
WinAFC – помощник кранчера.
Введение.
<br/><br/>WinAFC
<br/>2009/01/04
<br/>Version 0.9.2
<br/>WinAFC — настраиваемая пользователем программа для настройки приоритета и привязки к ядрам приложений Windows.
<br/>Основные характеристики программы:Привязка к ядрам и настройка приоритетов согласно различным профилям, определяемых пользователем.
<br/>Профили задают имя приложения, маску процессора и опциональные параметры.
<br/>Распознавание ассиметричных процессорных конфигураций, к примеру для четырехядерных интелов программа определяет пары ядер, разделяющие общий кэш второго уровня L2.
<br/>Маски ЦП позволяют задавать логические идентификаторы (такие как PAIR), дающие преимущество на ассиметричных арх...
реклама
Введение.
WinAFC — настраиваемая пользователем программа для настройки приоритета и привязки к ядрам приложений Windows.
Основные характеристики программы:
Это почти академический перевод официальной документации README.html.
Далее пойдет вольный перевод с небольшими комментариями.
В многозадачных операционных системах с вытеснением задач процессы выполняются квантами (обычно) в несколько миллисекунд, причем выполнение каждого последующего кванта инициируется планировщиком ОС. В операционных системах семейства Linux планировщик «запоминает», к какому процессору был привязан последний квант процесса, и при выполнении следующего кванта пытается воспроизвести привязку. В семействе мягкотелых операционок такой функциональностью пренебрегли, здесь используют принцип «round robin» (круговая схема). В общих чертах суть такова:
Пусть в системе установлено четыре процессора (в диспетчере устройств четырехядерный процессор выглядит именно как четыре одинаковых процессора): CPU0, CPU1, CPU2, CPU3, и планировщику поступают «заявки» на исполнение от процессов: task1, task2, … task 9, … Выполнение квантов будет происходить примерно так:
task1 - > CPU0
task2 - > CPU1
task3 - > CPU2
task4 - > CPU3
task5 - > CPU0
task6 - > CPU1
task7 - > CPU2
task8 - > CPU3 …
Если task1 и task7 – это последовательные кванты одного потока, а архитектура процессора такова, что CPU0 и CPU2 используют физически разный кэш L2, то производительность процессора с точки зрения приложения может оказаться ниже, чем в случае, когда приложение «приклеено» к определенному CPU – возникает проблема когерентности кэш-памяти. Привязка к определенному ядру может повысить производительность приложения, если его код высоко оптимизирован и содержит малую долю обращений к пользовательскому вводу и процедурам чтения/записи на диск.
Разделяя приложения по ядрам/процессорам можно повысить их производительность, исключая совместный доступ к общим ресурсам, таким как вычислительные процессоры, кэш, системная шина и память.
Краткая инструкция по установке и настройке программы находится здесь.
Установка и запуск программы.
WinAFC не требует установки, не использует сетевые интерфейсы (в том числе виртуальные), не вносит изменения в системный реестр, не изменяет файлы, кроме файла с конфигурацией и лог-файла.
Запуск из командной строки описан ниже:
Параметр –nodetect имеет смысл, когда процессор не имеет асимметричную архитектуру, то есть является единственным процессором в системе и основан на монолитном кристалле. В таком случае запрещается использование логических идентификаторов.
Параметр –startdelay позволяет отложить выполнение программы на целое число секунд. Если прописать программу в автозагрузке, такой шаг позволит несколько ускорить запуск Windows.
Асимметричные конфигурации ЦП.
В качестве примера несимметричных конфигураций можно привести процессоры Pentium D, Core2Quad и двухсокетные AMD. В зависимости от архитектуры доступны следующие логические идентификаторы: PAIR, TRIO, QUAD- смысл которых должен быть понятен из следующей иллюстрации (пусть это будет Core2Quad Q 9550):
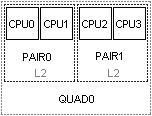
Схема обозначения логических идентификаторов
Все идентификаторы нумеруются, начиная с нуля, причем доступны сложные конструкции вида:
PAIR1::CPU0 - физически указывает на CPU2 из иллюстрации;
QUAD0::PAIR0 – указывает на пару ядер CPU0+CPU1.
