
Краткий обзор Intel Lakefield
Введение

Планировавшиеся к выпуску на рынок ещё в 2019, процессоры Intel Lakefield наконец-то были представлены официально, а некоторые тестовые лаборатории уже даже смогли прикоснуться к первым устройствам на инновационных чипах. Процессоры Lakefield действительно представляют собой уникальный образец инженерной мысли, предлагая сразу несколько интересных решений, причём не только в рамках архитектуры x86-64, но и за её пределами.
- Во-первых, Lakefield — первая гибридная x86-64 архитектура, сочетающая одно высокопроизводительное и четыре энергоэффективных ядра на одном кристалле.
- Во-вторых, при производстве процессоров Lakefield используется новая технология упаковки Intel Foveros, сочетающая несколько кристаллов, выполняющих принципиально различные функции и расположенных друг над другом.
- И, наконец, в третьих, Lakefield — это полноценная однокристальная система архитектуры x86-64, включающая в себя центральный и графический процессоры, оперативную память, и всё это в упаковке размером всего 12×12×1 мм.
Давайте же посмотрим на Intel Lakefield чуть подробнее, ибо он, по всей видимости, этого заслуживает.
Сближение процессорных архитектур
реклама
Процесс разработки архитектуры процессора, как и любая другая инженерная деятельность, всегда сопровождается множеством компромиссов. Так, последние пару десятков лет необходимо уже в самом начале процесса принять следующее важное решение — нужна ли процессору высокая производительность пускай и ценой не самой лучшей энергоэффективности или стоит отдать приоритет последней, пожертвовав высокой пиковой производительностью? Конечно же, в теории хотелось бы иметь некий баланс между указанными крайностями, но на практике, так или иначе, все современные процессорные архитектуры оказываются ближе к одному из указанных «полюсов»: их характеризует либо высокая производительность, либо высокая энергоэффективность. Например, большая часть процессоров x86-64 попадает в категорию высокопроизводительных, но не самых энергоэффективных решений, а процессоры архитектуры ARM, напротив, в массе своей не могут похвастаться сравнимой с x86-64 пиковой производительностью, зато энергии потребляют при решении большинства стоящих перед ними задач значительно меньше.
Конечно же, с лавинообразным распространением различных мобильных устройств и одновременно растущим желанием выполнят на них всё более сложные задачи, все процессорные архитектуры движутся к некой общей точке, только делают это с разных «концов» — высокопроизводительная архитектура x86-64 старается стать всё более энергоэффективной, а ARM (и другие энергоэффективные архитектуры), напротив, стремятся стать всё более производительными. Непосредственных точек соприкосновения указанных архитектур до недавнего времени было не так много, так что оценить, кто был ближе к заветной цели максимального баланса между производительностью и энергоэффективностью было почти невозможно. Разве что разрабатываемый Intel уже многие годы энергоэффективный дизайн x86-64 ядер Atom «засветился» в нескольких смартфонах и планшетах, но хоть сколь-нибудь заметного эффекта не произвёл. Кстати, злую шутку с Intel Atom сыграла не столько не самая лучшая по сравнению с конкурентами энергоэффективность (которая, кстати, в последних поколениях Atom не так уж и далека от большинства образцов архитектуры ARM), сколько отсутствие огромного массива ПО для мобильных систем, большая часть которого никогда не разрабатывалась «под» x86-64. Любой, владевший Android-смартфоном или планшетом на Intel Atom, хорошо знает, о чём здесь идёт речь.
Интересно отметить, что ARM на пути в «светлое будущее» постигла в общем-то та же участь: при в целом уже достаточной производительности все попытки процессоров этой архитектуры выйти на рынок высокопроизводительных компактных устройств (например, ультрабуков), натыкались на ту же стену —отсутствие огромного количества ПО, которое здесь уже разрабатывается массово только «под» x86-64. Ну а про рынок настольных решений и говорить нечего — об этом сегменте ARM долгое время могла только мечтать. Ситуация, однако, начинает меняться прямо на наших глазах. Думаю, все слышали про недавно объявленный (пускай и постепенный) отказ Apple от использования x86-64 процессоров Intel в своих ноутбуках и настольных ПК и переход на собственные решения с архитектурой ARM. Microsoft тоже не дремлет, пускай неспешно (и не очень же успешно) развивая редакцию ОС Windows для компьютеров на базе ARM-процессоров, а также эти самые компьютеры периодически выпуская (ARM-модели серии Microsoft Surface).
реклама
И вот если взглянуть на происходящее с точки зрения обсуждаемого процесса сближения процессорных архитектур, которое должно было рано или поздно вызвать обострение конкуренции в точках соприкосновения, то Intel Lakefield — это своего рода симметричный ответ x86-64 на продвижение ARM в сегмент высокопроизводительных ноутбуков и настольных ПК. Здесь, где ранее безраздельно господствовала именно архитектура x86-64, Lakefield будет пытаться дать отпор незваному гостю из мира ARM. Основным полем битвы станет сегмент ультрабуков и планшетных компьютеров, где важна не только, и даже не столько чистая производительность, сколько энергоэффективность. И неслучайно, что первым устройством, существующим в вариантах как с ARM-процессором (Qualcomm Snapdragon 8cx), так и с процессором x86-64 (Intel Core i5-L16G7) стал как раз таки ультрабук, а именно Samsung Galaxy Book S.

Отметим, что подход к разработке процессоров на архитектуре ARM, нацеленных на использование в ультра-компактных устройствах, в целом прост и не несёт практически никаких архитектурных новшеств — за счёт использования всё более тонкого техпроцесса практически без увеличения энергопотребления наращиваются тактовые частоты, увеличивается количество исполнительных блоков и размеры кэш-памяти. Так, упомянутый выше чип Snapdragon 8cx, выполненный по нормам 7 нм (TSMC N7), имеет в наличии 4 высокопроизводительных ядра Kryo 495 Gold, работающих на частоте 2.84 ГГц (а также 4 энергоэффективных ядра Kryo 495 Silver с частотой 1.80 ГГц), 2 МБ кэша L3, а возросший вдвое транзисторный бюджет позволил значительно увеличить количество исполнительных блоков в графическом ускорителе Adreno 680. Как результат, чип Snapdragon 8cx крайне близок по техническим характеристикам к конкурирующим представителям архитектуры x86-64, выполненным в аналогичном форм-факторе и имеющим энергопотребление того же порядка.
