
SD WebUI Neuro: Грибная фантазия нейронных сетей

Сборку Stable Diffusion web UI Neuro (SD WebUI Neuro) я конечно сделал, теперь пришло время показать что это вообще такое и для чего.
Сборка Stable Diffusion web UI Neuro: Доступная и простая в использовании нейросеть. Часть 2

Для чего я создал сборку Stable Diffusion web UI Neuro:
реклама
1) Независимость. Сборка работает даже на системах без доступа к интернету, ведь я позаботился чтобы зависимости оказались вместе с приложением.
2) Портативность. Сборку можно в любой момент скопировать куда угодно, даже на USB накопитель.
3) Windows 7. Да. моя сборка работает в "устаревшей" Windows 7.
реклама
4) Простота. Для старта SD WebUI Neuro достаточно запустить BAT файл "Start WebUI", всё остальное не забота пользователя, хотя при желании любой может посмотреть как оно реализовано внутри.
5) Настройки. Само собой я предварительно настроил сборку, ибо в первую очередь делал её для себя, это избавляет от лишней рутины когда приложение нужно просто скачать и начать использовать.
Найти сборку можно в репозитории: ( https://github.com/Shedou/Neuro ).
-
--
---
Начало
Для начала нужно запустить Stable Diffusion web UI, тут ничего сложного, выбираю файл обычного запуска, есть ещё вариант работы с помощью ЦП, но Ryzen 7 2700X медленнее видеокарты GTX 1070, так что буду использовать нормальный режим работы с помощью видеокарты:
реклама
И да, видеокарты AMD не поддерживаются данной сборкой, но вы всегда можете собрать всё вручную по инструкциям в репозитории AUTOMATIC1111 - ( https://github.com/AUTOMATIC1111/stable-diffusion-webui ).