Для обозначения всех доступных процессоров можно использовать идентификатор ALL.
Замечу, что идентификатор QUAD используется только для многопроцессорных конфигураций.
Файл конфигурации.
Начнем с того, что в файле конфигурации допустимо использовать комментарии – такие последовательности символов, которые игнорируются программой и служат только для облегчения понимания кода, начинаются со знака # и заканчиваются в конце строки.
Рассмотрим файл конфигурации affinityinput.txt, данный по умолчанию:
Теперь подробнее о профилях приложений. Профиль имеет следующую форму:
ПутьКПриложению := МаскаПроцессоров [набор атрибутов]
Путь к приложению может иметь следующие виды:
CPU0+CPU1
Опциональные атрибуты:
assign=<int>
Целое значение, строго большее нуля, но не превосходящее количества процессоров в системе. Указывает количество вычислительных процессоров, доступных приложению, например, assign=2.
policy=(ROUNDROBIN | BALANCED | PSEUDOBALANCED)
Стратегия распределения процессов по ядрам. По умолчанию, ROUNDROBIN, процессы распределяются «по кругу»: пусть есть набор ядер CPU0, CPU1, CPU2, CPU3 и набор процессов task1, task2, task3, …, taskN, тогда процессы распределятся следующим образом:
CPU0 <- task1, task5, task9, …
CPU1 <- task2, task6, task10, …
CPU2 <- task3, task7, task11, …
CPU3 <- task4, task8, task12, …
При такой стратегии ожидается, что на каждом ядре будет работать примерно равное количество процессов, однако в таком случае никак не учитывается потребность в ресурсах каждого приложения. К примеру, на CPU0 нагрузка может быть стопроцентной, а на CPU1 лишь в 20 процентов.
Стратегии BALANCED и PSEUDOBALANCED распределяют процессы по ядрам с учетом доступного количества ресурсов.
Стратегия BALANCED: процесс с максимальной потребностью в ресурсах прикрепляется к ядру с минимальной загрузкой. Чуть менее ресурсоемкий процесс прикрепляется к чуть более нагруженному ядру, и так далее пока не будут прикреплены все процессы.
Стратегия PSEUDOBALANCED сочетает в себе принципы двух других стратегий, стремясь распределить процессы с учетом загрузки процессоров и в то же время равномерно по ядрам. Допустим есть три ядра (CPU) и несколько процессов (task). Отсортируем ядра в порядке увеличения загруженности: CPU_LOW, CPU_MID, CPU_HI, а процессы отсортируем в порядке уменьшения потребности в ресурсах: task1, task2, task3, … тогда процессы будут распределены следующим образом:
CPU_LOW <- task1, task6, task7,…
CPU_MID <-- task2, task5, task8,…
CPU_HI <--- task3, task4, task9,task10,…
Скажем так: реверсивный порядок заполнения (или заполнение змейкой).
Балансирующие стратегии имеют смысл только тогда, когда маска процессоров указывает более чем на одно ядро. К тому же, не рекомендуется для одного набора ядер использовать несколько балансирующих стратегий, т.е. если для PAIR1 привязан некий набор процессов с флагом PSEUDOBALANCED, то другие процессы, требующие балансировки желательно «вешать» на остальные процессоры.
resource=(MEMUSE | CPUUSE)
Этот параметр указывает, на использование какого ресурса ориентироваться при использовании балансирующих стратегий. resource=MEMUSE – уравновешивает процессы по используемой памяти. resource=CPUUSE – уравновешивает по потреблению процессорного времени (в расчет берется использованное процессорное время за последние 30 секунд). По умолчанию используется CPUUSE.
threads=(yes | no)
Параметр threads указывает, должна ли программа управлять соответствием процессов для каждого потока в искомых процессах. По умолчанию, no.