Intel же в Lakefield сделала нечто принципиально новое, пускай и отчасти только в рамках архитектуры x86-64, а не с точки зрения индустрии в целом — вместо того, чтобы продолжать экстенсивное развитие линейки энергоэффективных чипов Atom, компания решилась на выпуск первого гибридного x86-64 процессора, сочетающего в себе как высокопроизводительные («большие»), так и энергоэффективные («малые») ядра. Конечно, концептуально в использовании сочетания высокопроизводительных ядер с ядрами энергоэффективными нет ничего нового, ведь в тех же процессорах архитектуры ARM подобный дизайн используется уже на протяжении многих лет в рамках подхода big.LITTLE. Однако, у гибридной архитектуры Intel есть множество интересных деталей, о которых стоит поговорить подробнее.
Логическая организация
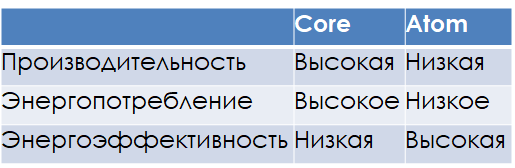
К моменту начала разработки первой гибридной x86-64 архитектуры у Intel имелось два принципиально разных дизайна x86-64 процессоров, относительные характеристики которых сведены в таблицу.
реклама
На не самых сложных задачах энергоэффективность Atom действительно выше, однако, ядра дизайна Atom зачастую попросту не способны выдать производительность уровня ядер дизайна Core, либо могут потребовать для выполнения сложных задач уже больше энергии, чем Core. Для того чтобы взять лучшее из обоих миров, инженерами Intel было принято решение объединить одно ядро дизайна Core с четырьмя ядрами дизайна Atom на одном кристалле. Такое сочетание «большого» высокопроизводительного и «малых» энергоэффективных ядер будет работать разным образом в зависимости от характера нагрузки.
При нагрузках, имеющих преимущественно однопоточный характер, предпочтительным является использование «малого» ядра Atom в том случае, если максимальная производительность не требуется и «большого» ядра Core в обратной ситуации. Конкретный уровень однопоточной нагрузки, когда выгоднее переключиться с «малого» на «большое» ядро зависит от непосредственно используемых ядер. Так, если «большое» ядро Core основано на актуальной архитектуре Sunny Cove, а «малое» ядро Atom — на актуальной же архитектуре Tremont, то граница, после которой выгоднее задействовать «большое» ядро лежит вблизи 60% от производительности «большого» ядра. Обратите также внимание, что «малые» ядра Intel не так уж и «малы» — ядро Tremont способно выдавать чуть меньше 70% максимальной производительности ядра Sunny Cove, а это уже, между прочим, уровень производительности где-то посередине между старыми-добрыми Sandy Bridge и Haswell.

Иная картина наблюдается в случае, когда задача хорошо масштабируется по потокам. Так как «малых» ядер четыре, а «большое» всего одно, то суммарная производительность «малых» ядер оказывается выше в сравнении с одним «большим», так что теперь, когда требуется высокая производительность, становится выгоднее использовать уже «малые» ядра — они способны сделать больше как вообще, так и в рамках одного и того же энергопотребления.
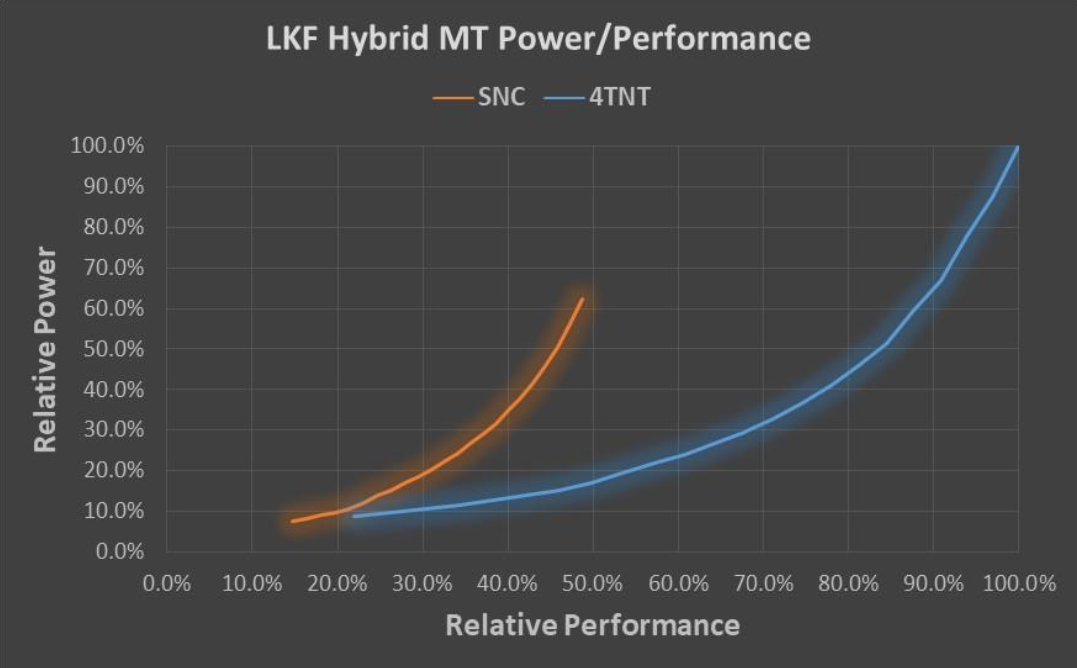
Естественно, в реальности нагрузка будет смешанной и реальный сценарий работы будет представлять собой нечто среднее между двумя рассмотренными граничными вариантами. Кроме того, существуют относительно сложные задачи, в которых скорость отклика важнее соображений энергоэффективности, так что оптимальным вариантом использования имеющихся в распоряжении ядер в таких случаях придётся пренебречь. Например, при просмотре веб-страниц, наиболее сложные однопоточные задачи и задачи, требующие максимально быстрого отклика, ложатся на плечи «большого» ядра Sunny Cove, а всё остальное, включая задачи, выполняющиеся в фоне — на «малые» ядра Tremont.
