
Постиндустриальная наука: сноб-потребитель и SDRAM память.
<br/><strong>Постиндустриальная наука: сноб-потребитель и SDRAM память.</strong><br/>В этой серии заметок постиндустриальный сноб-потребитель не ведет борьбу с хищниками-производителями, он ... исследует!<br/><em>- Хорошо, когда с тобой товарищи,<br />
<br/>- Всю вселенную проехать и пройти.<br />
<br/>- Звёзды встретятся с Землёю расцветающей,<br />
<br/>- И на Марсе будут яблони цвести.</em><br/>Современного сноба-потребителя, который чтобы до отвала наесться, напиться и удовлетворить все потребности уже не должен тратить все свое время на охоту и собирательство, помимо борьбы с последствиями избытка удовольствий все время тянет на разнообразные исследования самых загадочных явлений во Вселенной, т.е. когда жажда познания живет в снобе-потребителе, она получает все возможности к реализации.<br/>В нашем случае загадочным и неизведанным объектом для исследования представляется область компьютерной оперативной памяти — почему эта память работает?<br/><strong>Почему SDRAM память может работать так быстро?</strong><br/>Как обычно, идем в обход и используем много дополнительных сведений.<br/><strong>Содержание.</strong><br/>1. SRAM.<br />
<br/>2. DRAM.<br />
<br/>3. Временн'ая диаграмма DRAM.<br />
<br/>4. Синхронизация.<br />
<br/>5. Пакетная память SDRAM.<br />
<br/>6. CPU cache test (console version) и память им. Б. Гейтса.<br />
<br/>7. Потребительские перспективы.<br/><p style="margin-bottom: 0cm;">
<br/><br />
<br/>
реклама
Постиндустриальная наука: сноб-потребитель и SDRAM память.
В этой серии заметок постиндустриальный сноб-потребитель не ведет борьбу с хищниками-производителями, он ... исследует!
- Хорошо, когда с тобой товарищи,
- Всю вселенную проехать и пройти.
- Звёзды встретятся с Землёю расцветающей,
- И на Марсе будут яблони цвести.
Современного сноба-потребителя, который чтобы до отвала наесться, напиться и удовлетворить все потребности уже не должен тратить все свое время на охоту и собирательство, помимо борьбы с последствиями избытка удовольствий все время тянет на разнообразные исследования самых загадочных явлений во Вселенной, т.е. когда жажда познания живет в снобе-потребителе, она получает все возможности к реализации.
В нашем случае загадочным и неизведанным объектом для исследования представляется область компьютерной оперативной памяти — почему эта память работает?
Почему SDRAM память может работать так быстро?
Как обычно, идем в обход и используем много дополнительных сведений.
Содержание.
1. SRAM.
2. DRAM.
3. Временн'ая диаграмма DRAM.
4. Синхронизация.
5. Пакетная память SDRAM.
6. CPU cache test (console version) и память им. Б. Гейтса.
7. Потребительские перспективы.
1. SRAM.
Самая простая память, которая нас интересует, это триггер. Это название из электроники, потому что есть реальный электронный компонент, который выполняет такую функцию.
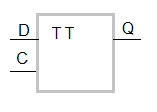
Например, на рисунке «tt.png» изображен D-триггер, значение сигнала 0 или 1 на входе D появляется на выходе Q по сигналу записи C и после снятия сигнала записи С это значение сигнала сохраняется на выходе триггера независимо от состояния входа D, т.е. сигнал как бы запоминается.
Если несколько триггеров соединить параллельно, то получается регистр. Это тоже название из электроники и тоже оттого, что есть реальный электронный компонент, который выполняет такую функцию.
Например, запустите какой-нибудь отладчик, например debug и выполните
-o 378,0
-i 378
00
Это потому, что по адресу 378 находится самый настоящий 8бит аппаратный регистр, вы записали туда 0 и прочитали оттуда 0. Это регистр данных LPT – параллельного интерфейса принтера для IBM PC (если не получается, попробуйте эмулятор IBM PC – DOSbox).