Если установлено значение threads=yes, то настройки привязки применяются для всех потоков каждого из процессов. При этом возникает следующее ограничение: если используется балансирующая стратегия, то для параметра resource возможно только значение CPUUSE.
priority=(Unchanged | Idle | BelowNormal | Normal | AboveNormal | High | Realtime)
Предусмотрена возможность изменения приоритета процесса, однако следует помнить, что не все процессы безболезненно переживают смену приоритета «на лету». По умолчанию используется значение Unchanged (то есть без изменения). Чтобы изменить только приоритет процесса без изменения его привязки к ядрам вместо маски процессора можно использовать слово SKIP.
force=(yes | no)
С установленным в значение yes параметром force WinAFC применяет параметры соответствия процессоров каждый раз, когда проверяет список процессов, то есть каждые TimeInterval секунд. При значении параметра ‘no’ соответствие процессоров применяется к процессу только один раз (при его обнаружении).
Несколько примеров.
Все примеры будут приведены для интеловского четырехядерника, состоящего из двух пар ядер с общим кэшем L2.
1. Рассмотрим запуск двух виртуальных машин, предоставленных VMWare. Известно, что такие виртуальные машины способны использовать два ядра. Таким образом, выгодно локализовать каждую машину на паре ядер с общим L2:
*\vmware-vmx.exe := PAIR0+PAIR1 [assign=2]
Первому запущенному процессу «достанется» PAIR0, а второму – PAIR1.
2. Следующий пример, запуск многоядерной версии клиента проекта folding-at-home, известного как WinSMP. Этот клиент создает четыре рабочих процесса, которые выгодно распределить по одному на ядро так, чтобы максимально равномерно задействовать кеш-память. Для этого разумно использовать балансирующую политику:
С:\FahSmp\FahCore_*.exe := PAIR0::CPU1+PAIR1+PAIR0::CPU0 [assign=1, resource=MEMUSE, policy=PSEUDOBALANCED]
всё пишется СТРОГО ОДНОЙ СТРОКОЙ!
Примечание. Бонусный СМП-клиент (А3) не требует привязки процессоров!
В таком варианте процесс, использующий более всего памяти, «приклеится» к ядру PAIR0::CPU1, два чуть менее «прожорливых» процесса «сядут» на два ядра из PAIR1, а процесс, использующий менее всего памяти, - на PAIR0::CPU0. Таким образом, на PAIR0 будут крутиться самый прожорливый и самый легкий процессы, а на PAIR1 будут работать середнячки.Параметр assign=1 указывает, что каждый процесс будет привязан только к одному ядру, resource=MEMUSE определяет, что процессы сортируются по потреблению памяти, а PSEUDOBALANCED гарантирует, что все четыре процесса (если их четыре конечно) распределятся по одному на ядро.
И еще раз :). Предполагается, что по имени процесса (в котором используется групповой символ *) будет обнаружено четыре процесса. Каждый из процессов будет привязан к одному ядру процессора (assign=1). Благодаря параметру policy=PSEUDOBALANCED все эти процессы будут отсортированы по убыванию потребляемой памяти (resource=MEMUSE) и распределены по ядрам, указанным в маске процессоров по порядку. Напомню, что маской процессоров в указанном примере является последовательность логических идентификаторов PAIR0::CPU1+PAIR1+PAIR0::CPU0.
3. Известно, что один клиент WinSMP не способен нагрузить процессор на 100%, хотя судя по диспетчеру задач, загрузка выглядит стопроцентной. Для более эффективного использования процессора можно запускать два или четыре клиента.