реклама
Как уже упоминалось выше, само по себе сочетание высокопроизводительных ядер с ядрами энергоэффективными уже на протяжении многих лет используется в процессорах архитектуры ARM в рамках подхода big.LITTLE. Однако, в ARM big.LITTLE чаще всего используется одинаковое число «больших» (высокопроизводительных) и «малых» (энергоэффективных) ядер, в то время как в Intel Lakefield «большое» ядро всего одно. При этом и у инженеров ARM, и у разработчиков первой гетерогенной x86-64 архитектуры Intel были веские причины поступить именно так, а не иначе.
- К моменту появления первых гетерогенных архитектур в мобильных процессорах ARM, даже самые «большие» ARM-ядра попросту не обладали достаточной производительностью для решения большинства сложных задач, стоявших перед ними, так что приходилось снабжать чипы хотя бы двумя «большими» ядрами, а в решениях верхнего уровня — и четырьмя. Со временем ситуация изменилась, так что, например, у одного из ведущих производителей процессоров архитектуры ARM, Qualcomm, в линейке актуальных чипов на данный момент присутствуют варианты с дизайном 2+4, 2+6 и даже более сложным, например, 1+1+6 или 1+3+4, где имеется в наличии уже ядра третьей категории, которые условно можно назвать «средними».
- У Intel же на момент выхода первой гетерогенной архитектуры проблемы были совсем иного рода — высокопроизводительное ядро, способное «потянуть» многие задачи даже в одиночку имелось, но оно содержало в себе столь огромное количество транзисторов, что даже при использовании передового 10-нм техпроцесса занимало слишком много места. На вычислительном кристалле Lakefield площадью 82 мм2 с учётом присутствия на нём графического процессора 11 поколения, 4 «малых» ядер Tremont и некоторых других блоков, попросту нет места для второго «большого» ядра Sunny Cove. Даже если физически удалить из ядра Sunny Cove неиспользуемые в Lakefield блоки, исполняющий AVX-инструкции и соответствующие регистры.
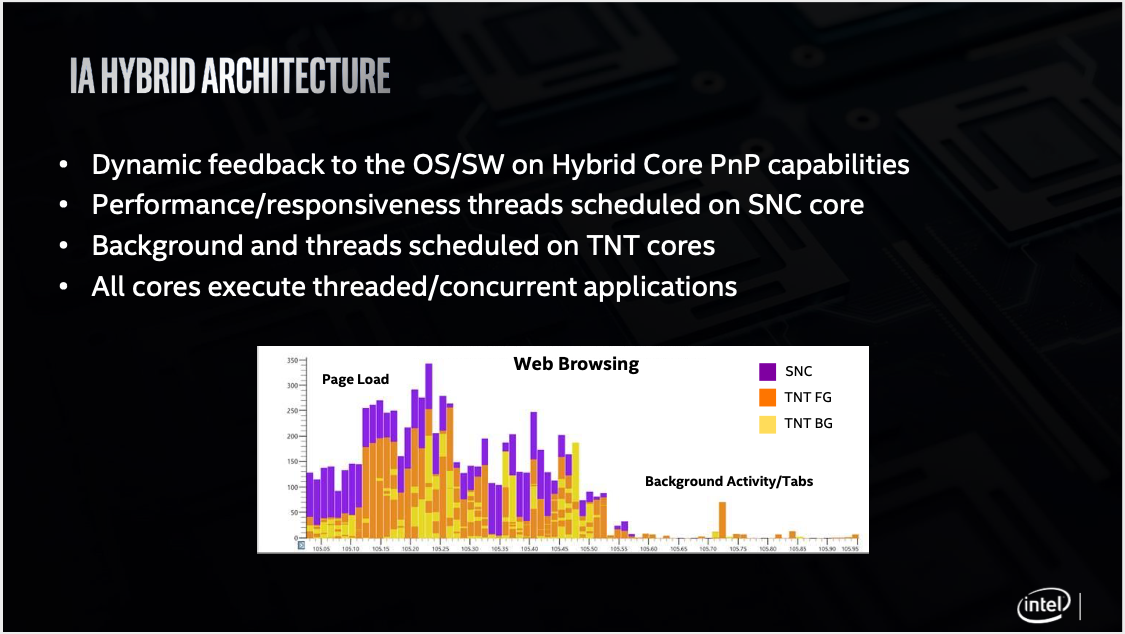
Конечно, можно было не ограничивать себя столь узкими рамками в размерах чипа, но задача изначально была в разработке не просто энергоэффективного решения, способного обеспечить некоторую заданную (надо полагать, партнёрами) производительность, а в разработке решения одновременно с этим максимально миниатюрного, подходящего для использования в ультра-компактных устройствах. Так что пришлось идти на указанный компромисс в виде дизайна 1+4, а не, скажем, потенциально несколько более простого с точки зрения управления вычислительными ресурсами 2+4. И здесь, конечно, необходимо понимать, что практическая эффективность любого гибридного процессора, содержащего «большие» и «малые» ядра, зависит в первую очередь от того, насколько оптимальным будет выбор ядер для выполнения определённых задач в каждой конкретной ситуации. Безусловно чипам Lakefield для эффективной работы необходим качественный планировщик (scheduler), и с этим, вероятно, могут возникнуть определённые проблемы, так как Lakefield — это не просто первый в истории архитектуры x86-64 гетерогенный чип, это ещё и асимметричное решение с 1 «большим» ядром и 4 «малыми». Для гибридных процессоров big.LITTLE архитектуры ARM планировщики разрабатываются уже годам и этот опыт безусловно можно использовать, однако, гибридных чипов ARM, сделанных по несимметричной схеме 1+4 до сих пор не наблюдалось, да и планировщики всё это время по большей части разрабатывались для ядра Linux, в то время как Intel, по всей видимости, делает основную ставку на ОС Windows.