Теперь наберите
-o 377,0
-i 377
FF
Это потому, что по адресу 377 обычно нет регистра, ноль записать некуда, вы записали туда 0, но прочитали оттуда FF (в IBM PC считывание из несуществующего устройства или памяти возвращает FF).
Другой пример, для которого вам может быть не понадобится даже эмулятор, запустите "winkey+R debug" и выполните
-r ax
ax 0000
:1
-r ax
ax 0001
Вы записали в регистр ax процессора 1 и прочитали оттуда 1.
Если взять несколько регистров, например 16 штук, то у нас получится статическая память SRAM на 16 байт — на параграф в терминах x86, в которой можно будет адресовать каждый регистр по адресам 0-15.
Итак, статическая память, SRAM, это набор триггеров, сгруппированных в адресуемые регистры.
Статическая память всем хороша, если память выполнена по нужной технологии, то ее быстродействие может быть сравнимо с быстродействием регистра процессора, а потребление энергии в режиме хранения может быть низкое.
Но изначально ее было трудно изготавливать массивами большого размера, не было подходящих элементов памяти — быстрые элементы памяти потребляли слишком много энергии в режиме хранения, экономичные работали слишком медленно и те, и другие были не только геометрически слишком большие (в 2-5 раз больше, чем элемент памяти для DRAM), но и довольно сложные по конструкции (опять же, по сравнению с DRAM, триггер это всегда несколько активных компонентов - транзисторов или их аналогов), поэтому при росте числа элементов памяти в массиве вероятность изготовления бракованной микросхемы повышалась, в результате чтобы из-за одного неисправного бита не выбрасывать всю микросхему ее надо было бы изготовлять с избыточными резервными элементами, со схемами промежуточного тестирования и коррекции и после тестов исключать сбойные части, такой подход применяется к более дорогим устройствам, таким как процессоры.
В результате традиционно применение SRAM это СОЗУ — скоростное ОЗУ — регистры процессора, кэш и т.п. ускоряющие компоненты относительно небольшого объема.
2. DRAM.
Одним из популярных элементов памяти стал обычный конденсатор, выполненный, естественно миниатюрно, на кристалле микросхемы. Память на основе конденсаторов называется динамической памятью, DRAM.
Итак динамическая память, DRAM, это набор конденсаторов, сгруппированных в адресуемые регистры.
Например, запустите "winkey+R debug" и выполните
-r ax
AX 0000
:0
-a 100
xxxx:0100 mov AL, [0]
xxxx:0103
-t =100
AX=00CD …
Вы записали в регистр AL значение 0, а затем прочитали из DRAM памяти по адресу [0] в регистр AL значение CD.
Просто конденсатор.
Эта память называется динамической потому, что страдает склерозом, поскольку с течением времени конденсаторы разряжаются, то информация из памяти на их основе постепенно исчезает, через некоторое время (буквально через пару секунд) вся динамическая память будет содержать только нули (или только единицы, в зависимости от конструкции конкретного типа микросхем памяти).
Довольно трагические последствия и даже непонятно кому только в голову пришла такая странная идея использовать столь непригодный элемент для хранения данных.
Динамическую память на практике лечат от склероза традиционным образом — периодически напоминают ей то, что она хранит. Это называется регенерация.
Поскольку регенерация это такой процесс, когда записываются те же данные, которые считываются, то конструкция элемента динамической памяти может иметь специальные приспособления, чтобы облегчить регенерацию и не передавать данные между памятью и процессором, данные как бы крутятся внутри микросхемы.
Понятно, что специальные элементы микросхемы для регенерации могут даже полностью скрыть от внешнего мира внутреннюю динамическую структуру памяти и необходимость регенерации.
При производстве данного типа микросхемы в зависимости от возможностей технологии и требуемого размера массива памяти на кристалле применяется механизм упрощения регенерации того или иного типа или механизм упрощения регенерации совсем не применяется.