В случае запуска двух клиентов, автор программы предлагает использовать следующие профили:
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
В принципе здесь всё то же самое, что и в предыдущем примере, только каждый клиент привязывается только к одной паре ядер, используя свой L2, а на каждом ядре выполняется по 2 процесса. Поскольку кэш-память разделяема между двумя ядрами одного кристалла, сортировка по MEMUSE теряет смысл и параметр resource можно опускать, т.к. по умолчанию он CPUUSE. Поэтому можно использовать упрощенную запись:
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1,policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR1 [assign=1,policy=PSEUDOBALANCED]
4. Ну и наконец, рассмотрим вариант запуска четырех клиентов. Здесь можно предложить два варианта:
С:\FahSmp1\FahCore_*.exe := CPU0 [force=yes]
С:\FahSmp2\FahCore_*.exe := CPU1 [force=yes]
С:\FahSmp3\FahCore_*.exe := CPU2 [force=yes]
С:\FahSmp4\FahCore_*.exe := CPU3 [force=yes]
и
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp3\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp4\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
Опыт кранчеров показывает, что первый вариант более эффективен с точки зрения производительности.
Использование параметра force=yes я бы рекомендовал для любых конфигураций WinSMP.
5. Рассмотрим экзотический вариант. Допустим у вас n-ядерный процессор и вы хотите добиться наилучшего результата в тесте SuperPI. Тогда можно поступить следующим образом: "заставить" все приложения, кроме SuperPI, выполняться на первом ядре, а сам SuperPI привязать, например, к третьему ядру:
C:\Program Files\SuperPI\* := CPU2 [threads=yes, force=yes]
* := CPU0
Учтите, что не все приложения с радостью откликнутся на изменения привязки. В силу того, что некоторые приложения защищены системой от посторонних воздействий, их соответствие не удастся изменить.
И ещё один момент. Если вы убедились в полной работоспособности вашей конфигурации и вам необходима частая проверка соответствий процессоров [TimeInterval=1,2,3], имеет смысл отказаться от записи логов:
WarningLevel = 0
ConsoleLogLevel = 0
FileLogLevel = 0
Ссылки по теме.
Домашняя страница проекта WinAFC (на странице загрузки присутствуют отдельные версии для x86 и x64 систем)
Советы и маленькие хитрости начинающему кранчеру Часть II. (c) Anubias.
[TSC!] Обсуждение WinSMP клиента F@H (теперь beta!)
WinAFC
2009/01/04
Version 0.9.2
2009/01/04
Version 0.9.2
WinAFC — настраиваемая пользователем программа для настройки приоритета и привязки к ядрам приложений Windows.
Основные характеристики программы:
- Привязка к ядрам и настройка приоритетов согласно различным профилям, определяемых пользователем.
- Профили задают имя приложения, маску процессора и опциональные параметры.
- Распознавание ассиметричных процессорных конфигураций, к примеру для четырехядерных интелов программа определяет пары ядер, разделяющие общий кэш второго уровня L2.
- Маски ЦП позволяют задавать логические идентификаторы (такие как PAIR), дающие преимущество на ассиметричных архитектурах центральных процессоров.
- Привязка к ядрам осуществляется как для процессов, так и для соответствующих им потоков.
- Привязка к ядрам для распараллеленных приложений может определяться с помощью двух стратегий: балансировки или «round robin».
- Балансирование основывается либо на использовании памяти, либо на использовании процессора.
Чем не является WinAFC: - WinAFC не заменяет собой планировщик задач операционной системы. В отличие от него, программа не имеет низкоуровневый доступ к процессам и потокам. Программа скорее является дополнением к системному планировщику, указывая на те ядра процессора, которые нужно зарезервировать для различных приложений.
- WinAFC не выполняет операции по привязке процессов к ядрам автоматически. Поскольку программа написана без прицела на конкретное приложение, задача выбора настраиваемых приложений и настройки их выполнения целиком ложится на пользователя.
Это почти академический перевод официальной документации README.html.
Далее пойдет вольный перевод с небольшими комментариями.