Да, в Windows уже имеется поддержка гетерогенной архитектуры big.LITTLE от ARM на уровне планировщика, но она появилась сравнительно недавно, да и оптимизирована была, по всей видимости, преимущественно для симметричного дизайна 4+4. Так что можно ожидать, что у Intel и Microsoft уйдёт какое-то время на доведение планировщика для Lakefield «до ума» и первые тесты подтверждают некоторые опасения — ожидать максимально эффективную реализацию планировщика сразу не стоит. Вот так, например, по результатам тестов Samsung Galaxy Book S на Core i5-L16G7, проведённых порталом Notebookcheck, выглядит загрузка ядер Lakefield в многопоточном тесте Cinebench:
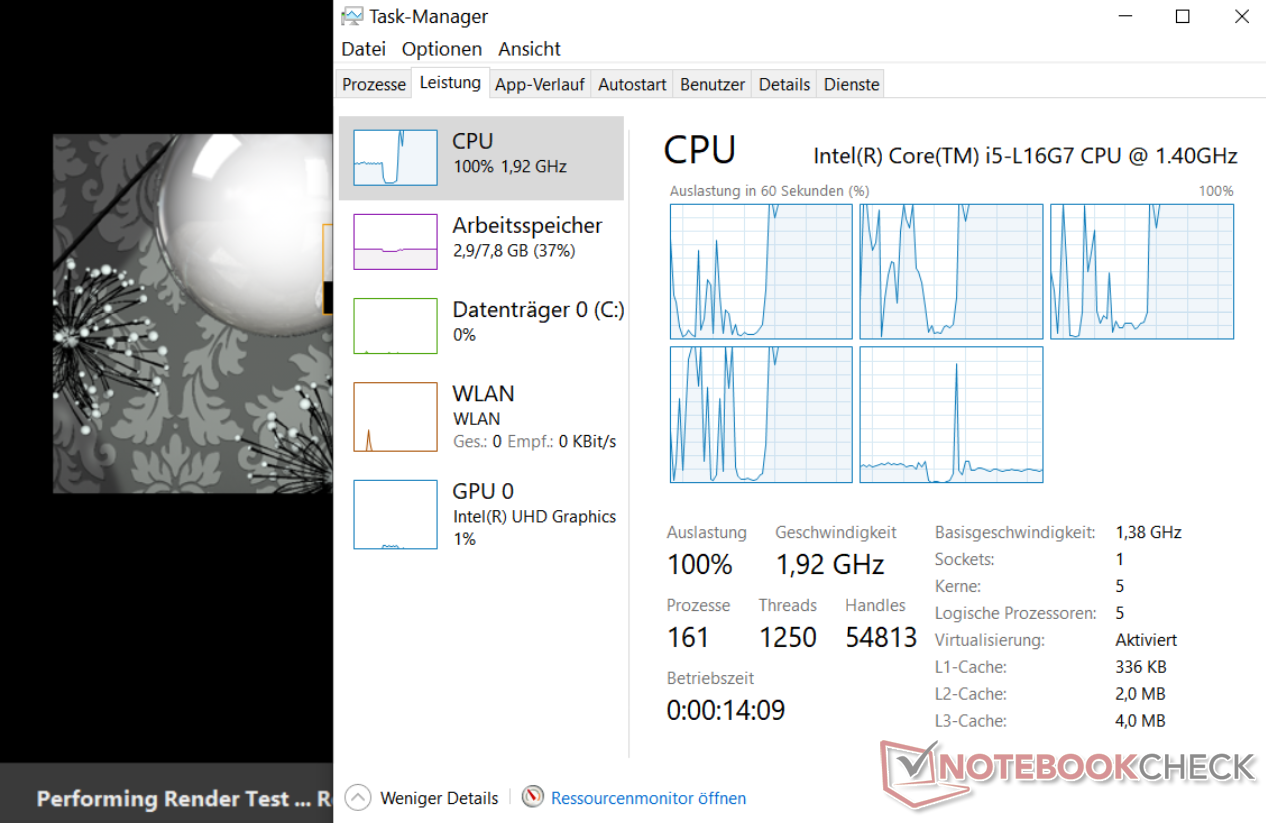
Здесь видно, что планировщик корректно определил характер нагрузки и выделил под неё 4 «малых» ядра, которые отображаются в Диспетчере задач первыми. Последнее «большое» ядро оказалось практически не задействованным, но этого в подобных сценариях использования обычно и не требуется. Разве что было бы неплохо, если бы планировщик Windows умел распределять потоки на все 5 ядер для достижения максимально возможной производительности, скажем, при работе от сети, но пока, по всей видимости, поддерживается лишь асимметричный режим работы: либо одно «большое» ядро, либо четыре «малых». И если для нагрузки многопоточной это обстоятельство можно считать не столь существенным, то в однопоточном режиме всё куда сложнее — здесь при неэффективном распределении на одно из «малых» ядер вместо исполнения на ядре «большом» можно получить откровенно низкие результаты. И возможно, разочаровывающе низкая производительность новинки в однопоточных сценариях, о которых не написал уже только ленивый — это всего лишь следствие пока ещё не лучшим образом работающего планировщика.