Геометрически конденсатор это довольно маленький элемент (роль конденсатора могут выполнять части других электронных компонентов элемента хранения), изготовить конденсатор с ошибкой труднее, чем транзистор, конденсатор при хранении данных не потребляет энергии, поэтому на кристалле одного размера можно разместить больше элементов памяти, чем для SRAM, однако заряд конденсатора требует времени, поэтому традиционно применение DRAM это ОЗУ — довольно большая, довольно медленная основная память.
Слишком много проводочков.
Поскольку применение DRAM это довольно большая основная память, то большие массивы элементов памяти на одном кристалле начинают содержать довольно много соединительных проводящих линий, которые передают данные, адресуют регистры и т.д. В результате эти вспомогательные соединительные проводники начинают занимать заметное место на кристалле с ростом размера массива памяти, вытесняя основные элементы памяти.
Сложность при размещении проводников вызывает факт того, что в отличие от элемента памяти, который занимает некий локальный «квадратик» на кристалле, который можно расположить на нем произвольно, проводник это глобальный элемент, при его размещении надо «обрулить» не только другие квадратики, но и другие проводники, идущие к другим квадратикам, при этом пересечения с другими проводниками не допускаются, а число слоев (по которым проводники могут проходить по одной точке кристалла, но на разной глубине) ограничено.
Например, рассмотрим кристалл содержащий массив памяти адресуемый 16 битами — сегмент реального режима х86, для адресации всех 65536 элементов памяти нам надо разместить на кристалле 65536 независимых адресных проводников, плюс общие проводники для переноса данных и общие проводники для управления элементами памяти.
Чтобы оценить сложность такого размещения, возьмите лист клетчатой бумаги, пометьте на ней в центре несколько клеток в виде матрицы из 4 на 4 (это элементы памяти) сначала размещая их через одну пустую клетку и попытайтесь вывести за пределы матрицы (к краям листа) от каждого элемента памяти по три линии (по одной непересекающейся (адрес) и по две пересекающиеся с аналогичными у других элементов (данные и управление — чтение или запись)) при условии, что каждая линия занимает целую клетку (линии могут проходит по соседним клеткам не пересекаясь). Если не получается, то увеличьте число промежуточных клеток (сначала до двух). Затем увеличьте размер элемента памяти, например 2х2 клетки или число элементов памяти, например 8 на 8 элементов.
Будет видно, что глобальные проводники это бедствие и иногда лучше увеличить локальный размер элемента памяти в два раза, чем число глобальных проводников в два раза.
Значение «65536 проводников» внушает уважение, так много адресных проводников получается потому, что наш элемент памяти очень мал, он не содержит ничего, кроме конденсатора и компонент его обслуживания, поэтому к каждому элементу памяти надо доставить персональный адресный сигнал - независимый от таких же сигналов у других элементов памяти, который укажет, что данный элемент памяти надо включать в работу по чтению или записи данных.
В отличие от адресного сигнала, сигналы данных и управления для всех элементов памяти в массиве общие (пересекаются), но они имеют смысл только для того адресного элемента, для которого активен его персональный адресный сигнал.
Преобразование входного адреса в виде числа в выходной персональный адресный сигнал (только один из выходных проводников содержит активный выходной сигнал) называется дешифрированием, это тоже название из электроники и тоже оттого, что есть реальный электронный компонент, который выполняет такую функцию.
У нас адрес дешифрируется на уровне всей микросхемы (и в дешифрированном виде доставляется элементу памяти), а не на уровне элемента памяти.
Например, PCI слоты адресуются таким же образом — каждый слот PCI имеет свою персональную адресную линию, которая дешифрируется в чипсете и используется при конфигурации устройства в конкретном слоте.
Вот если бы адрес можно было дешифрировать на уровне элемента памяти, а не на уровне всей микросхемы, то заместо 65536 проводников нам бы понадобилось только 16. Большая экономия. Однако есть проблема — дешифратор очень уж сложный элемент, даже сложнее чем регистр.
Значит нам нужен конценсус и компромисс — поместить в элемент памяти самый компактный но неполный дешифратор, а другой оставшийся неполный дешифратор поместить на уровне микросхемы, т.е. надо дешифрировать в несколько этапов, тогда к элементу памяти пойдут общие для всех проводники, а не персональные линии.
