сделано в 486 процессорах. Это приводило к тому, что в одно и то же время мог работать либо процессор, либо сопроцессор. Падение производительности в играх было настолько катастрофическим, что AMD пришлось срочно выдумывать специальные расширения системы команд, чтобы хоть как-то улучшить бедственное положение. Так и появилась расширение 3Dnow!.
Следующий процессор с кодовым именем К7 обладал весьма странными характеристиками, он вовсе не походил на К6. Впрочем, Pentium4 тоже не походит на Pentium3, скорей уж на Эльбрус. AMD пошла по другому сценарию - было приобретено ядро процессора у NexGen (опять NexGen??) и шина EV6 у DEC. С первым как-то понятно, а вот зачем AMD потребовалась шина процессоров Alpha? AMD замахнулась на рынок мультипроцессорных серверов или просто ей очень понравилась эффективная шина EV6?
На AMD процессоры очень мало информации, но из того, что есть ...
|
Advanced Micro Devices |
Digital Equipment Corporation |
|
Процессор: Athlon, Duron, Athlon XP chipset: AM750, AM760, AM760MP |
Процессор: Alpha 21264 chipset: Irongate, Irongate2, Irongate4, Tsunami |
|
Процессор Athlon: Super-scalar microprocessor with speculative execution. Supports a 36-bit virtual address. Supports a 34-bit physical address. Outstanding References Eight VDBs for victims and probe response data Eight WDBs for sub-block stores Eight PBs for system probes cache misses 8*64bits Prefetches Спекулятивное чтение Отложенная запись MMX/SSE/3Dnow! запись минуя cache Translation Buffer (TB) ITB 128-entry,fully-associative DTB 128-entry,fully-associative On-chip Cache 1st-level Dcache 64 KB, 2-way Latency 2(1) cycle 1st-level Icache 64 KB, 2-way Latency 2(1) cycle Off-chip Cache внутренней до 512Kb при использовании внутреннего TB контроллер поддерживает до 8Mb внешней памяти шина 128-бит, частота 1/5 частоты процессора(возможно). Memory Latency нет данных |
Процессор Alpha 21264: Super-scalar microprocessor with speculative execution. Supports a 48-bit or 43-bit virtual address. Supports a 44-bit physical address. Outstanding References loads 32 stores 32 deep system probe queue 8 cache misses 8*64bits Prefetches Speculative read Modify intent WH64 Translation Buffer (TB) ITB 128-entry,fully-associative DTB 128-entry,fully-associative On-chip Cache 1st-level Dcache 64 KB, 2-way Latency 3(2) cycle 1st-level Icache 64 KB, 2-way Latency 3(2) cycle Off-chip Cache Latency 12 cycles Bcache from 1MB to 16MB 128-bit data bus, clock rate varies as a from 1.5 to 8 times the CPU clock. Memory Latency 34 cycles |
|
|
|
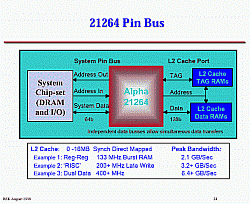
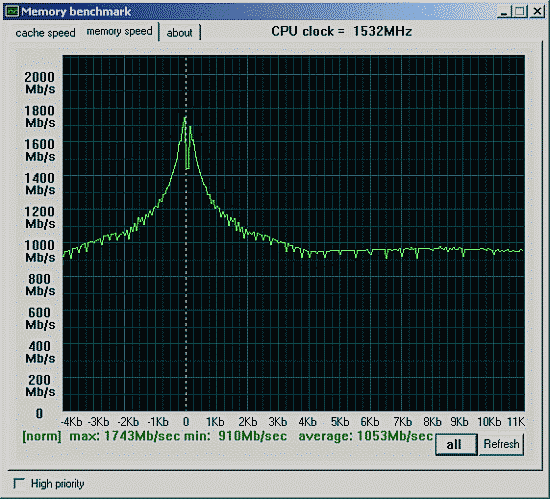
Представляет некоторый интерес список mainboard для процессоров Alpha:
|
mainboard |
processor |
Key Features |
|
UP1100 |
Alpha 21264 (EV67) |
AMD Irongate chipset, max. 768MB main memory, 2x AGP, UDMA 66 |
|
UP1200 |
Alpha 21264 (EV67) |
AMD Irongate2 chipset, max. 4GB main memory, 4x AGP |
|
UP1500 |
Alpha 21264 (EV67) |
AMD Irongate4 chipset, max. 4GB main memory, 4x AGP |
|
UP2000 |
Alpha 21264 (EV67) |