Например, в бенчмарке Cinebench, запущенном в однопоточном режиме, стоило бы ожидать максимальной загрузки лишь последнего «большого» ядра при минимальных нагрузках на первые четыре «малых», но что-то явно «пошло не так»:
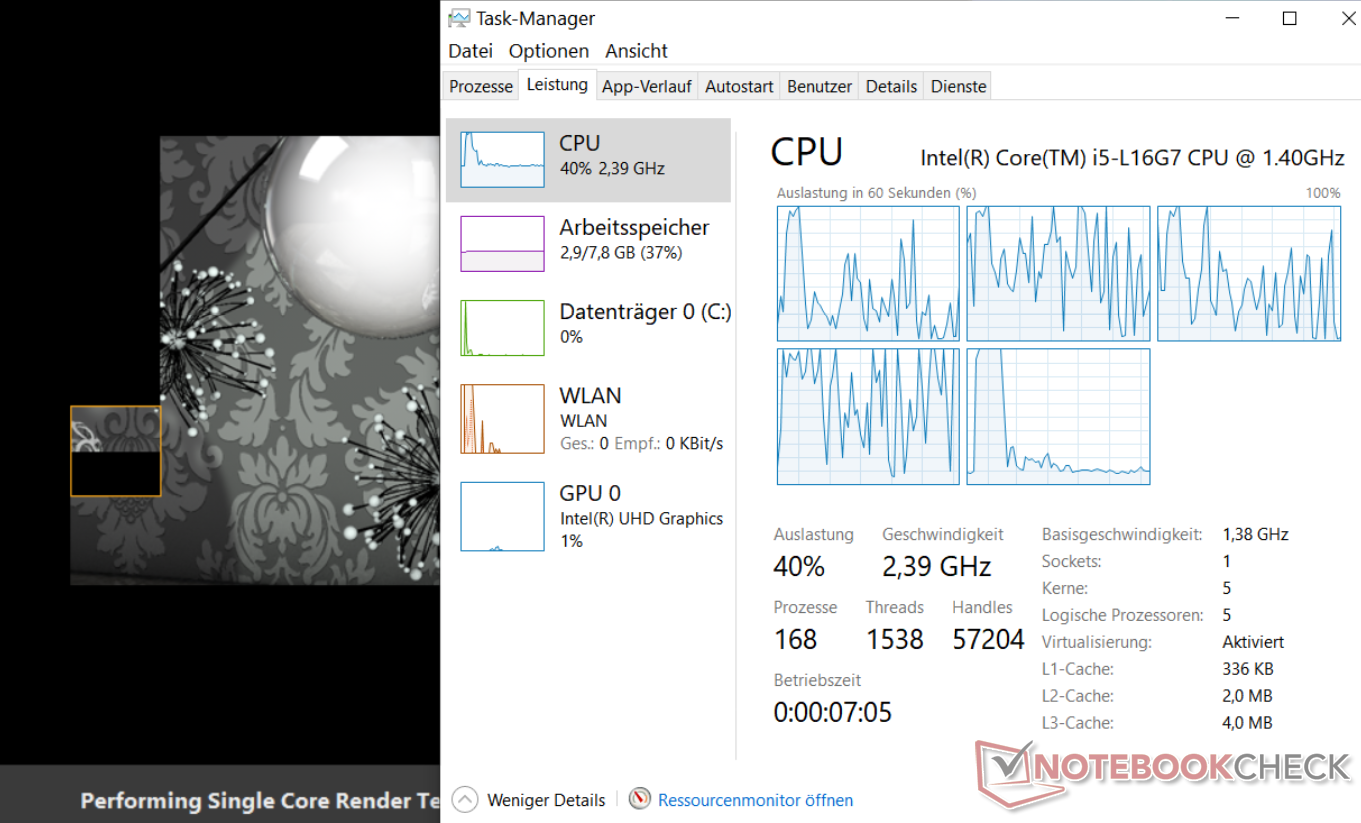
Конечно, использование встроенного в Windows Диспетчера задач для целей мониторинга загрузки ядер – идея не лучшая, так как выводит он лишь усреднённые за некоторую единицу времени, а не мгновенные значения загрузки ядер. Как следствие, возможны ситуации, когда планировщик постоянно "перекидывает" задачу с ядра на ядро, так что усреднённая за некоторое время загрузка каждого из, скажем, 4 ядер оказывается равна 25%, хотя в реальности исполнялась всего 1 задача на 1 ядре притом полностью его нагружая (просто ядро это постоянно менялось). Похоже, при запуске Cinebench в однопоточном режиме имела места подобная ситуация, так что картина загрузки ядер получилась несколько запутанная, но однозначно видно, что уже в самом начале бенчмарка планировщик решил «скинуть» задачу на «малое» ядро, несмотря на её однопоточный характер. Так что, похоже, надо дать Intel и Microsoft некоторое время поработать над планировщиком, и ситуация с однопоточной производительностью может улучшиться.
И прежде чем перейти к особенностям физической реализации первых гибридных x86-64 процессоров, отметим, что поддержки Hyper-Threading пока нет ни на «большом» ядре Sunny Cove, ни на четырех «малых» ядрах Tremont. Кроме того, для того, чтобы была возможна миграция задач с «большого» ядра на «малые» и обратно, у «большого» ядра Sunny Cove урезали поддержку AVX-инструкций, чтобы гарантировать совместимость наборов команд между разными типами ядер.
Физическая компоновка
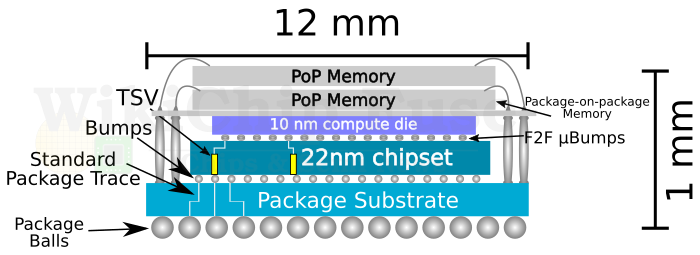
Помимо нового (по крайней мере в мире x86-64 процессоров) логического устройства, при производстве процессоров Lakefield используется и новая технология упаковки, получившая название Intel Foveros. Суть Foveros заключается в том, что для упаковки всех составляющих однокристальной системы в небольшой корпус размером всего 12×12×1 мм элементы распределяются по нескольким кристаллам, расположенным друг над другом и определённым образом связанными между собой.

Базовый кристалл (Base Die) производится по улучшенному 22-нм техпроцессу Intel (22FFL, или P1222), его площадь составляет 92 мм2, а количество транзисторов равняется 650 млн. Обратите внимание, что техпроцесс 22FFL имеет мало общего со старым 22-нм техпроцессом Intel, использовавшимся при производстве процессоров поколений Haswell и Ivy Bridge, а представляет собой, скорее, вариант современного 14-нм техпроцесса Intel, «растянутого» до норм 22 нм. На базовом кристалле расположены контроллеры USB 3, аудио, PCI Express 3.0 и другие компоненты ввода/вывода.

Выше располагается вычислительный кристалл (Compute Die), который содержит вычислительные ядра Sunny Cove и Tremont, графический процессор 11 поколения и многочисленные компоненты Uncore. Базовый кристалл изготавливается по 10-нм техпроцессу Inten второго поколения (10nm+, или P1274), он несколько меньше (82 мм2), но за счёт более тонкого техпроцесса содержит значительно больше транзисторов — чуть более 4 млрд.

И, наконец, над вычислительным кристаллом расположены микросхемы оперативной памяти стандарта LPDDR4X-4267. И прежде чем мы рассмотрим подробнее, каким образом все эти кристаллы объединены, давайте поговорим, зачем вообще в конце 2010-х процессорной индустрии понадобилось использовать многокристальную компоновку?