Это все и привело к появлению знаменитых сигналов RAS (выбор строки) и CAS (выбор столбца) для DRAM.
Квадрат это то, что надо.
Не будем решать общую задачу поиска оптимального количества проводников, но если у вас квадратная матрица из элементов памяти, то число строк равно числу столбцов и равно квадратному корню из общего числа компонентов матрицы, в нашем случае для 65536 элементов мы имеем квадрат со стороной в 256 элементов.
Оказалось, что физически элементы памяти на кристалле размещены на плоскости и их легко можно логически и даже физически расположить в виде квадратной матрицы и использовать общий адресный проводник для каждой строки и общий адресный проводник каждого столбца. В нашем случае общее число адресных проводников стало равно 512 вместо 65536 (в 128 раз меньше), а каждый элемент памяти соединяется с двумя адресными проводниками, содержащими частично дешифрированный адрес.
Также оказалось, что в таком случае неполный дешифратор в элементе памяти очень прост и сравним с самим элементом памяти, это электронная схема «логическое И для двух входов».
Выбор элемента памяти очень прост, схема «2И» срабатывает у того элемента памяти, который находится на пересечении активной линии сроки или столбца. У всех остальных элементов памяти хотя бы один из входов их «2И» попадает на пассивную линию строки или столбца, оставляя элемент в пассивном состоянии.
Для дешифрирования адреса строки в нашем случае нужен дешифратор в 256 значений, это 8 бит число. Для дешифрирования адреса столбца в нашем случае тоже нужен дешифратор в 256 значений, это тоже 8 бит число.
Значит, исходный 16 бит адрес разделился на два компонента — адрес строки 8 бит и адрес столбца 8 бит. Традиционно адрес строки это старшие биты, а столбца младшие.
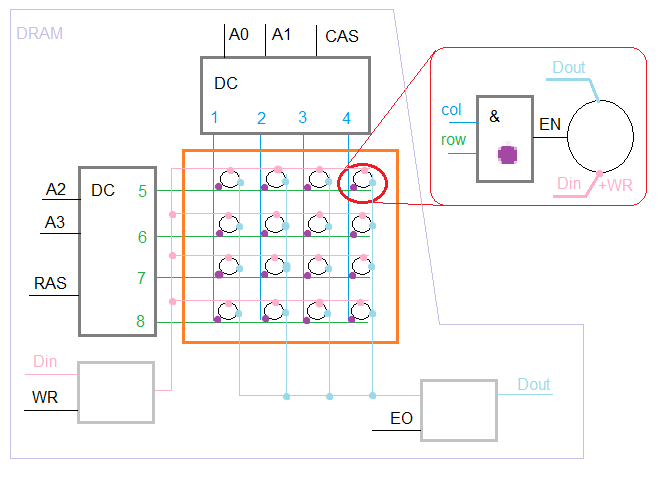
На рисунке «dram.png» изображена типовая схема динамической памяти для массива 4х4 элемента памяти — на 16 байт.
3. Временн'ая диаграмма DRAM.
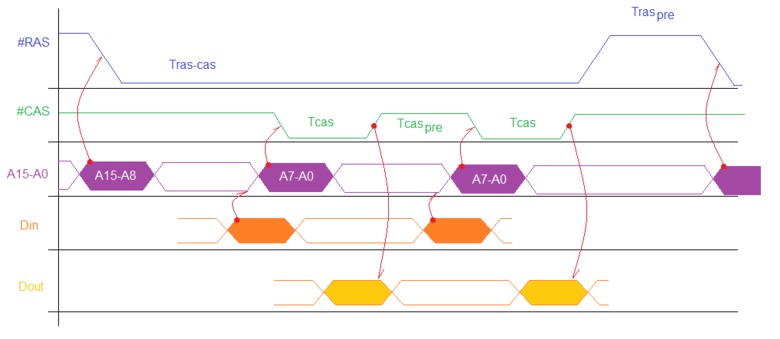
На рисунке «dram_timing.png» изображена типовая диаграмма работы динамической памяти.