В общем запускаю SD WebUI и в браузере открылась новая вкладка, первым делом меня встречает режим txt2img (text to image) с кучей всяких ползунков и полей ввода:
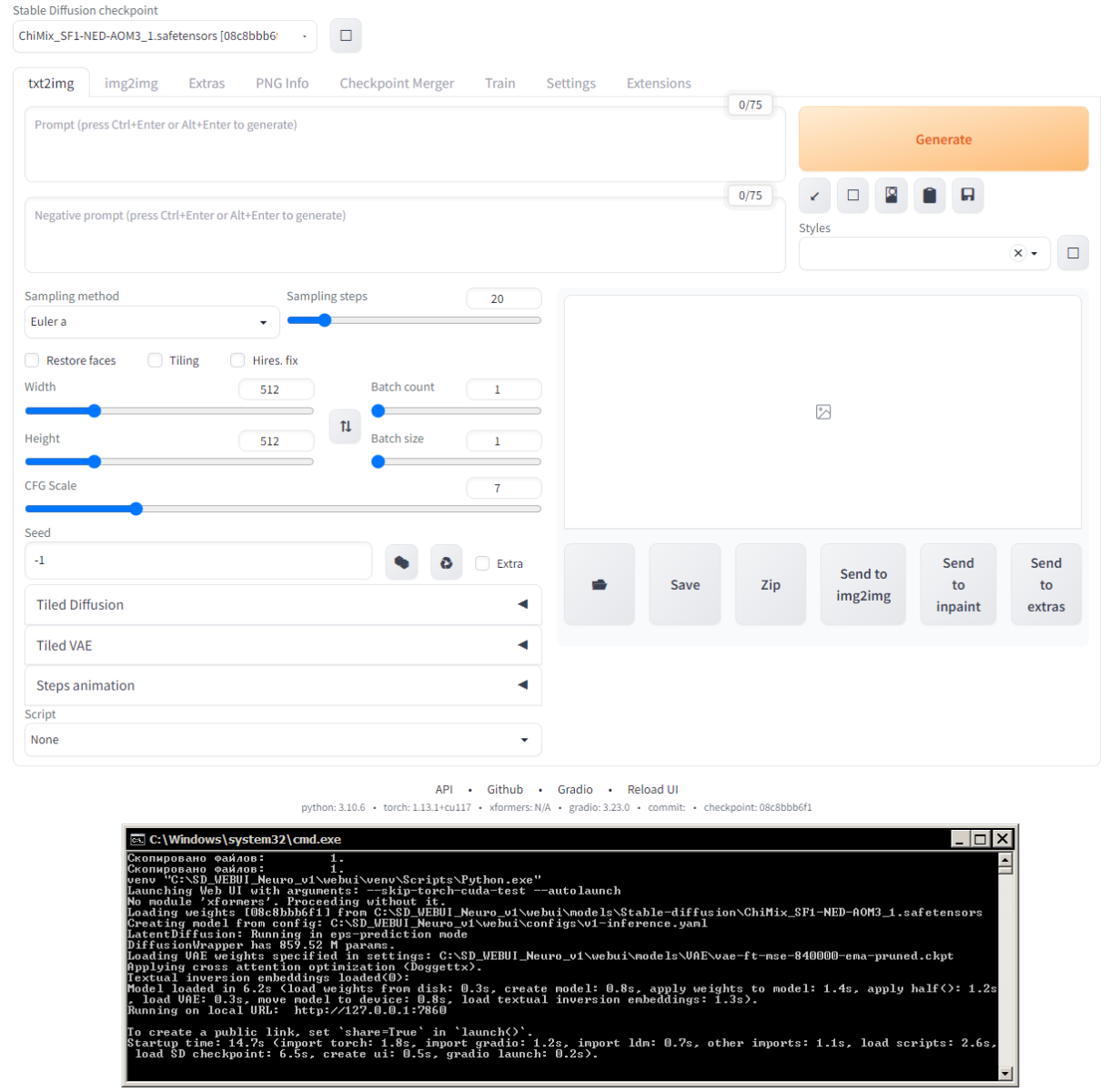
А теперь я кратко пройдусь по основным параметрам:
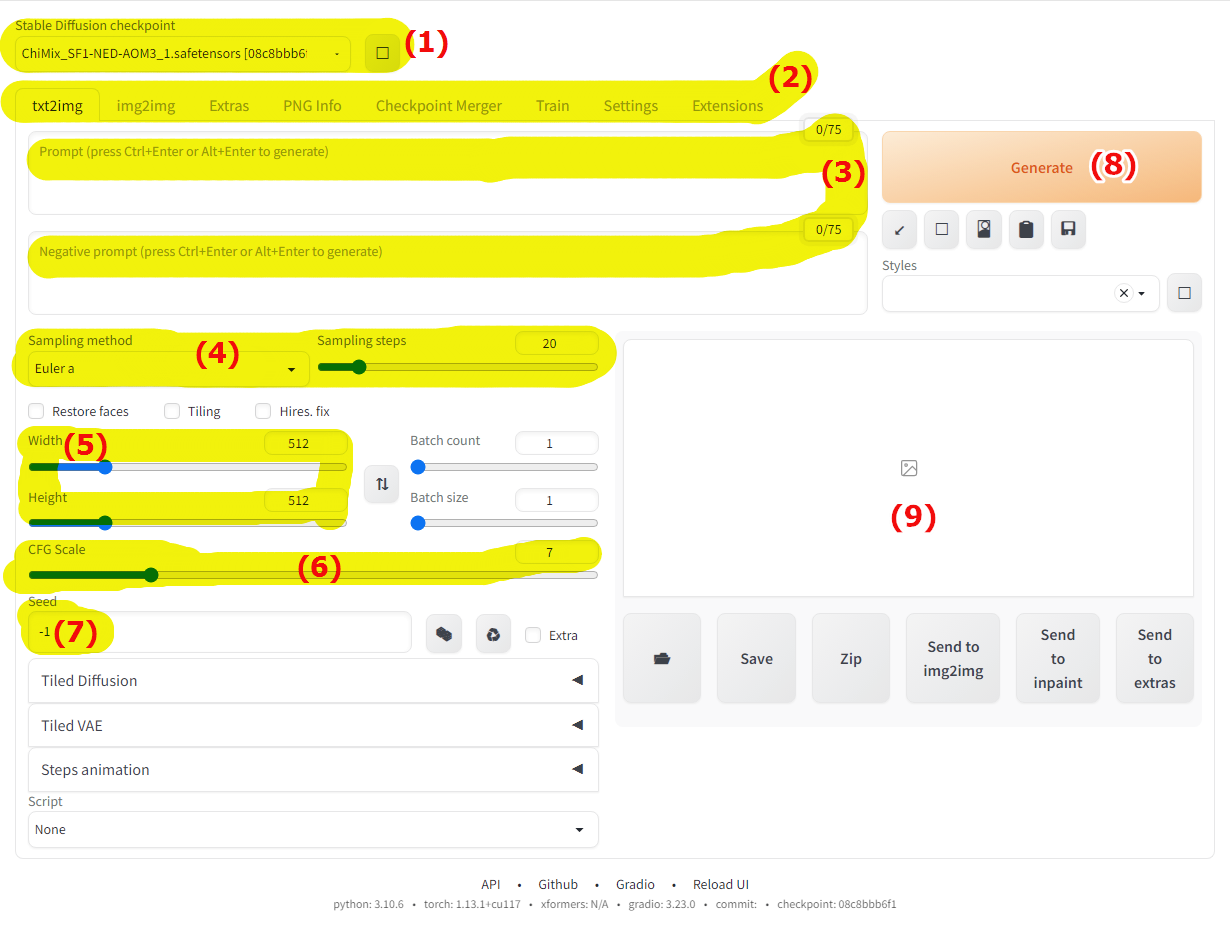
1) Текущая используемая модель (checkpoint), без модели невозможно нарисовать изображение, именно от модели зависит, как и что будет нарисовано, найти модели можно на huggingface.co, civitai.com и прочих подобных ресурсах, но у меня уже есть модель и она уже выбрана.
реклама
2) Здесь вкладки, основная txt2img (из текста сделать картинку), есть так же img2img (из картинки сделать картинку), Extras (всякое полезное для обработки изображений), PNG Info (информация о файле), Checkpoint Merger (слияние нескольких моделей в одну), Train (здесь можно создать гиперсеть на основе изображений), в конце идут настройки (Settings) и расширения (Extensions).
3) Основные поля ввода, в поле Promt нужно вписать что рисовать, а в поле Negative promt вписать что не рисовать.
4) Далее идет метод сэмплирования и количество проходов (шагов), изначально указано 20 шагов, обычно больше - лучше, но чем больше проходов, тем больше времени нужно на работу по естественным причинам, да и не всегда увеличение количества проходов положительно влияет на результат.
5) Ширина и высота генерируемого изображения, напрямую влияет на требуемый объем памяти для работы, видеокарта с 8 ГБ памяти способна сгенерировать изображение размером примерно 1600x1600 при условии, что на фоне нет никаких приложений занимающих память видеокарту, например браузер с включенным "аппаратным ускорением".