Всё достаточно просто — производство больших монолитных кристаллов с использованием всё более тонких техпроцессов становится всё менее выгодным экономически. Вот так, например, выглядит график роста стоимости производства 1 мм2 кристалла при производстве кристаллов площадью 250 мм2 с использованием различных техпроцессов по данным AMD:
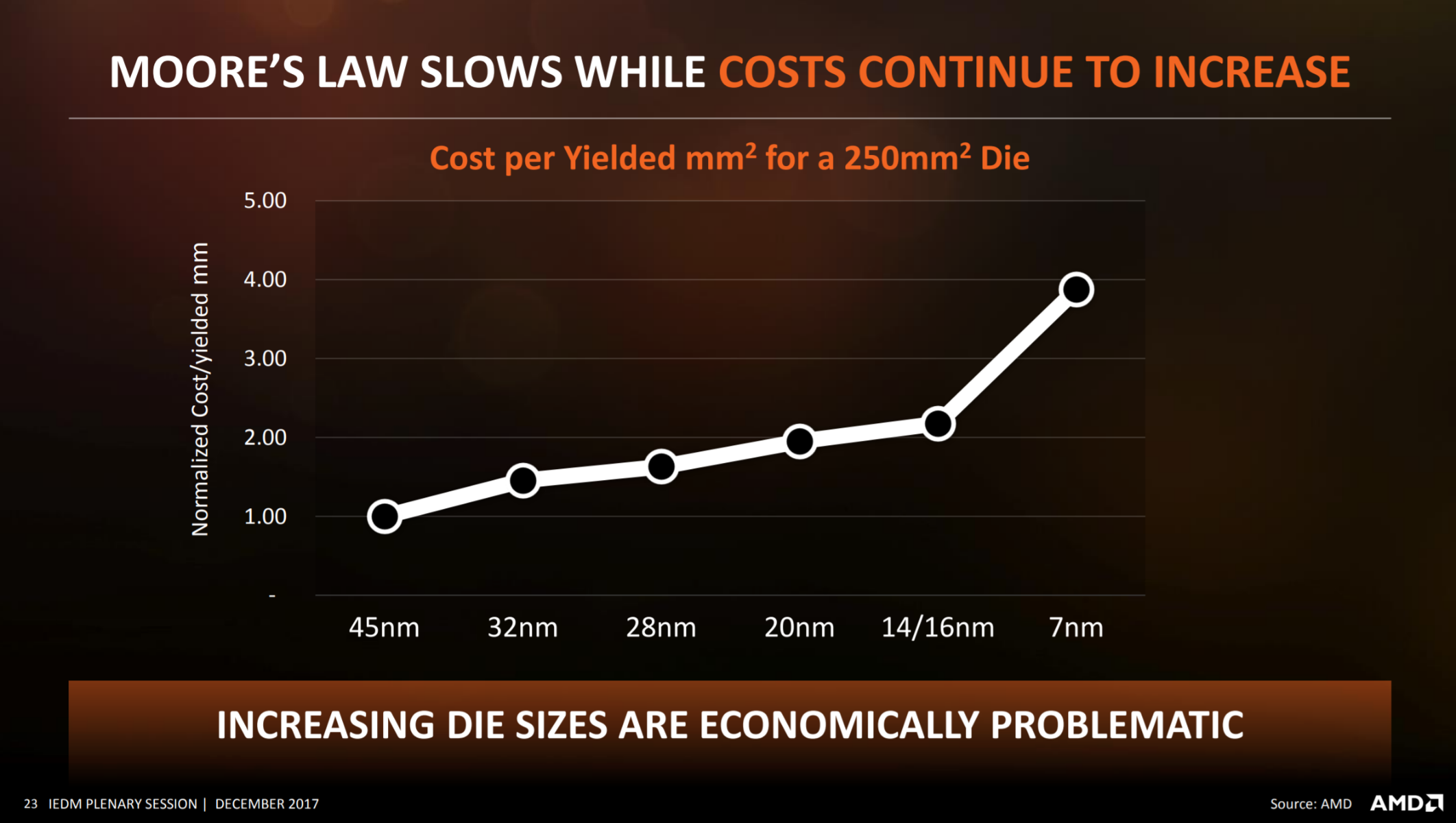
Как видно из графика, при изготовлении кристаллов площадью 250 мм2 переход от 45-нм техпроцесса к 20-нм стоимость производства удваивается и тоже самое можно сказать о переходе от 20-нм техпроцесса к 7-нм. Естественно, дальнейшее совершенствование технологии и переход к ещё более тонким 5- и 3-нм техпроцессам также будут сопровождаться ростом стоимости производства больших кристаллов. Единственный очевидный выход из сложившейся ситуации — производить небольшие монолитные кристаллы, а затем каким-либо эффективным способом объединять их в единый корпус, чтобы и транзисторный бюджет увеличивался и стоимость производства росла не столь сильно.
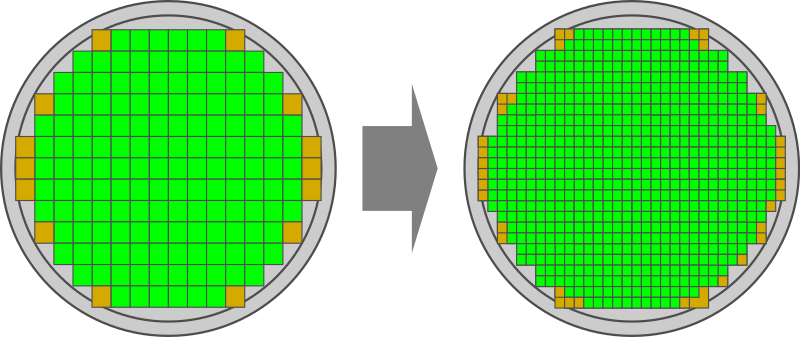
Действительно, в рамках одного техпроцесса выход годных кристаллов с пластины фиксированной площади очевидно тем больше, чем меньше площадь кристаллов, так как:
- Увеличивается удельная площадь пластины, содержащей полноценные чипы (отмеченные зелёным цветом на рисунке выше).
- Уменьшается влияние локальных дефектов пластины, так как потеря одного большого кристалла из-за точечного дефекта кристалла обходится значительно дороже, чем потеря одного маленького.