Все то, что говорилось, но в процессе, во времени. Процессор формирует адрес строки в линиях A15-A8 и записывает их в память сигналом #RAS.
Запись в память (Din) — процессор выжидает время между RAS и CAS (Tras-cas), при этом он устанавливает данные для записи в память на линиях Din и формирует адрес столбца в линиях A7-A0, затем записывает этот адрес в память сигналом #CAS и данные сигналом #WR (на рисунке #WR не показан). Выдерживает время доступа к столбцу (Tcas) и снимает сигнал #CAS на время не менее TcasPRE (время восстановления после #CAS). Через время TcasPRE процессор аналогично записывает новые данные в память новым сигналом #CAS.
Чтение из памяти (Dout) — процессор выжидает время между RAS и CAS (Tras-cas), при этом он формирует адрес столбца в линиях A7-A0, затем записывает этот адрес в память сигналом #CAS. Выдерживает время доступа к столбцу (Tcas) и по его заднему фронту считывает данные из памяти. Выдерживает время доступа к столбцу (Tcas) и снимает сигнал #CAS на время не менее TcasPRE (время восстановления после #CAS). Через время TcasPRE процессор аналогично считывает новые данные из память новым сигналом #CAS.
Первое, что приходит в голову, так это почему нельзя сразу установить данные A15-A0 и сразу записать их в микросхему одним сигналом #AS?
Исторически адрес строки и столбца подавался в микросхему по одним и тем же ножкам (мультиплексированный адрес), это потому, что шаг ножек был 2.5(2.54)мм, а ножек много, поэтому без такого мультиплексирования повсюду компьютер типа IBM PC XT имел бы материнскую плату, размер которой исчислялся бы в квадратных метрах, а не в квадратных дециметрах.
Ну и потом, быстрый дешифратор 8в256 это достаточно сложный электронный компонент, возможно, что в микросхемах памяти для обработки обоих частей адреса тогда использовался один и тот же дешифратор.
Если ограничений на количество ножек и дешифраторов нет, то можно использовать один сигнал #AS и подавать обе порции адреса сразу.
В любом случае, режим работы DRAM памяти, который изображен на временной диаграмме, называется FPM или «только CAS», при этом сигналом RAS открывается «страница» памяти (на деле строка) и сигналом CAS перебираются столбцы.
Даже та DRAM память, которая используется в таком компьютере как ZX Spectrum, может работать в режиме FPM, поэтому возможность работы DRAM памяти в таком режиме определяется только самим компьютером (контроллером памяти) и процессором.
Компьютеры типа ZX Spectrum, IBM PC XT, IBM PC AT 286/386 ранних моделей не могут работать с DRAM памятью в режиме FPM и каждый цикл генерируют пару сигналов «режим RAS+CAS», но отметим, что производительность памяти для компьютеров типа ZX Spectrum, IBM PC XT-4МНц/8МНц, IBM PC AT 286-6МГц в «режиме RAS+CAS» была достаточна и даже избыточна и ее невозможно было бы ускорить с помощью «режима только CAS», не успевал бы процессор. Возможно, что существует очень старая DRAM память, выпущенная в районе 1980 года, которая не может работать в режиме FPM.
Тогда остается только вопрос к воротилам компьютерного бизнеса: какого черта такой замечательный и перспективный интерфейс DRAM был отвергнут? Выждал 5 наносекунд, записал, выждал 10, записал, выждал 33, прочитал, выждал 12, опять готов к работе. Мечта. Что еще надо?
Оказывается, все дело было в синхронизации.
4. Синхронизация.
Не вдаваясь в детали отметим, что аппаратная реализация компьютера упрощается, когда в системе есть некий сигнал, относительно которого происходят все процессы — синхросигнал, CLC.
Понятно, что одна и та же электронная схема может работать быстрее, если такой синхросигнал будет иметь более высокую частоту. Некоторые люди даже занимаются на практике изучением вопроса увеличения производительности системы путем увеличения частоты синхросигнала.
Мы рассматриваем не все виды памяти, а ту, которая использует синхросигналы или используется в системах с синхросигналом.