6) Эта настройка задаёт насколько строго нейросеть будет следовать введенному тексту, чем выше значение, тем строже будет следовать тому что пользователь написал, при минимальных значениях нейросеть может рисовать что попало.
7) Далее идёт "зерно", по умолчанию оно случайно создается при каждой генерации, но число можно вписать и руками, на его основе будет сгенерировано изображение.
8) Кнопка "сгенерировать", не вижу смысля объяснять что делает эта кнопка...
9) Здесь будет результат работы, в процессе генерации будут отображены промежуточные изображения.
Пожалуй на этом хватит болтовни, пора приступать к грибным забавам.
-
--
---
txt2img
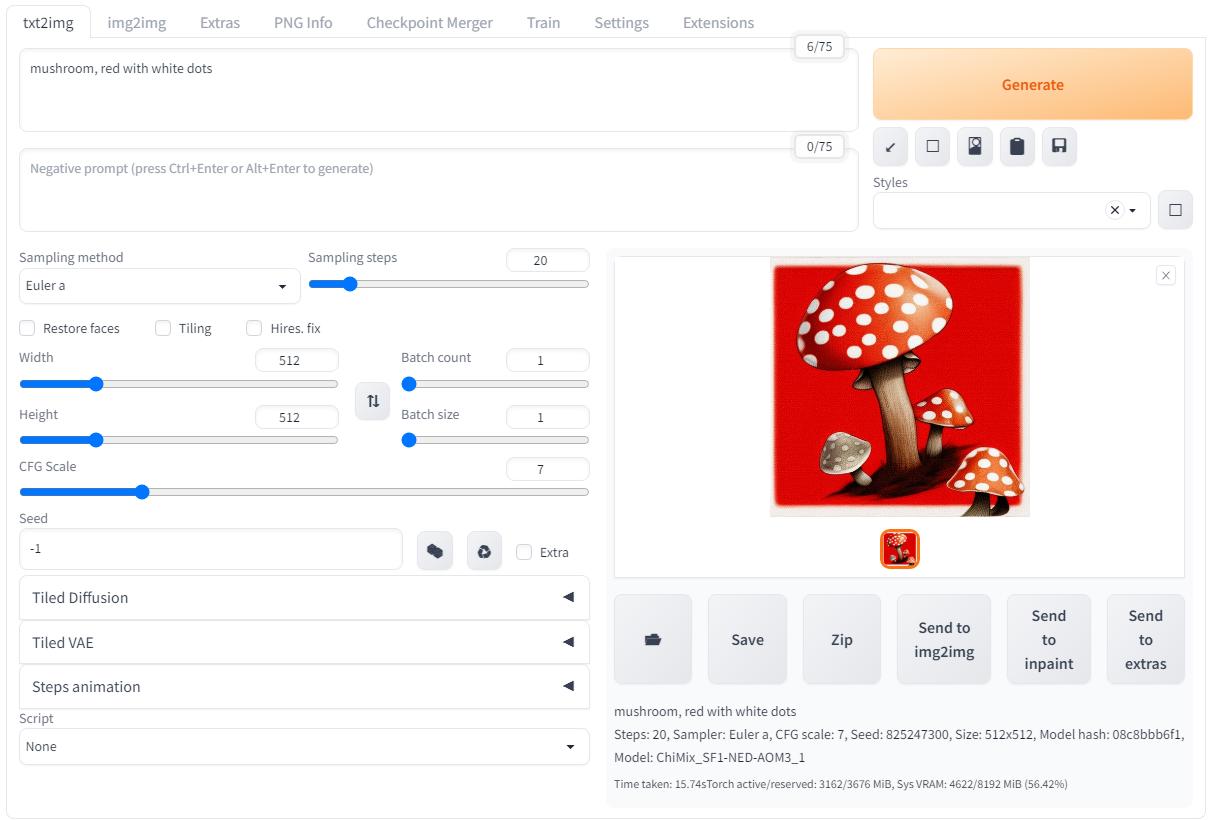
Конечно же начну с генерации изображения на основе текста.
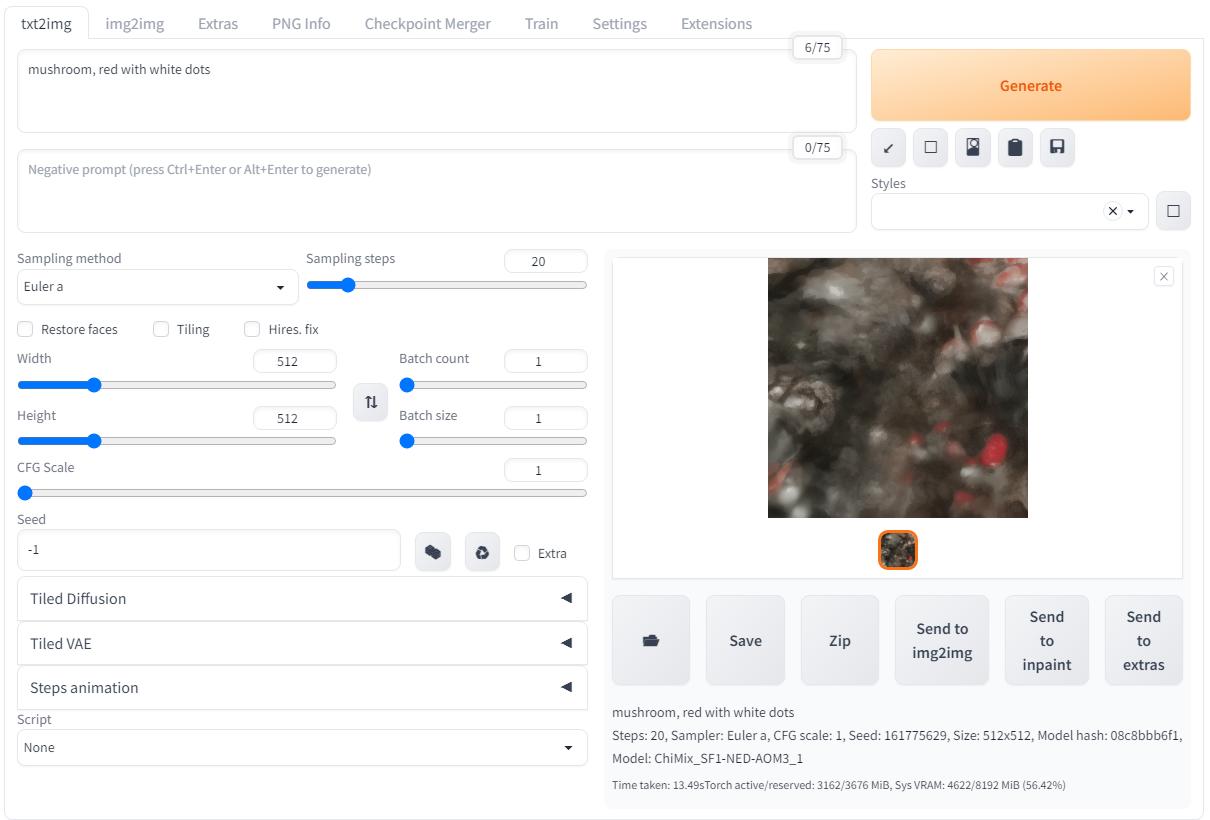
Ввожу "mushroom, red with white dots" и генерирую! Получаю в итоге пятнистые грибы, вполне логично, но если поиграть с параметром CFG Scale тогда в результатах происходит что-то странное:
 |
 |
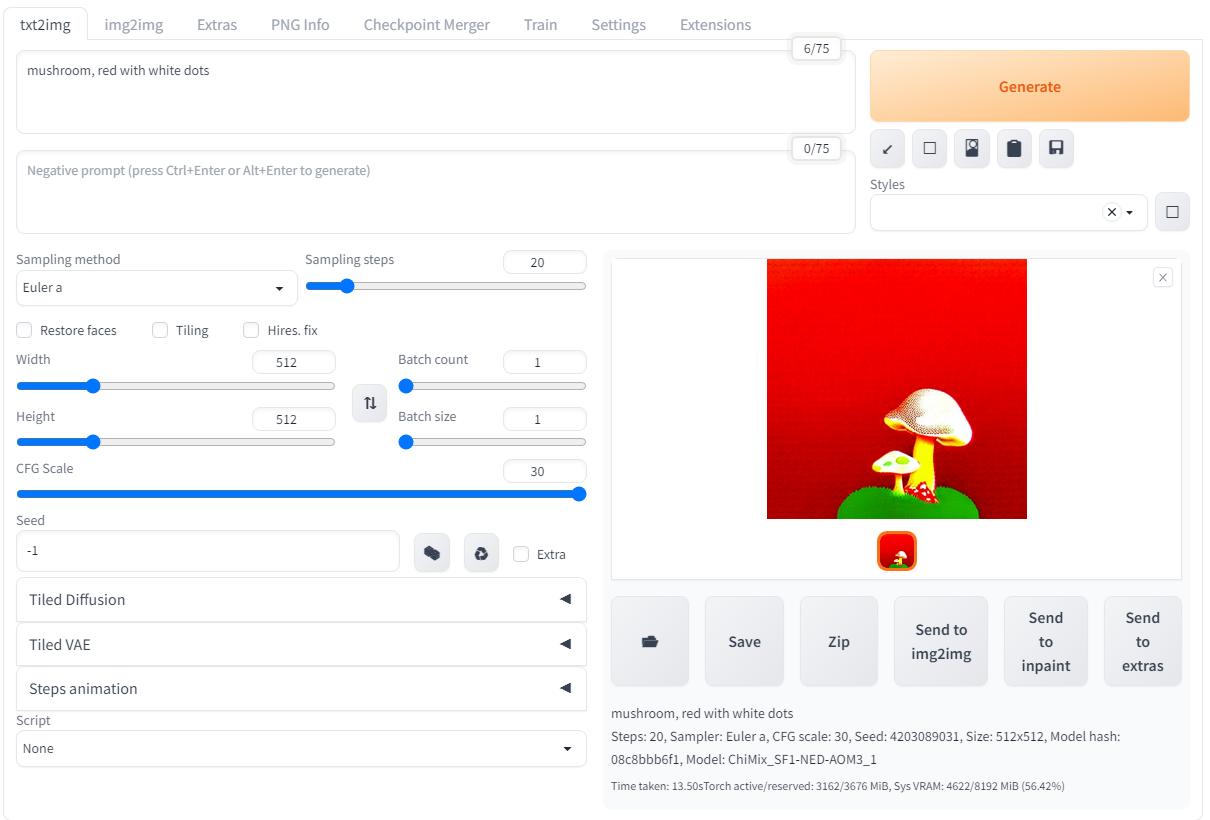 |
При маленьком значении CFG Scale результат получился непонятной серой кашей, а когда выкрутил значение до максимума результат получился слишком "плоский"...
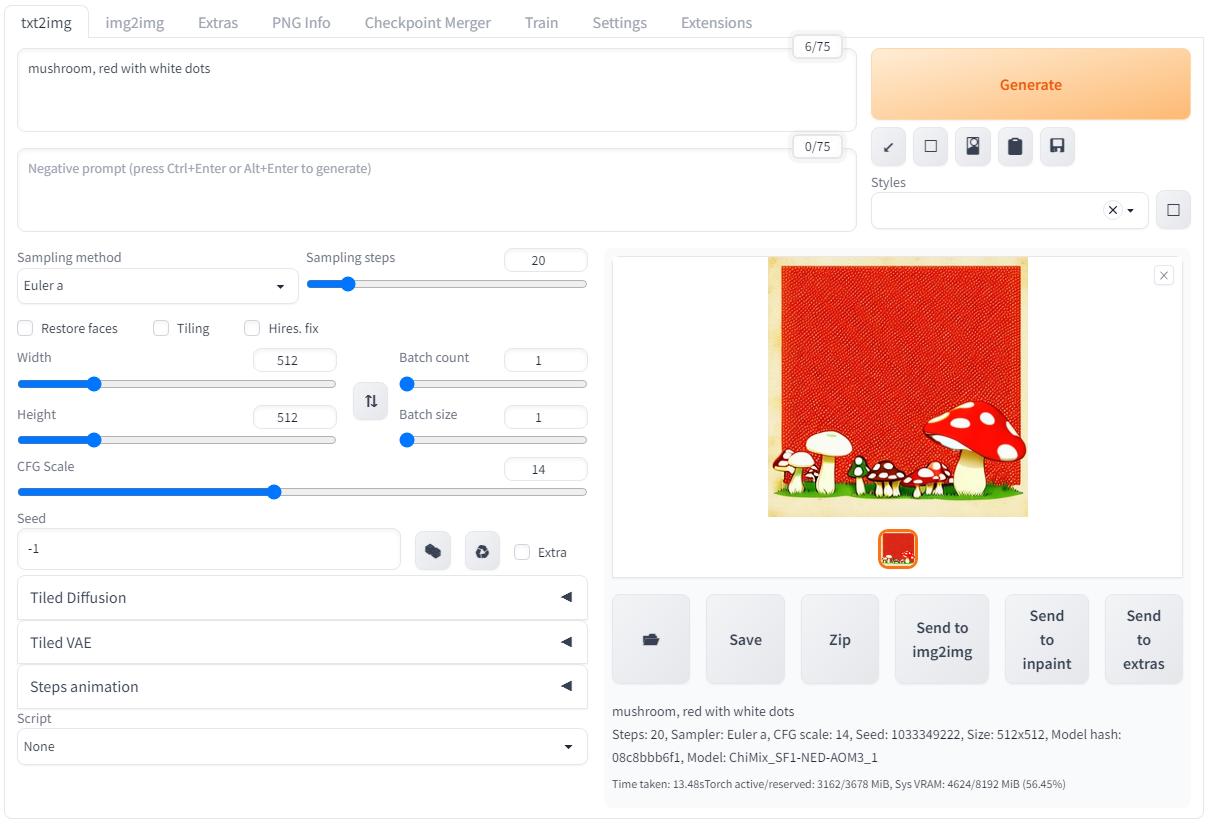
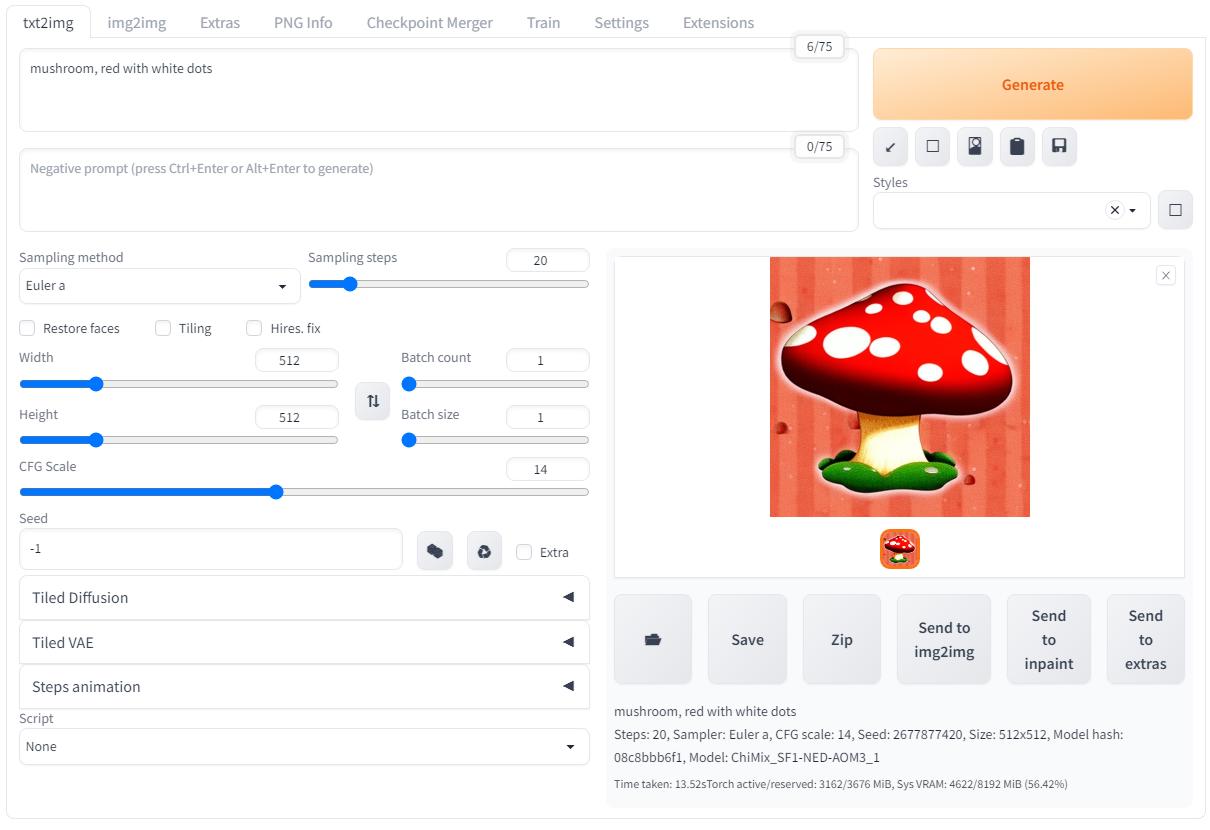
Однако если просто жать кнопку генерации то результат всегда будет разным даже если не трогать CFG Scale, и вот здесь нужно обратить внимание на параметр seed (зерно):
 |
 |
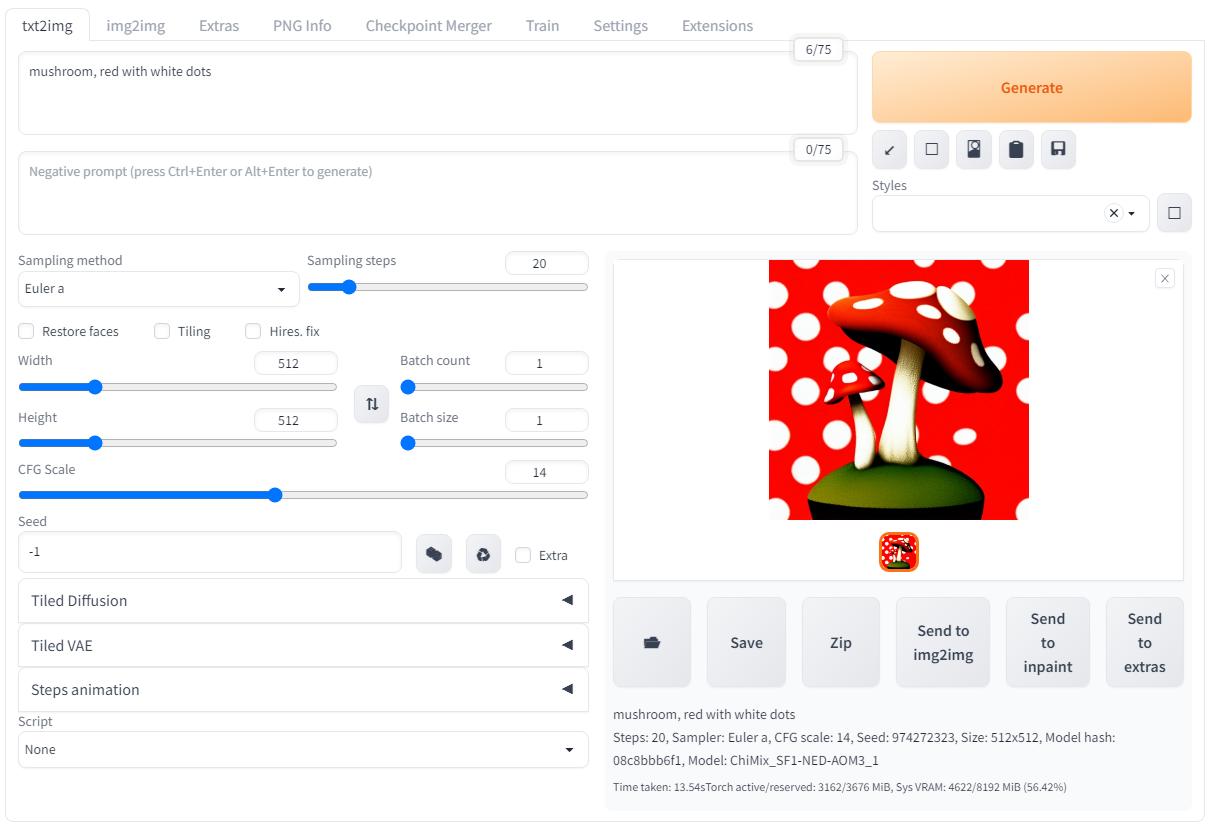 |