Так, по расчётам WikiChip, со стандартной на сегодняшний день для индустрии 300-мм пластины можно получить, например, 150 больших кристаллов площадью 360 мм2 или 622 малых кристалла площадью примерно вчетверо меньшей, ~99 мм2 (площадь малых кристаллов должна быть чуть больше четверти площади большого кристалла для реализации связи между кристаллами в чиплете). Из 622 малых кристаллов можно собрать уже 155 чиплетов, объединяющих по 4 малых кристалла и имеющих транзисторный бюджет равный таковому у кристаллов больших. Если же учесть влияние точечных дефектов кремниевых пластин, то можно показать, что выход годных кристаллов площадь 360 мм2 составит всего около 15%, а малых кристаллов площадь 99 мм2 — более чем вдвое больше, 37%.
Кроме того, наиболее передовой техпроцесс необязательно применять для производства всех кристаллов, которые затем войдут в состав готового процессора. Можно распределить функции процессора по различным кристаллам таким образом, что для части кристаллов использованием наиболее передового и тонкого техпроцесса окажется совершенно необязательным. Например, кристалл, содержащий контроллеры различных шин ввода/вывода (USB, PCI-e и т.п.) нет никакой нужды изготавливать по самым передовым нормам, а вот кристаллу, содержащему вычислительные ядра передовой техпроцесс безусловно необходим для покорения новых частот и снижения энергопотребление. Так что многокристальная компоновка будет значительно выгоднее, если только малые кристаллы удастся объединить каким-нибудь высокоскоростным интерфейсом без существенных потерь производительности и существенного увеличения энергопотребления.
Одним из простейших вариантов объединения малых кристаллов является их соединение на обычной печатной платы из текстолита, подобно тому, как многочисленные кристаллы объединяются на материнской плате. Конечно, собрать несколько малых кристаллов на маленьком же кусочке текстолита не легко, но именно такой подход выбрала компания AMD при производстве процессоров микроархитектуры Zen 2.

Конечно, правильно развести многочисленные соединения нескольких кристаллов на небольшой плате у AMD получилось лишь увеличив количество слоёв проводников, существенно усложнив маршрутизацию контактных дорожек и перейдя на другую технологию изготовления контактов на процессорной плате — на смену применявшимся ранее шарообразным контактам пришли цилиндрические медные столбики, которые имеют меньший диаметр и допускают более плотное размещение. Intel, к слову, ранее уже использовала аналогичный подход к компоновке кристаллов при производстве своих первых 2- и 4-ядерных процессоров линеек Pentium D и Core 2 Quad, соответственно, но затем вернулась к монолитному дизайну, так как он оказался выгоднее (в рамках использовавшихся тогда техпроцессов) при переносе в процессор компонентов северного моста, а затем и росте числа ядер.
У описанного выше решения с объединением кристаллов на печатной плате есть, однако, существенный недостаток — ограничение пропускной способности соединений между кристаллами, так что если необходимо объединить кристаллы высокоскоростными соединениями, такой подход не годится. В качестве альтернативного решения малые кристаллы можно объединить, поместив их на общий больший кристалл, задачами которого является предоставление высокоскоростного канала передачи данных между объединяемыми кристаллами и подведение к ним питания. Такой вариант компоновки используется, например, в некоторых видеокартах категории High-End с HBM-памятью. Правда, во многих случаях вместо целого кристалла для указанных целей подойдёт и подложка, в которой имеются лишь узкий кремниевый мост, служащий для объединения кристаллов, и которая используется также для подачи питания на объединяемые кристаллы. Такой более экономный (как с точки зрения затрат на производство, так и использования площади) вариант нашёл своё применение, например, в процессорах Intel Kaby Lake G.

Здесь для объединения кристалла графического процессора AMD Vega с кристаллом высокоскоростной HBM-памяти используется технология объединения кристаллов, получившая название Intel EMIB (Embedded Multi-die Interconnect Bridge), в которой вместо большого объединяющего кристалла используется как раз подложка с кремниевыми каналами передачи данных (кремниевый мост).
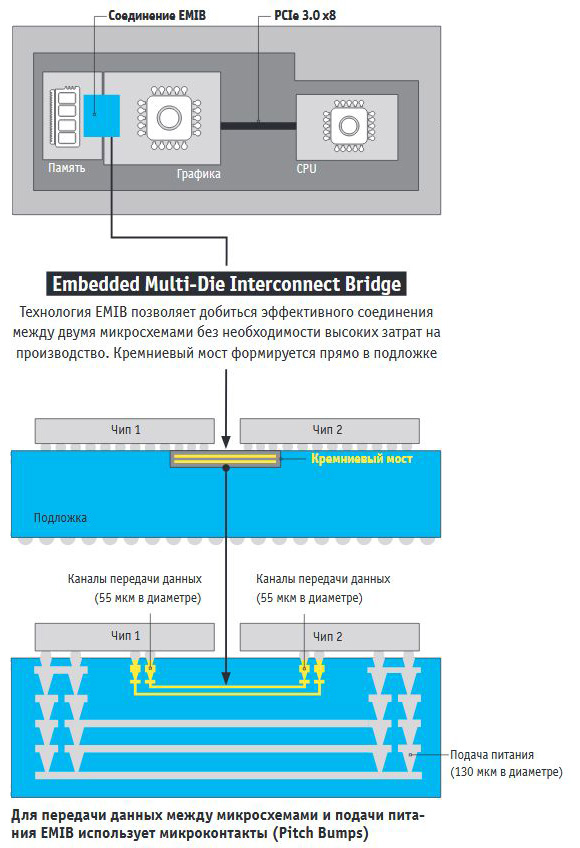
Обе указанные технологии компоновки нескольких кристаллов роднит тот факт, что объединяемые кристаллы расположены в одной плоскости — в плоскости печатной платы, другого кристалла или подложки — и поэтому эти технологии относят к технологиям 2D-компоновки. Хотя, в случае, когда объединяющим началом малых кристаллов служит большой кристалл, иногда говорят о 2.5D-компоновке, так как объединяющий большой и объединяемые малые кристаллы лежат в разных плоскостях, образуя формально 3D-упаковку кристаллов, однако, большой кристалл не содержит в себе никакой логики, а предоставляет лишь каналы связи малых кристаллов и интерфейс подачи на них питания, поэтому и получаем не совсем 3D.