Tsunami chipset, max. 2GB main memory |
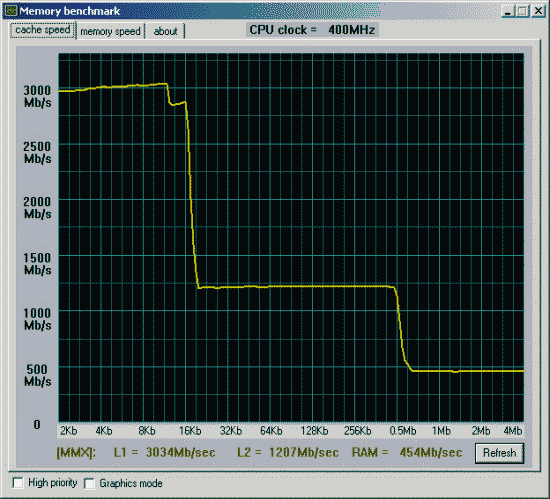
Cache 1 level.
Для повышения его производительности проходится жертвовать размером. У Intel Dcache L1 latency 1 такт при размере 8Kb, у AMD его размер увеличен в 8 раз при увеличении времени доступа до 2х тактов. Что лучше - чуть бОльшая производительность или размер? Впрочем, в уже Athlon Thunderbird cache 1 level latency уменьшили до минимума = 1. Может сложиться ощущение, что большой размер cache 1 level не особенно и нужен, cache 2 level имеет достаточный размер и весьма высокую производительность, особенно у процессоров Intel. Но не все так просто, в нем нет понятия блока передачи данных и его latency крайне мала. Для cache 2 level все иначе, она как-бы вторая внешняя память, с ней блочный обмен.
Что интересного в K8-Hammer?
Интегрированный контроллер внешней памяти. Если посмотреть спецификацию на EV7, то ... Compaq EV7 собран из того-же EV68 ядра 21264 процессора с инегрированным двуканальным RDRAM memory контроллером, 64KB cache 1 level & 1.5MB cache 2 level и поддержкой до 128 процессоров.
Из особенностей:
- cache 1 level latency уменьшилась с 3х до 2х clock
- размер блока передачи данных удвоен до 16*64bits
- уделено особое внимание взаимодействию ядра и блока памяти.
- время доступа к RDRAM 75nS
- поддержка мультипроцессорности: в контроллере памяти сохраняется номер процессора, в cache которого есть эти данные. Дублирование данных не происходит.
- физический адресный бит №36 определяет, будут ли последовательные адреса расположены на одиночном процессоре или чередуются между двумя процессорами.
- Поля адреса учитывают до 128 точек разветвления, с 32GB в точку разветвления.
Увеличенный в 2 раза размер блока передачи данных увеличит скорость в ((8*2/(4+8*2)/(8/(4+8)) = 1.2 раза, но сам блок стал в 2(!) раза больше. Т.е. скорость последовательного линейного доступа увеличится, а "случайного" уменьшится в 2 раза. Это не может не тревожить.
Ну ладно, я отвлекся. Положим, что можно поставить некоторое равенство между EV6 21264 и AMD Athlon. Это позволит почерпнуть хоть какую-то информацию о происходящем.
Для обмена по системной шине EV6 используется исключительно пакетный обмен. Причем, если для обращения к портам и записи допустим обмен не полным блоком, то чтение ведется исключительно полным блоком, равным одной строки cache в 64 байта. Это повышает потоковую, линейную скорость чтения, но отрицательно сказывается на времени доступа. Второй ограничивающий фактор - скорость передачи данных по самой EV6. Эта шина с синхронизацией от передающей стороны, команды и данные передаются блоками. При уменьшении сложности и повышении надежности это приводит к дополнительным задержкам в обмене. В режиме быстрого обмена "Fast Data Mode", для передачи данных нужно 4 цикла на команду/подтверждение/захват шины и 8 циклов на данные. Т.о., на чтение или запись уходит 12 циклов. EV6 борется с повышенной задержкой на передачу блока путем возможности прямого доступа ко всем поступающим данным.