Так вот, если вы заметили, DRAM память не имеет никакого синхросигнала и даже называется асинхронной. Все параметры такой памяти измерены в наносекундах и допускают вариации в довольно-таки значительных пределах.
Теоретически, такая гибкость DRAM памяти дает возможность использовать ее практически в любых системах, она способна приспособиться к любому компьютеру, с этими целями ее и создавали.
Но эта широта профиля только на первый взгляд. Когда дело доходит до дела оказывается, что измерять наносекунды это задача не для слабонервных компьютеров, которые ничего такого даже и не собираются делать, а идут по пути наименьшего сопротивления и тупо привязывают все сигналы управления памятью к своей тактовой частоте и к протоколу своей системной шины.
Вот тут то и оказывается, что системная шина каждого конкретного компьютера совершенно несовместима с протоколом обмена с DRAM памятью в плане сохранения эффективности, потому как критерии эффективности для доступа к ячейке DRAM памяти не совпадают с теми же для обмена по системной шина компьютера.
Короче говоря, если привесить DRAM память прямо на системную шину компьютера, как это все и делали, то с огромной долей вероятности вам придется вводить «лишние» такты ожидания.
Такты ожидания являются лишними потому, что цикл чтения памяти в вашем процессоре равен, скажем 30нс (33МГц), и DRAM память имеет время доступа к ячейкам в пределах строки Tcas+TcasPRE тоже 30нс (60нс DRAM), но вы не можете работать с памятью на такой скорости и вынуждены вставлять такты ожидания потому, что моменты времени, в которые процессор пишет и читает данные с системной шины не совпадают с теми же, когда микросхема DRAM памяти читает и пишет данные.
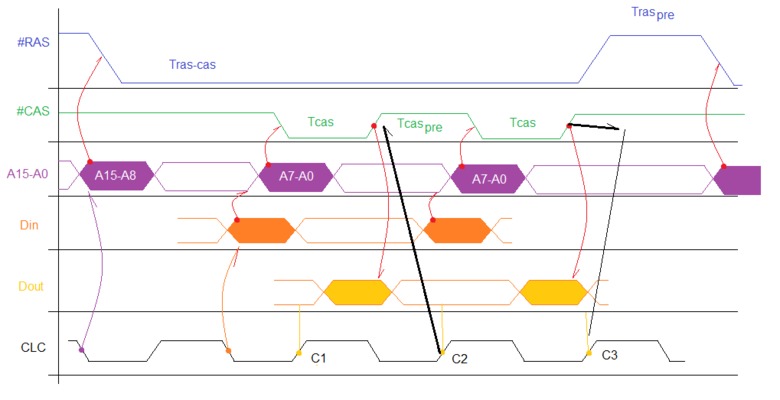
В этом то и вся проблема (рисунок «cpu_dram.png»).
В общем наш гипотетический процессор выдает данные при записи в память как можно раньше, а считывает их при чтении как можно позже, давая внешним устройствам как можно больше времени на их обработку, однако моменты времени, когда данные реально переносятся в процессор привязаны к перепадам сигнала синхронизации.
На рисунке на графике CLC моменты С1, С2 и С3 это те моменты, когда процессор может принять данные от памяти.
В первом случае С1 память хоть и работает с максимальной скоростью но не успевает и мы вводим такт ожидания правильно, это вызвано тем, что перед CAS шел RAS, мы «открывали страницу».
А вот во втором случае С2 память убрала данные слишком быстро, процессор не успел их прочитать, поэтому контроллер памяти вынужден удлинить Tcas сверх оптимального времени (жирная черная стрелка). Но TcasPRE укоротить уже будет нельзя, вот из-за этого и удлиняется общий цикл «только CAS» равный Tcas + TcasPRE.
Последнее приводит к тому, что в момент C3 память еще не готова выдать данные и мы должны ввести это самый «лишний» такт ожидания, хотя интервал времени Tcas + TcasPRE равен интервалу времени C2-C3 (рисунок не в масштабе), т.е. по времени память и процессор могут работать без «лишних» тактов ожидания.