Intel Foveros — следующий шаг развития технологии многокристальной компоновки, представляющий собой уже настоящую 3D-упаковку. Здесь нескольких горизонтально расположенных друг над другом кристаллов объединяются посредством вертикальных каналов, так называемых, сквозных кремниевых межсоединений (англ. through-silicon via, TSV). Подобный способ соединения используется уже многие годы в микросхемах NAND-памяти, хотя в случае с Intel Foveros речь идёт о значительно более высоком энергопотреблении соединяемых слоёв, что усложняет задачу.
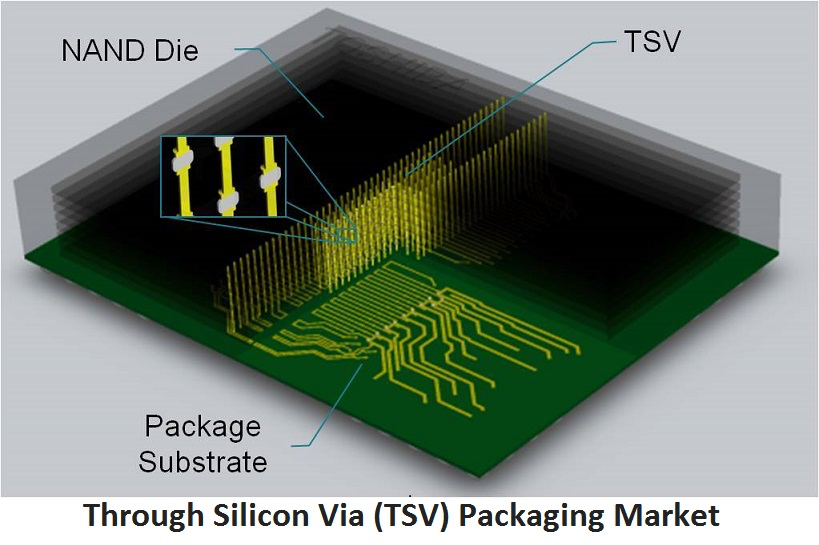
Связь между базовым и вычислительным кристаллами выполняется через Foveros Die Interface (FDI), состоящий из множества микроскопических (36 мкм) контактных выводов (µBumpbs), представляющих собой цилиндрические медные столбики, подобные тем, что используются для изготовления контактов на процессорной плате Ryzen.
При этом скорость передачи данных на контакт в первой реализации особо не впечатляет — эффективная частота FDI составляет около 500 MT/s при ширине интерфейса в 200 бит. Для сравнения — у AMD IF выше как частота (до 3733 MT/s в Zen 2 при делителе 1:1), так и ширина (512 бит). Так что основное преимущество FDI в текущей реализации — это не скорость, а энергоэффективность передачи данных, которая на порядок выше по сравнению с тем же AMD IF: FDI требует всего 0.15 пикоджоуля (пДж, 10-12 Дж) на бит пересылаемых данных, а IF — целых 2 пДж (die-to-die). Преимущество в энергоэффективности над EMIB не столь значительно — 0.15 пДж/бит против 0.30 пДж/бит, и здесь важнее уже достигаемая за счёт вертикальной компоновки меньшая площадь собираемой многокристальной системы.
Очевидно, одной из самых больших проблем подобной компоновки кристаллов будет охлаждение — между выделяющим наибольшее количество тепла 10-нм вычислительным кристаллом и верхней гранью упаковки, с которой это тепло можно снять лежат микросхемы памяти, крайне чувствительные к нагреву. С одной стороны, прямо сейчас в Lakefield тепловыделение — небольшая проблема, ведь первые чипы оптимизированы под очень малый уровень энергопотребления и тепловыделения (TDP 7 Вт), с другой — необходимость нетривиальных инженерных решений для отвода большего количества тепла может сильно затормозить внедрение дизайна Foveros в сегмент более высокопроизводительных решений.
Модели, продукты и будущее технологий
Уже упомянутый в статье Intel Core i5-L16G7 — это старший представитель новой гибридной архитектуры Lakefield, помимо которого пока анонсирован ещё только один процессор, i3-L13G4, отличающийся лишь меньшими тактовыми частотами ядер и меньшим же количеством исполнительных блоков встроенного графического процессора.

Как можно видеть, на данный момент линейка Lakefield состоит всего из двух практически одинаковых моделей процессоров и связано это в первую очередь со сложностью изготовления чипов и необычностью гибридной архитектуры в мире x86-64. Intel не скрывает, что Lakefield — своего рода "пробный шар" компании, так что пока ни о расширении модельного ряда в первом поколении, ни о втором поколении гибридных процессоров Intel никаких заявлений сделано не было. А вот технология 3D-компоновки Foveros будет однозначно развиваться и дальше — следующим продуктом станет ускоритель Ponte Vecchio на основе архитектуры Xe HPC.
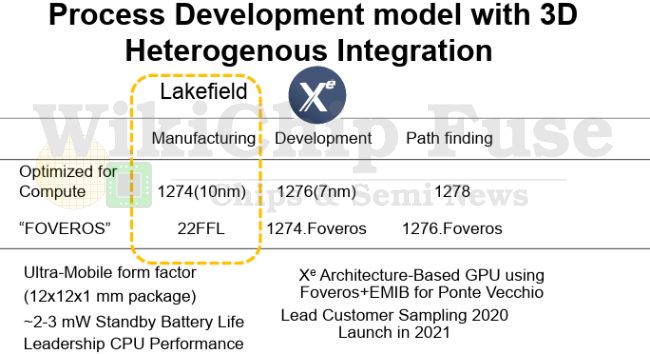
Вычислительный кристалл здесь будет производиться уже по 7-нм техпроцессу (1276), а базовый — по улучшенному 10-нм техпроцессу (1274.Foveros). Выход продукта на рынок ожидается в 2021 году. В недалёком будущем Intel также рассматривает дальнейший переход 3D-компоновки Foveros на техпроцесс 5(?) и 7 нм для вычислительного и базового кристаллов, соответственно, но пока никаких конкретных продуктов, естественно, не анонсировано. Однако, это всё будущее, а в настоящем уже имеются первые устройства на процессорах Lakefield — помимо уже вышедшего на рынок Samsung Galaxy Book S, были анонсированы также Lenovo ThinkPad X1 Fold и Microsoft Surface Neo. Так что как себя проявят первые гибридные x86-64 процессоры в реальном использовании и удастся ли им закрепиться на рынке мы узнаем уже совсем скоро.
Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.