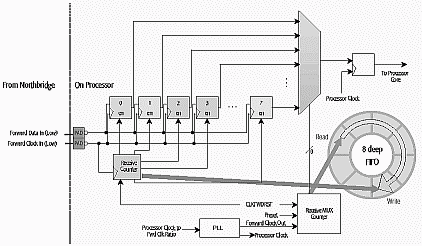
Попробую подсчитать пропускную способность шины EV6 и внешней памяти. Для Irongate(AM750) это будет:
- SDRAM на частоте 100MHz, пропускная способность 720MB/sec. Эта цифра выходит как Частота_SDRAM * Ширина_SDRAM * Эффективность_Обмена_SDRAM; 100MHz * 8 * 0.9 = 720MB/sec.
- частота EV6 = 100MHz*2=200MHz. С учетом эффективности прередачи данных в 8/12 и шины шириной в 64 бита(8 байт), пропускная способность составит 200*8*(8/12)=1067MB/sec(точнее 2133MB/s, см. ниже).
Обе эти цифры близки и достаточно сбалансированы, особенно с учетом того, что процессор вынужден обмениваться и другими командами с chipset'ом в процессе работы. Для Iroingate2 и новее была применена более быстрая память DDR SDRAM. Если произвести аналогичные расчеты для предложенного варианта, то это составит:
- процессор на частоте 133MHz
- - DDR SDRAM на частоте 133*2=266MHz
Ппропускная способность шины принципиально не изменилась и равна 1420MB/sec, а памяти удвоилась до 1.7GB/sec.
Впрочем ... что-то не сходится. Солидные программы, в том числе и cachemem, показывают скорость чтения DDR SDRAM в 1.5G для приведенных установок частот. Что-то тут не вяжется. Я верю в цифры cachemem, но может он слегка неточно считает время, ведь его результат лишь чуть превышает 1420MB/sec? Несколько оптимизировав BenchMem я получил скорость в 1.9GB/s. Тут уж спорить не с кем, надо разбираться.
Оказывается, при инициализации процессора в SIP указывается множитель частоты обмена по шине EV6. Он может принимать два значения:
- 2 бита на clock системной шины (clock системной шины это частота от mainboard)
- 4 бита на clock системной шины
Т.о., частота передачи информации составляет 2х или 4х этой частоты. По SIP (Serial Initialization Packet Protocol) устанавливаются самые главные настройки:
- количество бит-clock на clock системной шины.(во сколько раз быстрее шина EV6 по отношению к системной частоте процессора)
- AMD или DEC совместимый режим
- SYS_CFG - регистр аппаратной конфигурации процессора
- BUCFG - регистр конфигурации шины
- McodeCtl - регистр распределения карты памяти и I/O
- - другие параметры
Протокол называется сериальным потому, что эта информация считывается из EPROM с сериальным доступом, аналогичные используются для хранения SPD на модулях DIMM. На самом деле, в mainboard на chipset'е Irongate специальных микросхем не ставят, сам chipset эмулирует присутствие EPROM и выдает данные, установленные AMD при изготовлении. Правда, выходы для подключения внешнего EPROM имеются и, наверно, используются для установки этого внешнего EPROM для инициализации EV6 с процессорами 21264. Т.о., при включении chipset определяет как свои жизненные параметры, так и конфигурирует процессор. Конкретно к множителю шины - он ставится как 4х.
Немного отклонюсь от темы. У шины EV6 очень интересный способ борьбы с большим количеством проводов между процессором и chipset'ом - все они разбиты по группам до 16 однотипных сигналов и на каждый приводится свой сигнал стробирования. Например, шина данных в 64 провода разделена на 4 части 1-16, 17-32, 33-56, 57-64 с соотвествующими строб-сигналами. Это превращает широкую шину в много маленьких, что очень способствует возможности получения высоких частот. Почему это происходит - попробуйте представить разъем процессора и северного моста chipset'а. Проводники с разных сторон разъема проходят разное расстояние, это крайне важно, ведь расстояние подразумевает время распространение сигнала по проводу, а разное расстояние подразумевает разное время. Частота обмена по внешней шине EV6 весьма высока, порядка сотен мегагерц и неконтролируемые задержки фатальны. Ну а так - группа из 16 проводников данных идет вместе с своим строб-сигналом и расхождение сигнала внутри этой группы мало. Т.о., расхождение между группами не оказывает никакого влияния.