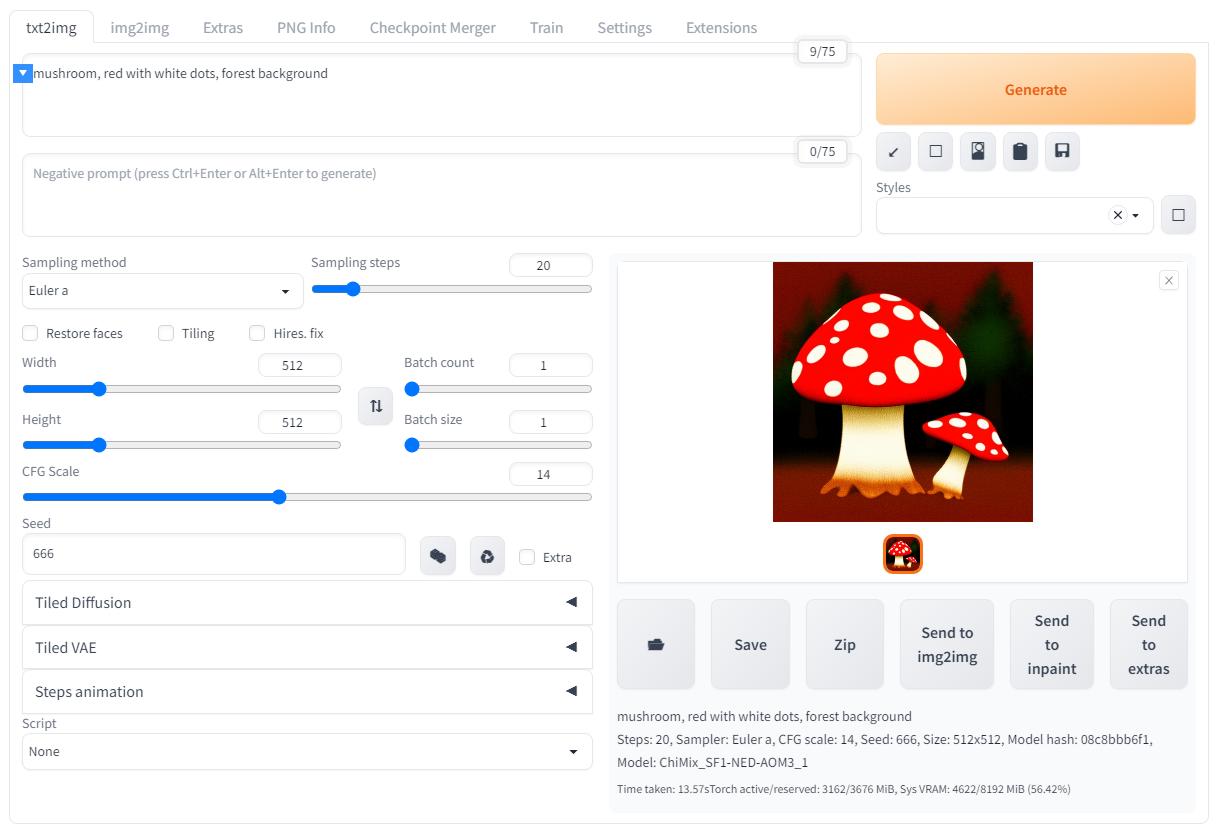
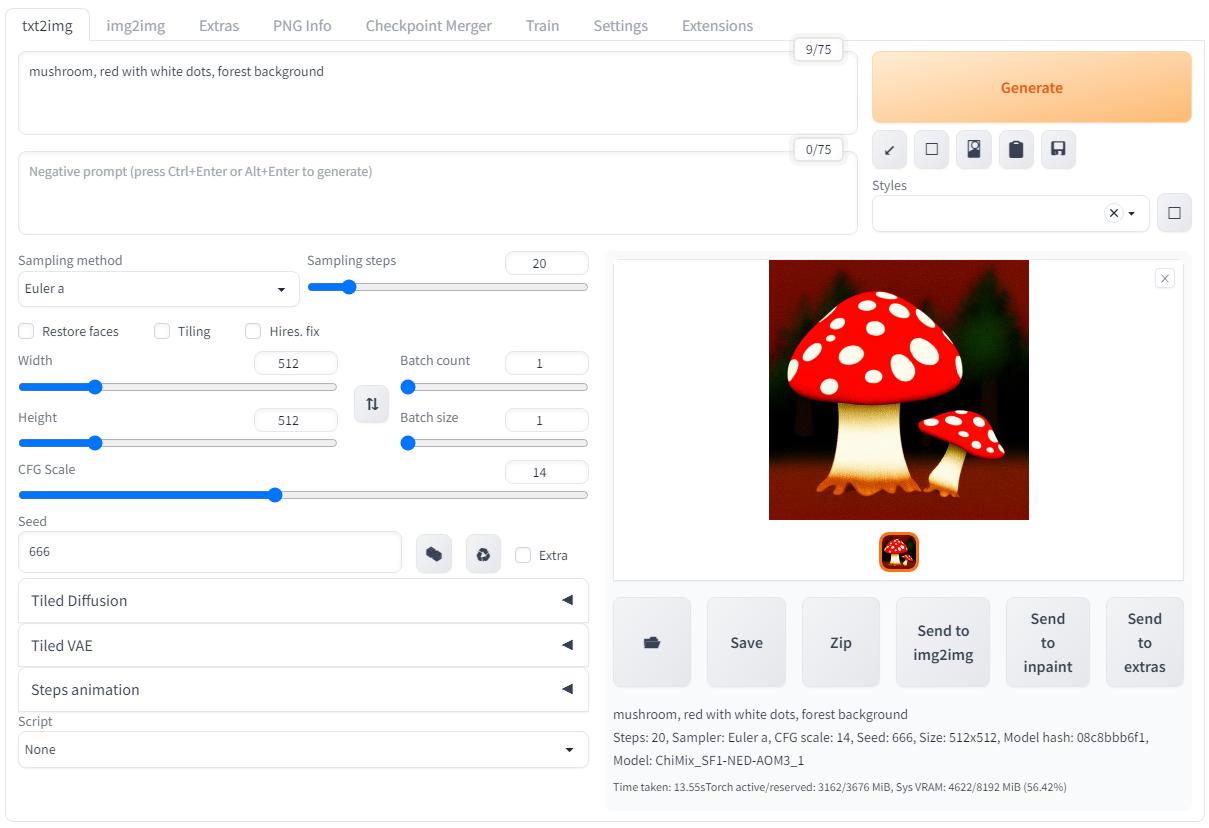
Чтобы изображение не выедало глаза ярким красным цветом я изменил ввод следующим образом: "mushroom, red with white dots, forest background". А ещё зафиксировал "зерно" на значении 666, теперь нейронная сеть будет всегда генерировать одни и те же грибочки если не трогать другие параметры:
 |
 |
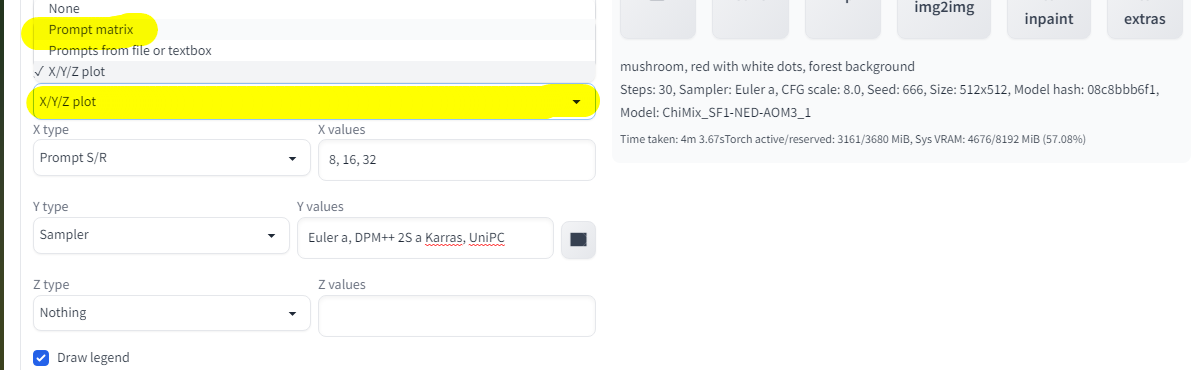
Далее перехожу к скриптам, чтобы наглядно посмотреть на разные параметры я фиксирую "зерно" на значении 666, но подключаю скрипт "X/Y/Z plot", это весьма полезный скрипт, скоро будет понятно почему:
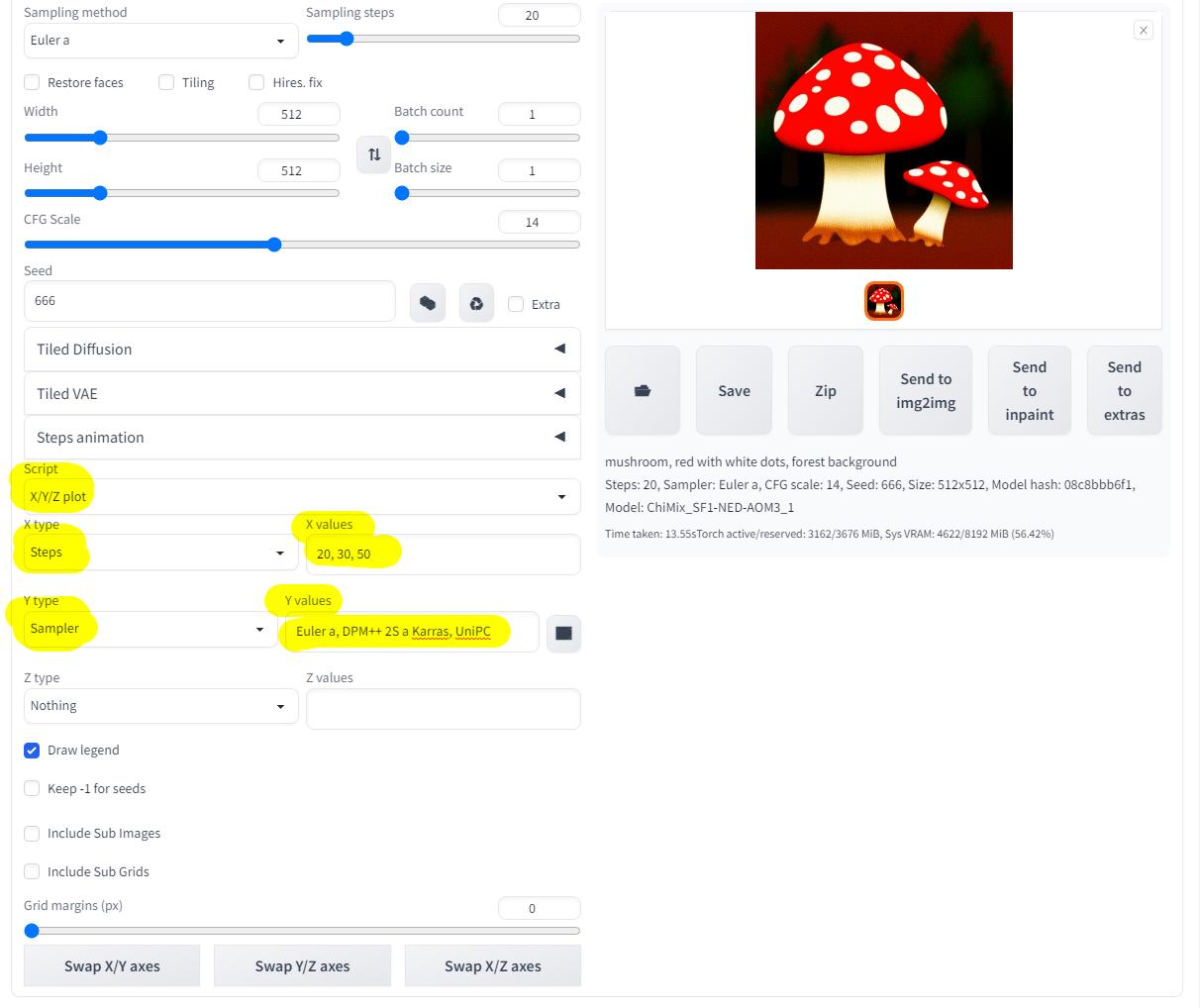
Запускаю генерацию с настроенным скриптом и жду когда закончит работу:
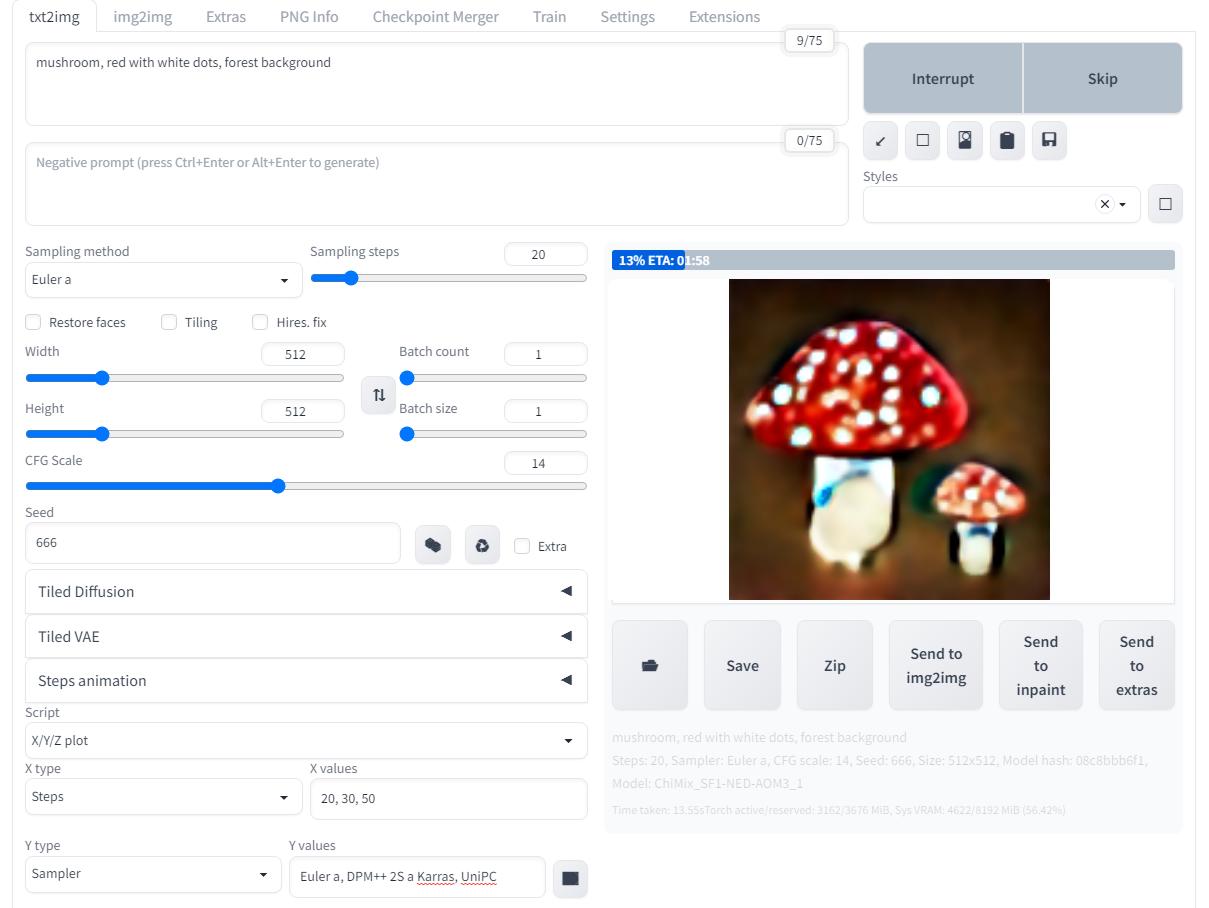
В консоли можно посмотреть на скорость работы, главное не путать "it/s" и "s/it", как можно заметить, в зависимости от сэмплера скорость генерации бывает разной, это нормально.
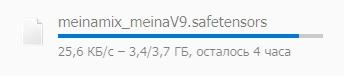
Вот результат и готов, с моей GTX 1070 без разгона это заняло чуть больше четырёх минут времени, но зато теперь всё наглядно видно, как грибочки меняются в зависимости от заданных параметров!
По оси X (слева направо) идут результаты на повышение количества проходов (шагов), иногда большое количество шагов не значит лучше, особенно если нужна простая картинка без лишних деталей, но если нужно детализированное изображение то количество шагов следует увеличивать.
По оси Y (сверху вниз) идут результаты с разными сэмплерами, в общем "сетка" изображений покажет всё нагляднее тысячи слов:

Тут у меня загрузилась другая модель, почему бы не попробовать с другой моделью сделать тоже самое?
 |
 |
Переношу модель в папку для моделей:

Обновляю список моделей кнопочкой в интерфейсе SD WebUI (рядом с меню выбора модели, да, вот тот квадратик на скриншоте) и выбираю новую модель из списка:

Дальше просто генерирую с теми же настройками новую сетку изображений при помощи скрипта, ничего феноменального, осталось только подождать, и уже с первых изображений быстрого просмотра отчетливо видна разница, грибочки уже совсем другие, впрочем, главное чтобы были "вкусными"...
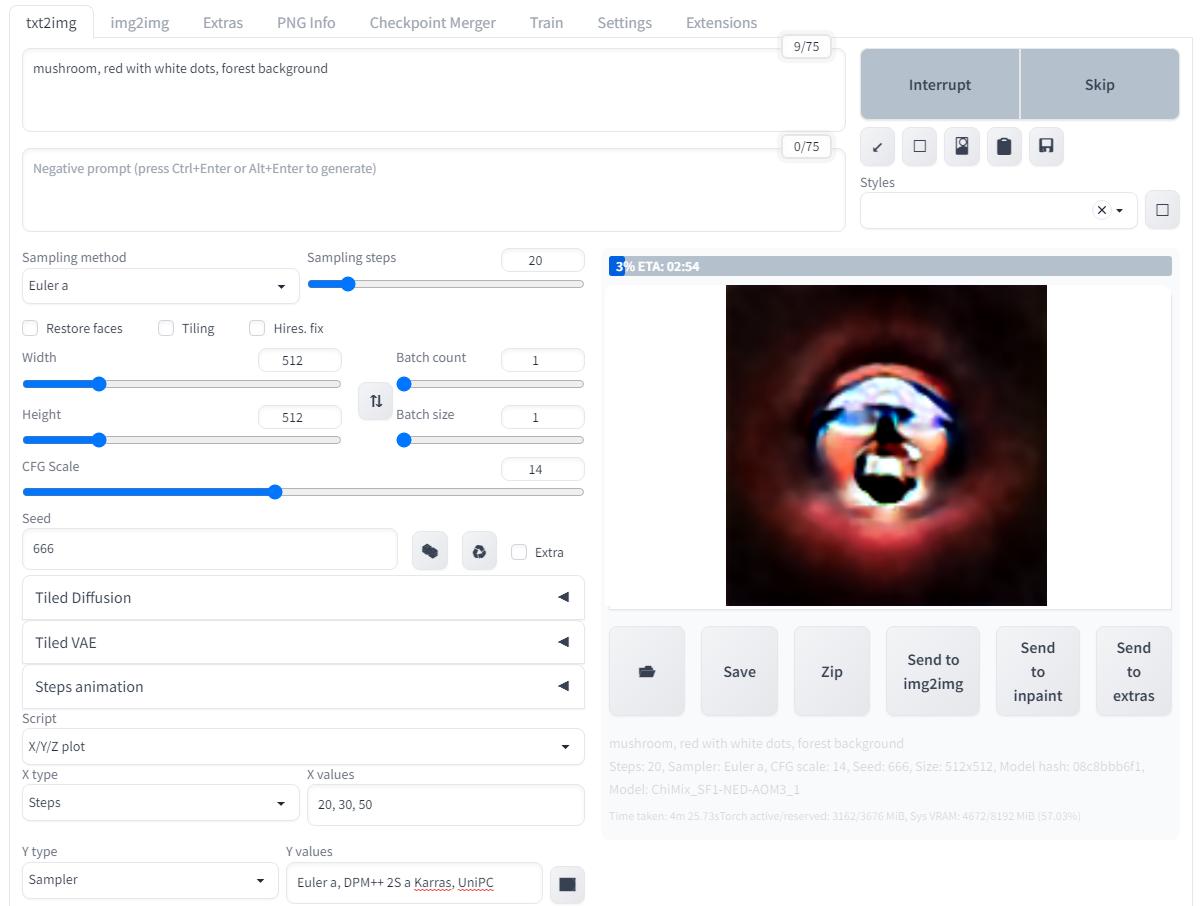
Да, результаты совсем другие теперь, но ничего удивительного, с разными моделями будут разные результаты, так оно и должно работать, нужно просто выбирать подходящую модель в зависимости от требуемого результата.