В многозадачных операционных системах с вытеснением задач процессы выполняются квантами (обычно) в несколько миллисекунд, причем выполнение каждого последующего кванта инициируется планировщиком ОС. В операционных системах семейства Linux планировщик «запоминает», к какому процессору был привязан последний квант процесса, и при выполнении следующего кванта пытается воспроизвести привязку. В семействе мягкотелых операционок такой функциональностью пренебрегли, здесь используют принцип «round robin» (круговая схема). В общих чертах суть такова:
Пусть в системе установлено четыре процессора (в диспетчере устройств четырехядерный процессор выглядит именно как четыре одинаковых процессора): CPU0, CPU1, CPU2, CPU3, и планировщику поступают «заявки» на исполнение от процессов: task1, task2, … task 9, … Выполнение квантов будет происходить примерно так:
task1 - > CPU0
task2 - > CPU1
task3 - > CPU2
task4 - > CPU3
task5 - > CPU0
task6 - > CPU1
task7 - > CPU2
task8 - > CPU3 …
Если task1 и task7 – это последовательные кванты одного потока, а архитектура процессора такова, что CPU0 и CPU2 используют физически разный кэш L2, то производительность процессора с точки зрения приложения может оказаться ниже, чем в случае, когда приложение «приклеено» к определенному CPU – возникает проблема когерентности кэш-памяти. Привязка к определенному ядру может повысить производительность приложения, если его код высоко оптимизирован и содержит малую долю обращений к пользовательскому вводу и процедурам чтения/записи на диск.
Разделяя приложения по ядрам/процессорам можно повысить их производительность, исключая совместный доступ к общим ресурсам, таким как вычислительные процессоры, кэш, системная шина и память.
Краткая инструкция по установке и настройке программы находится здесь.
Установка и запуск программы.
WinAFC не требует установки, не использует сетевые интерфейсы (в том числе виртуальные), не вносит изменения в системный реестр, не изменяет файлы, кроме файла с конфигурацией и лог-файла.
Запуск из командной строки описан ниже:
WinAFC.exe [опции] [ИмяФайла]
-nodetect не выполнять анализ архитектуры процессора
-once задать соответствие процессоров и прекратить работу
-startdelay=n отложить выполнение программы на n секунд
-minimized спрятать консоль при старте программы
-hideicon не показывать иконку в трее и не создавать консоль.
inputFileName имя файла с конфигурацией. По умолчанию, 'affinityinput.txt'Параметр –nodetect имеет смысл, когда процессор не имеет асимметричную архитектуру, то есть является единственным процессором в системе и основан на монолитном кристалле. В таком случае запрещается использование логических идентификаторов.
Параметр –startdelay позволяет отложить выполнение программы на целое число секунд. Если прописать программу в автозагрузке, такой шаг позволит несколько ускорить запуск Windows.
Асимметричные конфигурации ЦП.
В качестве примера несимметричных конфигураций можно привести процессоры Pentium D, Core2Quad и двухсокетные AMD. В зависимости от архитектуры доступны следующие логические идентификаторы: PAIR, TRIO, QUAD- смысл которых должен быть понятен из следующей иллюстрации (пусть это будет Core2Quad Q 9550):
Схема обозначения логических идентификаторов
Все идентификаторы нумеруются, начиная с нуля, причем доступны сложные конструкции вида:
PAIR1::CPU0 - физически указывает на CPU2 из иллюстрации;
QUAD0::PAIR0 – указывает на пару ядер CPU0+CPU1.
Для обозначения всех доступных процессоров можно использовать идентификатор ALL.
Замечу, что идентификатор QUAD используется только для многопроцессорных конфигураций.
Файл конфигурации.
Начнем с того, что в файле конфигурации допустимо использовать комментарии – такие последовательности символов, которые игнорируются программой и служат только для облегчения понимания кода, начинаются со знака # и заканчиваются в конце строки.