Именно поэтому на свет появилась такая интересная модификация DRAM памяти, как EDO. На нашей временной диаграмме работы DRAM памяти видно, что процессор должен считать данные из памяти по заднему фронту сигнала #CAS, поскольку позже микросхема DRAM памяти их оттуда снимает, но поскольку к перепадам CLC системной шины привязаны: начало генерации сигнала #CAS и момент когда процессор считывает данные, реально процессор считывает данные намного позже этого исторического момента (заднего фронта сигнала #CAS), во время интервала TcasPRE. Вот тут то EDO память и выручает незадачливых конструкторов компьютеров, поскольку имеет внутри себя регистр который удерживает данные на выходе DRAM в корректном состоянии и после заднего фронта сигнала #CAS, интервал времени Tcas + TcasPRE не удлиняется. Ура.
Обратим внимание, что многочисленные руководства по аппаратным частям для IBM PC совместимых компьютеров (без цитат) весьма невнятно или совсем неправильно и драматически повествуют о том, как можно героически ускорить память, всего лишь установив в нее регистр, что несомненно озадачивает читателей и вгоняет их в ступор и в тупое недоумение.
Впервые бонусом от EDO памяти воспользовались на компьютерах с Socket7, которые будучи 32 битными и работая на частоте шины 66МГц имели удвоенную шину данных памяти (64бит), на каждой из половинок которой висела доступная в продаже 32 битная EDO память 60нс, которая может работать на частоте 33МГц без лишних тактов ожидания. Таким образом, такой 32 битный процессор получал эквивалентную 32 битную шину памяти, способную работать на частоте 66МГц без лишних тактов ожидания.
Аналогичный прием использовался в двухканальной шине LGA1156. Доступная в продаже DDR3 PC-10600 память с таймингом 8 на 666МГц передает данные на скорости 5328МБ/с, через два канала шириной 128 бит этот 64 битный процессор может передавать данные со скоростью 10656МБ/с, т.е. имеет эквивалентную 64 бит одноканальную память DDR3 PC-10600 без лишних тактов ожидания.
Теоретически (не на чем проверить), трехканальный вариант таких сокетов позволяет установить в них на 17% более быстродействующую память (которая стоит на 50% дороже) с таймингом 6.5 (или с таймингом 7 и частотой 713МГц) и в итоге на трех каналах шириной 192 бита получить эквивалентную двухканальную память без лишних тактов ожидания, т.е. в два раза быстрее чем для двухканального сокета.
Да, но вернемся к DRAM. Ясно, что DRAM тут не причем, регистр можно было бы установить и в контроллер памяти и использовать обычную DRAM не хуже чем EDO, но это не было сделано хищниками-производителями.
В общем ясно, что эффективное применение DRAM памяти целиком зависело от контроллера памяти конкретного компьютера и на реальных компьютерах оно не было очень эффективным.
Процессоры начиная с i486 уже желали обмениваться с памятью в пакетном режиме целыми кэш-линиями и в принципе не нуждались в универсальной асинхронной памяти типа DRAM.
И вот, на арену выходит синхронная память SDRAM, которая, содержа в себе обычную память типа DRAM, также переносит и часть контроллера памяти из компьютера внутрь себя, обмениваясь с компьютером по протоколу на основе синхронизации, теперь то уж все проблемы согласования целиком легли на плечи производителей памяти.
Помимо усложнения микросхем памяти, которые теперь содержали в себе часть контроллера памяти, синхронный протокол позволял полностью скрыть от компьютера внутреннее устройство памяти, что теоретически позволяло производителям делать более быструю память и более того, тихо и мирно отказаться от конденсаторов в качестве элемента памяти.
Но практически все для начала получили RDram, в качестве приветствия.
5. Пакетная память SDRAM.
Про нее для наших целей изучения вопроса «Почему SDRAM память может работать так быстро» и говорить нечего и мы сразу перейдем к ее усовершенствованной модификации — DDR. Основной смысл модификации для нас в том, что в каждом такте передается две порции данных (по фронту и по спаду синхросигнала), а не одна.