Но я не собираюсь обозревать разные модели, потому верну обратно изначальную модель из сборки Neuro и продолжу дальше именно с ней.
Вернёмся к разной степени "строгости" (CFG Scale), довольно интересно вышло:
 |
 |
Каков вывод из этого можно делать? Да никакого! Нужно просто настраивать параметры в зависимости от нужного результата, а скрипт "X/Y/Z plot" как раз помогает увидеть разницу между настройками.
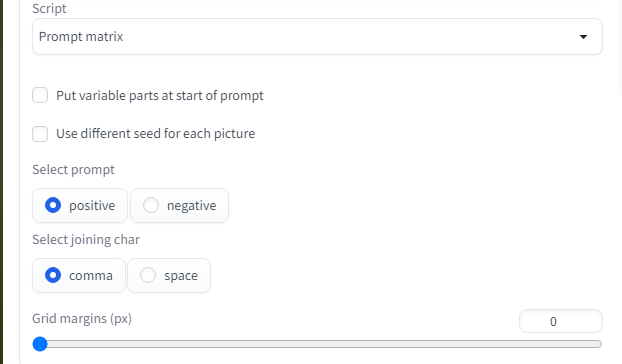
Но есть ещё скрипт "Promt matrix", что же он делает? Я и сам пока не использовал данный функционал.
Настроек здесь не густо, и как я понял из инструкций нужно добавлять вертикальную черту для разделения вариантов, как-то так:
 |
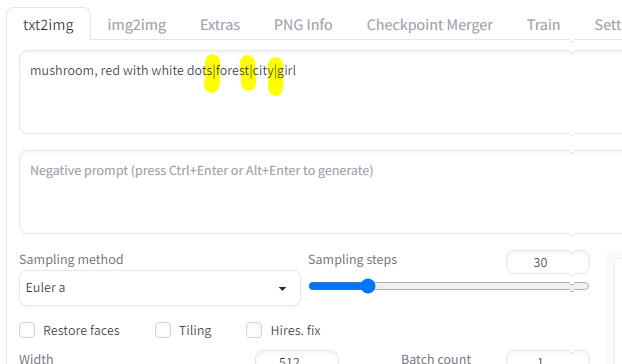 |
Таким образом получился результат зависимый уже от ввода, а не технических параметров, хотя получилось не очень наглядно, везде красные пятнистые грибы...

На этот раз я выставил случайное "зерно" и галочку в скрипте "Use different seed for each picture", что означает случайное "зерно" для каждой картинки в отдельности:
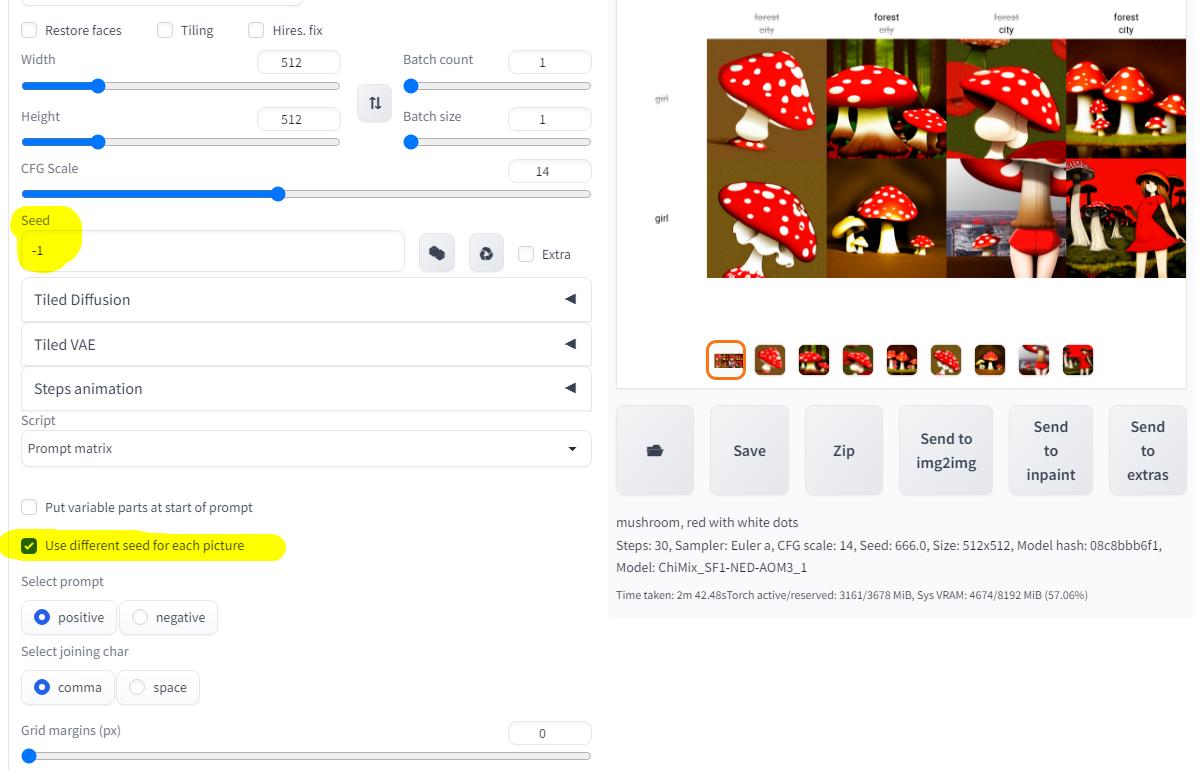
А ещё поработал над вводом, чтобы разнообразия было больше, а так же использовал сэмплеры "Euler e" и PLMS.
Да, так гораздо интереснее, хотя в целом всё равно получилось однообразно как-то... Наверное дело в грибочках, то есть исходном тексте...
 |
 |
Ладно, пришло время изменить ввод, я сократил общую строку ввода, важно обратить внимание на цифру 8/75 в правом верхнем углу, это выглядит как ограничение на количество символов, но это не так... Это ограничение на количество токенов, нельзя просто написать огромную простыню текста и получить результат, нейросеть просто не переварит слишком много информации.
Но не будем вникать в подробности, главное чтобы число не перевалило за 75 и тогда всё будет нормально, у меня ещё далеко до предела как можно заметить, так и сгенерирую следующую "пачку" изображений, при этом буду использовать сэмплер Heun.