Рассмотрим файл конфигурации affinityinput.txt, данный по умолчанию:
цитата:
#
# Это комментарий
#
# Тестовый режим предназначен для отладки.
# Если установлено значение 1, то программа проверит правильность записи
# команд, но не будет выполнять действий по соответствию процессоров и
# изменению приоритетов. Чтобы отключить тестовый режим достаточно
# удалить строку, идущую ниже
TestMode = 1
# Далее идут флаги, управляющие подробностью логов
# Уровень отображения ошибок. По умолчанию, 2.
# При значении 0 ошибки игнорируются
#WarningLevel = 2
# Логи, отображаемые в консоли и файле affinitylog.txt
# По умолчанию имеют значение 3
# Уровень подробности изменяется от 0 до 9:
# 0 – нет лога
# 9 – наиболее подробный лог
ConsoleLogLevel = 4
FileLogLevel = 3
# Можно задать общий уровень сразу для обоих логов
#LogLevel = 3
# Интервал (в секундах) получения списка процессов и применения к ним настроек
# привязки процессоров, по умолчанию 30
#TimeInterval = 30
##################################################
## Профили приложений
##################################################
#
# Профиль записывается одной строкой
# Профиль включает в себя имя приложения, маску процессоров, опции
# Формат следующий:
# C:\Путь\К\Приложению := CPU0+CPU1 [attr1=val1,attr2=val2]
Теперь подробнее о профилях приложений. Профиль имеет следующую форму:
ПутьКПриложению := МаскаПроцессоров [набор атрибутов]
Путь к приложению может иметь следующие виды:
- Полный путь к приложению, с указанием точного имени:
C:\Program Files\fahsmp1\ Folding@home-Win32-x86.exe - Полный путь к приложению, но имя приложения с маской:
C:\Program Files\Folding@home\Folding@home-gpu\FahCore_*.exe
- действия будут применены и для FahCore_11.exe, и для FahCore_13.exe, и для любых других, подпадающих под маску FahCore_*.exe - Полный путь к папке, содержащей несколько приложений:
C:\Program Files\Folding@home\Folding@home-x86\*
- будут настроены все приложения, запущенные из указанной папки - Имя приложения
*\FahCore_a1.exe
- действия будут применены ко всем процессам с именем FahCore_a1.exe, не зависимо от того, из какой папки они запущены.
CPU0+CPU1
Опциональные атрибуты:
assign=<int>
Целое значение, строго большее нуля, но не превосходящее количества процессоров в системе. Указывает количество вычислительных процессоров, доступных приложению, например, assign=2.
policy=(ROUNDROBIN | BALANCED | PSEUDOBALANCED)
Стратегия распределения процессов по ядрам. По умолчанию, ROUNDROBIN, процессы распределяются «по кругу»: пусть есть набор ядер CPU0, CPU1, CPU2, CPU3 и набор процессов task1, task2, task3, …, taskN, тогда процессы распределятся следующим образом:
CPU0 <- task1, task5, task9, …
CPU1 <- task2, task6, task10, …
CPU2 <- task3, task7, task11, …
CPU3 <- task4, task8, task12, …
При такой стратегии ожидается, что на каждом ядре будет работать примерно равное количество процессов, однако в таком случае никак не учитывается потребность в ресурсах каждого приложения. К примеру, на CPU0 нагрузка может быть стопроцентной, а на CPU1 лишь в 20 процентов.
Стратегии BALANCED и PSEUDOBALANCED распределяют процессы по ядрам с учетом доступного количества ресурсов.
Стратегия BALANCED: процесс с максимальной потребностью в ресурсах прикрепляется к ядру с минимальной загрузкой. Чуть менее ресурсоемкий процесс прикрепляется к чуть более нагруженному ядру, и так далее пока не будут прикреплены все процессы.