К расчетам ... выходит, что максимальная скорость обмена для процессора на частоте 133MHz составит не 1420MB/sec, а 2840MB/sec. Это сбалансировано под одноканальную DDR SDRAM, а вот для двухканальной эта сбалансированность нарушится - 128bits DDR будет быстрее шины EV6. Впрочем, это не совсем так, выигрыш от применения 128-битной DDR памяти будет и весьма значительный - при такой организации доступа к памяти можно уменьшить количество чтений (записей) каждого DIMM с восьми до четырех. Это увеличит стабильность модулей DIMM и весьма значительно уменьшит время доступа данных из контроллера. Т.е., блок в 64 байта для передачи по шине EV6 будет сформирован почти в 2 раза быстрее. Такая система будет спокойней относиться к случайному доступу и к загрузке кода программы из памяти при кеш-промахах.
Возникает интересный момент - контроллер памяти может выдавать данные быстрее, чем их забирает шина EV6. Тут вполне понятным становится желание AMD увеличить частоту шины EV6. В такой ситуации можно было бы сделать частоту памяти несинхронно частоте шины (ниже ее), что выровняет производительности систем, но это сменит режим на "Fast Data Disable Mode" и скорость обмена по EV6 катастрофически упадет.
Еще один неприятный момент: обмен по шине EV6 для чтения из памяти, особенно для чтения, может быть только 64 байта. Дело в том, что обычный chip SDRAM разрабатывался в эпоху Pentium/Pentium2 и расчитан на 4 такта выборки данных шириной 64бита (8 байт), что составит 4*8=32 байта. В данном случае, BIOS перепрограммирует контроллер и SDRAM на удвоенный размер. А вот это и плохо. Да он может работать и в режиме {1, 2, 4, 8, полная строка}, но обычные chip'ы SDRAM тестируются сборщиками модулей DIMM под 4, а AMD устанавливает это число в 2 раза больше. Это приводит к повышенной неустойчивости вроде бы абсолютно надежных и обкатанных модулей, которые прожили счастливую жизнь на уже устаревшем Intel BX chipset'е. Возникновение сбоев для нормально работающего DIMM весьма странно и неприятно. Все сказанное касается не только AMD, но и, в какой-то степени, Intel.
Впрочем, современные модули DIMM тестируют с учетом вышесказанного и этот эффект не должен проявляться, конечно, если не брать очень "подозрительных" и старых модулей DIMM.
В качестве заключения.
Производительность подсистемы памяти зависит не только от таких очевидных параметров, как частота и тайминги памяти, но, увы, и от revision процессора, chipset'а и, даже версии BIOS. Причем, более новый BIOS вовсе не означает самую быструю конфигурацию системы.
Второй неутешительный вывод - современные процессоры наращивают размер блока обмена информацией с внешней памятью. Да, это ускоряет линейный доступ, но чрезвычайно затормаживает случайный. Позволю себе напомнить, почему тут я так напираю на этот странный "случайный" доступ. Дело в том, что программа при выполнении любых действий нуждается в каких-то данных, а чтобы их взять нужно знать адрес расположения этих самых данных. Т.е. нужен указатель. Но и сам указатель составляет какую-то структуру данных, которую надо взять из других. Т.о., чтобы добраться до какого-то описания придется весьма здорово побегать по памяти. Если для игр процент такого "беганья" не очень велик, то различные базы данных и инженерные расчеты только этим и занимаются. Впрочем, даже такие "спокойные" программы, как PhotoShop могут очень сильно потерять в производительности. Например, если идет наложение одного слоя на другой, то контроллер памяти постоянно читает то одну область памяти, то другую. Тут ни о каком линейном чтении речи не идет.
Serj (BenchMem) (Контактный mail указан в программе)
Эта статья была прислана на наш второй конкурс.
Теги
Лента материалов раздела
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.