А вот и результаты, текста меньше, а изображения стали более конкретными, из этого следует что количество текста и перечисление всего подряд не гарантирует более детализированный и качественный результат, конечно сэмплер тоже сильно влияет на результат, но если запрос сделать как попало, ни один сэмплер не поможет в получении нужного результата.

Вот сейчас я хочу чтобы не было шапки в следующих генерациях, как это сделать? Правильно, использовать Negative promt, просто добавляю слово hat (шляпа):
Правда это не всегда срабатывает, на некоторых изображениях грибная шляпа сохранилась, хотя по идее её не должно быть... Что же делать... Вообще следует сходить в интернет и почитать "инструкции", но что если человек не желает вникать в детали? Звучит забавно.

В настройках Stable Diffusion web UI есть одна галочка, можно выделить круглыми скобками чтобы нейросеть придала большее внимание к выделенному таким способом выражению, или в квадратные скобки если нужно придать меньше внимания, пожалуй пора попробовать...

Я уже видел как люди несколько скобок используют для некоторых слов ввода, попробую и я, заодно поправлю ввод, особое внимание уделяю слову "realistic":
И это сработало, нейросеть действительно стала уделять больше внимания реализму, хотя результаты всё равно далеко не идеальны, но это лишь вопрос правильно сформированного ввода и дополнительных сетей (hypernetworks).

А теперь я попробую другой скрипт, он уже позволяет несколько разных строк обработать, или скормить файл с целым списком вводных данных:
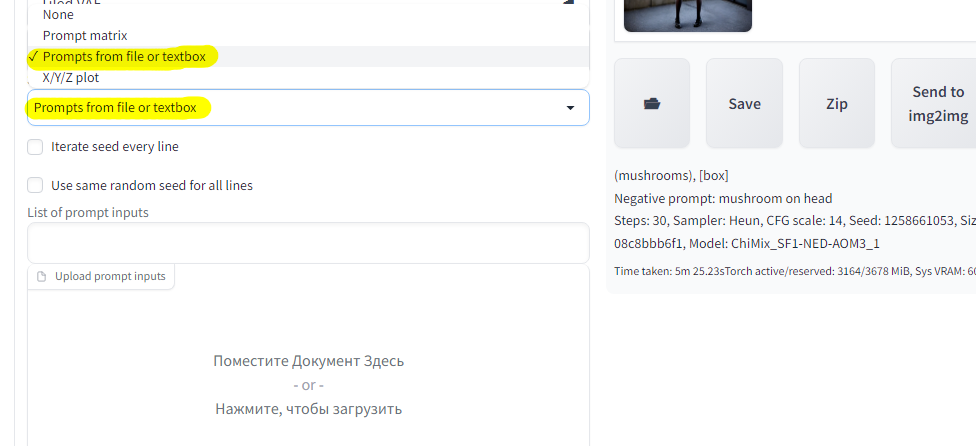
Вот так было сгенерировано три изображения по списку, это весьма полезно если нужно проверить разные вариации текста, но при этом не изменять основное поле ввода. Важно заметить, у меня стоит галочка "Use same random seed for all lines", что означает одинаковое "зерно" для всех изображений.
Раньше я старался чтобы каждое изображение было максимально уникальным, имело своё уникальное "зерно", но сейчас я сделал так, что в общих настройках "зерно" у меня случайное "-1", но при этом "зерно" будет одинаковым для каждого текста из списка в скрипте. Проще говоря все эти изображения основаны на одном и том же случайном "зерне" (Seed: 448409343):
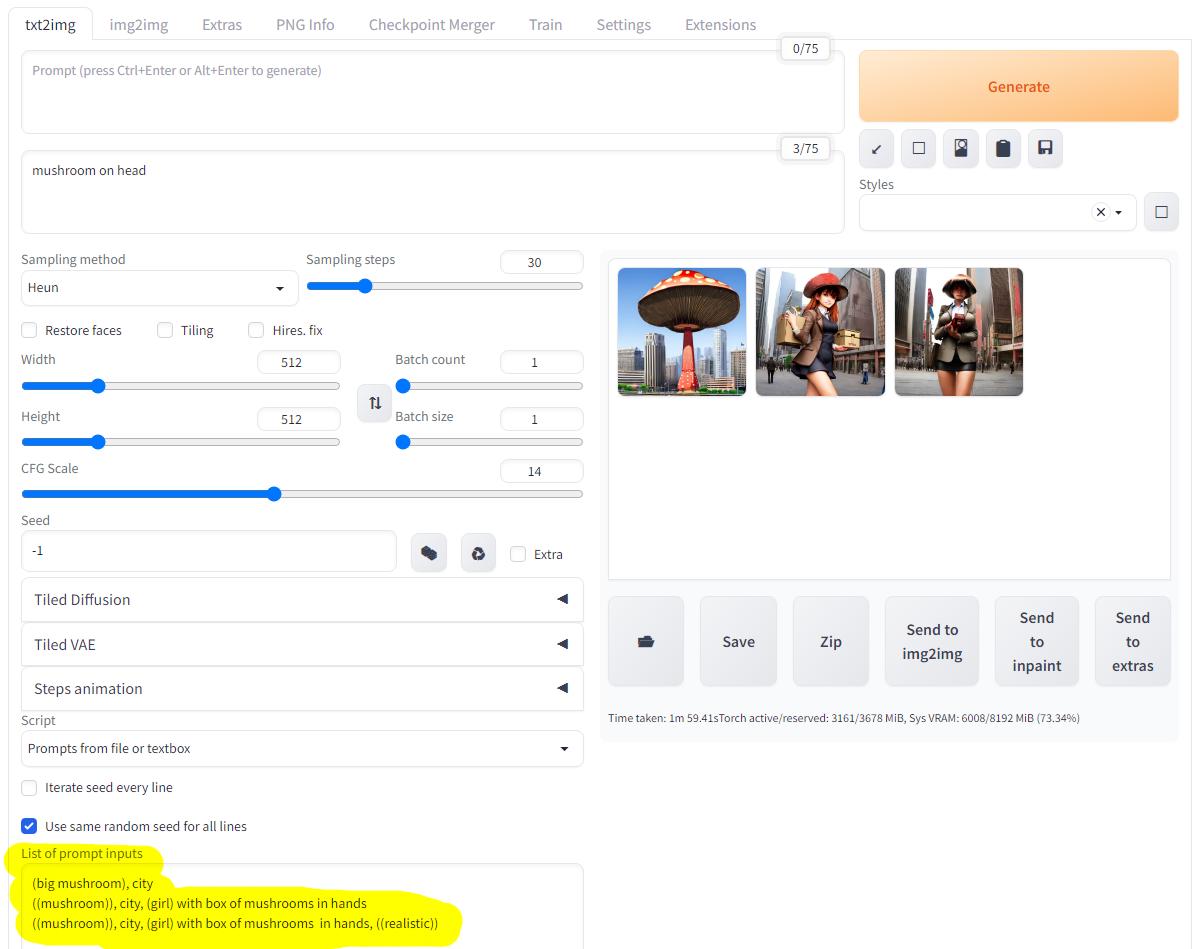
Negative promt конечно сработал не очень хорошо, нейросеть старалась нарисовать гриб на голове, и это очень заметно, но в целом получилось забавно, из интересного можно заметить схожесть двух последних изображений, причина в том, что они основаны на одном и том же "зерне", различия только в тексте вводных данных, если изменить зерно оставив всё остальное прежним, то и схожесть исчезнет.
 |
 |
 |
Ладно, что-то статья разрослась как грибы...
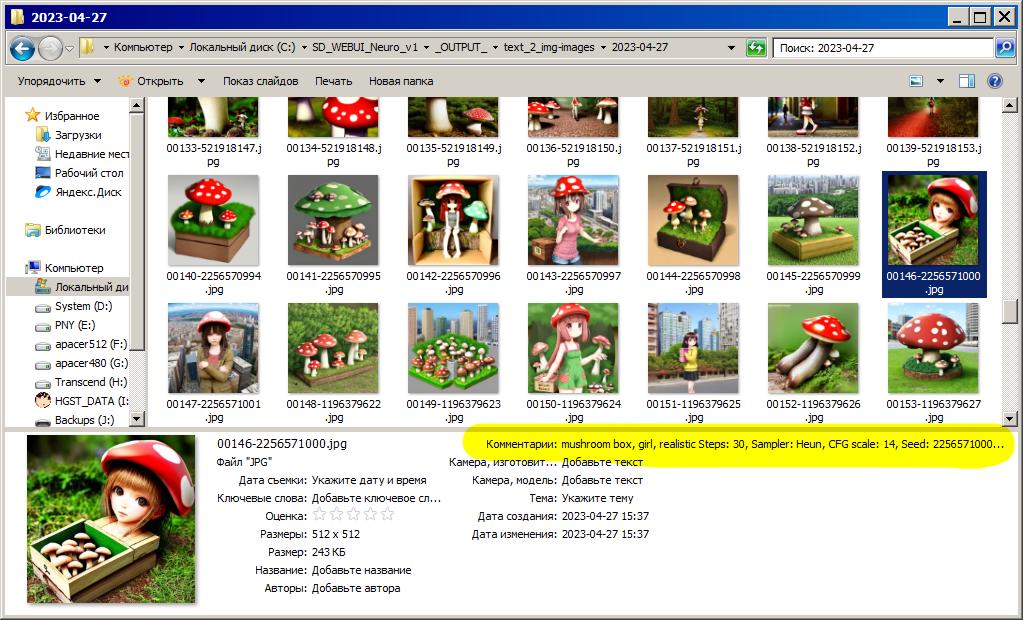
Перейдем к повторяемости результата, тут ничего сложного нет, по умолчанию SD WebUI записывает параметры генерации в комментарий к изображению, это весьма удобно:
А чтобы пользователю не приходилось всё вводить вручную как раз и придуман раздел PNG Info:
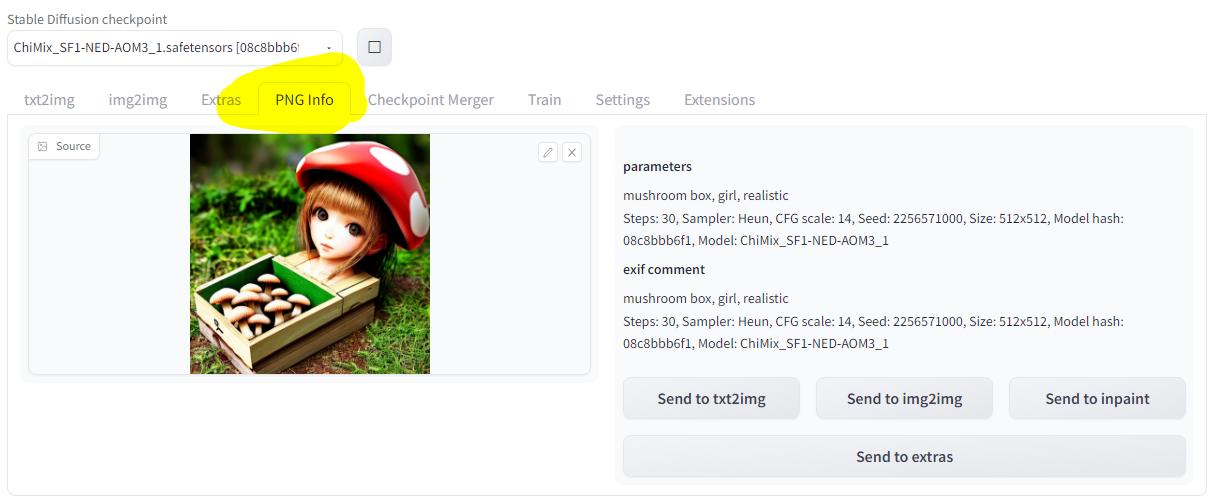
Таким образом можно легко повторить какой-либо результат:

Правда не стоит забывать про один существенный нюанс, по умолчанию нейросеть работает с точностью Float-Point 16 (FP16), процессоры же не умеют работать с точностью FP16, да и старые видеокарты тоже могут не переварить работу с точностью FP16...
Чтобы наглядно продемонстрировать в чём проблема я запущу SD WebUI в режиме полной точности FP32.

И в некоторых случаях разница действительно небольшая, первое изображение сделано с точностью FP16, второе с точностью FP32:
 |
 |
Но иногда разница в результате может быть значительной, первое изображение сгенерировано с точностью FP16, второе с точностью FP32, и вот здесь уже хорошо заметно преимущество полноценной точности вычислений:
"mushroom, red with white dots, city, human girl walking, realistic". Steps: 30, Sampler: DPM++ 2S a, CFG scale: 14, Seed: 73638092, Size: 512x512, Model hash: 08c8bbb6f1, Model: ChiMix_SF1-NED-AOM3_1
 |
 |
Так что даже если вы полностью скопировали параметры генерации у другого человека, результат может не совпадать из-за любой "мелочи", особенно если для генерации использовалось малое количество проходов (20 или меньше), тем более могут выходить обновления, они тоже могут ломать повторяемость результатов, но эта проблема не грозит независимым и автономным сборкам.
"mushroom box, city, girl". Steps: 10, Sampler: DPM2, CFG scale: 14, Seed: 2256570997, Size: 512x512, Model hash: 08c8bbb6f1, Model: ChiMix_SF1-NED-AOM3_1
 |
 |
На этом пожалуй завершу грибную фантазию нейронных сетей.
Изначально я планировал пройтись по всему функционалу SD WebUI, но в процессе стало ясно, что этого делать не следует, ведь я даже не весь функционал вкладки "txt2img" задействовал к текущему моменту.
В заключение сделаю нечто странное. Я попытался сгенерировать изображение с логотипом Overclockers, но модель не знает что это такое, потому получилось... В общем как получилось.
"mushroom box, city, girl, overclockers logo", Steps: 10, Sampler: DPM2, CFG scale: 14, Seed: 2256570997, Size: 512x512, Model hash: 08c8bbb6f1, Model: ChiMix_SF1-NED-AOM3_1

Да, я перешел в раздел img2img и сгенерировал разогнанный гриб на основе логотипа Overclockers:
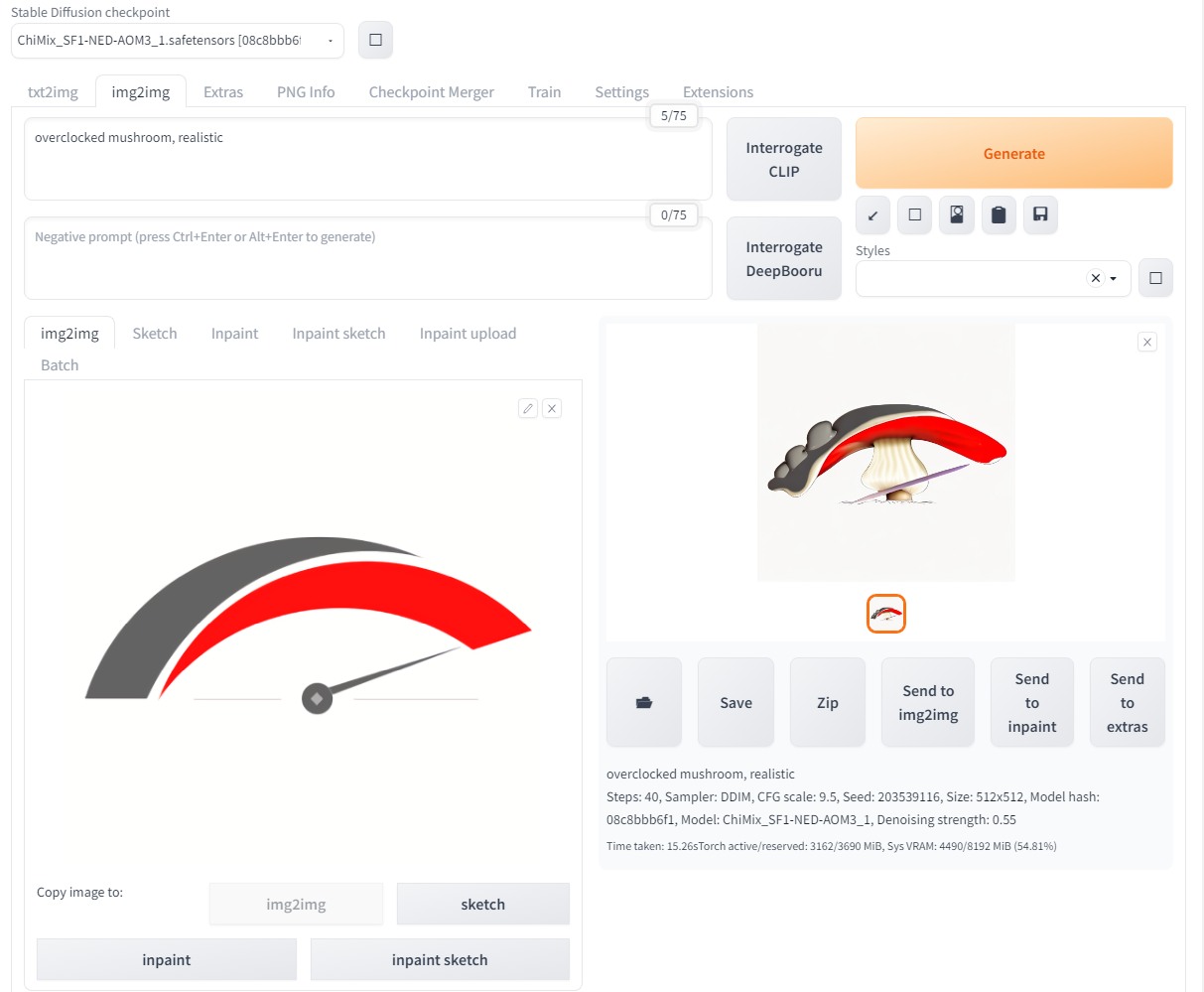 |
 |
Но в пределах данной статьи я не собираюсь переходить к данному функционалу Stable Diffusion web UI, пожалуй оставлю для других статей если будет желание заниматься этим всем.
И да, рекомендую поискать информацию о том, что такое Deepfake, если конечно не в курсе.
Благодарю за внимание, больше интересных статей в блоге Hard-Workshop.
...

Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.