Стратегия PSEUDOBALANCED сочетает в себе принципы двух других стратегий, стремясь распределить процессы с учетом загрузки процессоров и в то же время равномерно по ядрам. Допустим есть три ядра (CPU) и несколько процессов (task). Отсортируем ядра в порядке увеличения загруженности: CPU_LOW, CPU_MID, CPU_HI, а процессы отсортируем в порядке уменьшения потребности в ресурсах: task1, task2, task3, … тогда процессы будут распределены следующим образом:
CPU_LOW <- task1, task6, task7,…
CPU_MID <-- task2, task5, task8,…
CPU_HI <--- task3, task4, task9,task10,…
Скажем так: реверсивный порядок заполнения (или заполнение змейкой).
Балансирующие стратегии имеют смысл только тогда, когда маска процессоров указывает более чем на одно ядро. К тому же, не рекомендуется для одного набора ядер использовать несколько балансирующих стратегий, т.е. если для PAIR1 привязан некий набор процессов с флагом PSEUDOBALANCED, то другие процессы, требующие балансировки желательно «вешать» на остальные процессоры.
resource=(MEMUSE | CPUUSE)
Этот параметр указывает, на использование какого ресурса ориентироваться при использовании балансирующих стратегий. resource=MEMUSE – уравновешивает процессы по используемой памяти. resource=CPUUSE – уравновешивает по потреблению процессорного времени (в расчет берется использованное процессорное время за последние 30 секунд). По умолчанию используется CPUUSE.
threads=(yes | no)
Параметр threads указывает, должна ли программа управлять соответствием процессов для каждого потока в искомых процессах. По умолчанию, no.
Если установлено значение threads=yes, то настройки привязки применяются для всех потоков каждого из процессов. При этом возникает следующее ограничение: если используется балансирующая стратегия, то для параметра resource возможно только значение CPUUSE.
priority=(Unchanged | Idle | BelowNormal | Normal | AboveNormal | High | Realtime)
Предусмотрена возможность изменения приоритета процесса, однако следует помнить, что не все процессы безболезненно переживают смену приоритета «на лету». По умолчанию используется значение Unchanged (то есть без изменения). Чтобы изменить только приоритет процесса без изменения его привязки к ядрам вместо маски процессора можно использовать слово SKIP.
force=(yes | no)
С установленным в значение yes параметром force WinAFC применяет параметры соответствия процессоров каждый раз, когда проверяет список процессов, то есть каждые TimeInterval секунд. При значении параметра ‘no’ соответствие процессоров применяется к процессу только один раз (при его обнаружении).
Несколько примеров.
Все примеры будут приведены для интеловского четырехядерника, состоящего из двух пар ядер с общим кэшем L2.
1. Рассмотрим запуск двух виртуальных машин, предоставленных VMWare. Известно, что такие виртуальные машины способны использовать два ядра. Таким образом, выгодно локализовать каждую машину на паре ядер с общим L2:
*\vmware-vmx.exe := PAIR0+PAIR1 [assign=2]
Первому запущенному процессу «достанется» PAIR0, а второму – PAIR1.
2. Следующий пример, запуск многоядерной версии клиента проекта folding-at-home, известного как WinSMP. Этот клиент создает четыре рабочих процесса, которые выгодно распределить по одному на ядро так, чтобы максимально равномерно задействовать кеш-память. Для этого разумно использовать балансирующую политику:
С:\FahSmp\FahCore_*.exe := PAIR0::CPU1+PAIR1+PAIR0::CPU0 [assign=1, resource=MEMUSE, policy=PSEUDOBALANCED]
всё пишется СТРОГО ОДНОЙ СТРОКОЙ!
Примечание. Бонусный СМП-клиент (А3) не требует привязки процессоров!
В таком варианте процесс, использующий более всего памяти, «приклеится» к ядру PAIR0::CPU1, два чуть менее «прожорливых» процесса «сядут» на два ядра из PAIR1, а процесс, использующий менее всего памяти, - на PAIR0::CPU0. Таким образом, на PAIR0 будут крутиться самый прожорливый и самый легкий процессы, а на PAIR1 будут работать середнячки.Параметр assign=1 указывает, что каждый процесс будет привязан только к одному ядру, resource=MEMUSE определяет, что процессы сортируются по потреблению памяти, а PSEUDOBALANCED гарантирует, что все четыре процесса (если их четыре конечно) распределятся по одному на ядро.
И еще раз :). Предполагается, что по имени процесса (в котором используется групповой символ *) будет обнаружено четыре процесса. Каждый из процессов будет привязан к одному ядру процессора (assign=1). Благодаря параметру policy=PSEUDOBALANCED все эти процессы будут отсортированы по убыванию потребляемой памяти (resource=MEMUSE) и распределены по ядрам, указанным в маске процессоров по порядку. Напомню, что маской процессоров в указанном примере является последовательность логических идентификаторов PAIR0::CPU1+PAIR1+PAIR0::CPU0.
3. Известно, что один клиент WinSMP не способен нагрузить процессор на 100%, хотя судя по диспетчеру задач, загрузка выглядит стопроцентной. Для более эффективного использования процессора можно запускать два или четыре клиента.
В случае запуска двух клиентов, автор программы предлагает использовать следующие профили:
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
В принципе здесь всё то же самое, что и в предыдущем примере, только каждый клиент привязывается только к одной паре ядер, используя свой L2, а на каждом ядре выполняется по 2 процесса. Поскольку кэш-память разделяема между двумя ядрами одного кристалла, сортировка по MEMUSE теряет смысл и параметр resource можно опускать, т.к. по умолчанию он CPUUSE. Поэтому можно использовать упрощенную запись:
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1,policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR1 [assign=1,policy=PSEUDOBALANCED]
4. Ну и наконец, рассмотрим вариант запуска четырех клиентов. Здесь можно предложить два варианта:
С:\FahSmp1\FahCore_*.exe := CPU0 [force=yes]
С:\FahSmp2\FahCore_*.exe := CPU1 [force=yes]
С:\FahSmp3\FahCore_*.exe := CPU2 [force=yes]
С:\FahSmp4\FahCore_*.exe := CPU3 [force=yes]
и
С:\FahSmp1\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp2\FahCore_*.exe := PAIR0 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp3\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
С:\FahSmp4\FahCore_*.exe := PAIR1 [assign=1, resource=CPUUSE, policy=PSEUDOBALANCED]
Опыт кранчеров показывает, что первый вариант более эффективен с точки зрения производительности.
Использование параметра force=yes я бы рекомендовал для любых конфигураций WinSMP.
5. Рассмотрим экзотический вариант. Допустим у вас n-ядерный процессор и вы хотите добиться наилучшего результата в тесте SuperPI. Тогда можно поступить следующим образом: "заставить" все приложения, кроме SuperPI, выполняться на первом ядре, а сам SuperPI привязать, например, к третьему ядру:
C:\Program Files\SuperPI\* := CPU2 [threads=yes, force=yes]
* := CPU0
Учтите, что не все приложения с радостью откликнутся на изменения привязки. В силу того, что некоторые приложения защищены системой от посторонних воздействий, их соответствие не удастся изменить.
И ещё один момент. Если вы убедились в полной работоспособности вашей конфигурации и вам необходима частая проверка соответствий процессоров [TimeInterval=1,2,3], имеет смысл отказаться от записи логов:
WarningLevel = 0
ConsoleLogLevel = 0
FileLogLevel = 0
Ссылки по теме.
Домашняя страница проекта WinAFC (на странице загрузки присутствуют отдельные версии для x86 и x64 систем)
Советы и маленькие хитрости начинающему кранчеру Часть II. (c) Anubias.
[TSC!] Обсуждение WinSMP клиента F@H (теперь beta!)
Лента материалов
Правила размещения комментариев
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.