Работа с синхронной памятью в принципе не сложна - в первом такте синхронизации вы передаете команду, например «чтение» и через число тактов CL (CAS latency) можете прочитать пакет из четырех 64 битных передач — 32 байта кэш линия, читая за каждый такт две передачи (на передачу данных пакета тратится два такта синхронизации).
Мысленно посмотрим на планку DDR памяти с параметрами CLC=133МГц и CL=2 и глубоко задумаемся. Если процессор может генерировать чтение-запись с упреждением (т.е. когда ему есть что читать/записывать), то такая память может непрерывно читать/писать пакеты со скоростью:
133(МГц)/2(такта/трансфер)=66(Мтрансферов/с)
66(Мтрансферов/с)*32(байта/трансфер)=2128(Мбайт/с)
при том что ее последний 60нс DRAM аналог:
33(МГц)/4(такта/трансфер)=8(Мтрансферов/с)
8(Мтрансферов/с)*16(байт/трансфер)=128(Мбайт/с)
128(Мбайт/с)*2(канала)=256(Мбайт/с)
Разница в 8 раз! Неужели это 8нс DRAM?
Итак, у нас на деле есть два способа увеличивать производительность системы памяти. Первый способ — параметрический, это как раз 8нс DRAM, т.е. создается элемент памяти, который может работать с более высокой скоростью. Второй способ — схемотехнический, когда ускорение работы достигается с теми же самыми элементами памяти за счет их более правильного использования.
Про первый способ нечего сказать, это знают только производители микросхем, а вот про второй есть что сказать.
На самом деле мы уже говорили про второй способ, один из вариантов схемотехнического ускорения был применен в socket7, когда 32 битный процессор обращался к медленной памяти по удвоенной шине, что давало удвоение пропускной способности памяти, кстати, это было преподнесено в рекламе DDR как открытие Америки в виде «специальная архитектура 2n Prefetch» и благополучно размножено в интернете специалистами по рефератам.
Рассмотрим «специальную архитектуру» подробнее. Имеем 64 бит шину SDRAM и 128 бит внутреннюю шину, представим, что она внутри разделена на два канала по 64 бит, предположим, что в каждом канале одновременно начинается выборка данных, которая одновременно заканчивается через CL и каждый канал поочередно выдает 64 бит данные за один период CLC. Хорошо, но мало. У нас 4 передачи по 64 бита, а не две. Как быть?
Позволю себе усовершенствовать DDR до «учетверения» внутренней шины данных. Теперь у нас прогрессивная 256 бит внутренняя шина и внутри она творчески разделена на четыре канала по 64 бит, в каждом канале одновременно начинается выборка данных, которая одновременно заканчивается через CL и каждый канал поочередно выдает 64 бит данные за два периода CLC. Отлично.
Но есть одно но. Удвоение шины не может помочь с задержкой появления первой передачи в пакете. Параметр CL в SDRAM характеризует параметрическую скорость данной памяти, скорость ее элемента памяти.
С характеристиками CLC=133МГц и CL=2 задержка элемента памяти:
133(МГц)/2(такта/выборку)=66(Мвыборок/с)
1/66(Мвыборок/с)=15нс/выборку на режим «только CAS»
У нас эквивалент 30нс DRAM, параметрически это только в два раза лучше, чем на i486 или pentium I, все остальные преимущества достигнуты схемотехнически.
Пакетный режим передачи данных, реализованный начиная с i486 не только уменьшает объем данных для передачи, устраняя адресную информацию, но и очень помогает применять схемотехнические методы ускорения работы памяти.
Плата за эти удобства тоже есть — процессор может обращаться к памяти только большими блоками, фактически, тенденция пакетного обмена в том, что SDRAM память перестает быть «памятью с произвольным доступом» и становится «потоковой памятью». Такое возможно потому, что в таком процессоре есть еще память, а именно кэш память, которая и является реально RAM памятью.
Если считать RAM памятью кэш первого уровня, то известные слова «о 640Кбайтах RAM, которых хватит на долго» можно возвести в пророчество, которое сбылось. Как видим, пророчество найти легко, было бы желание.
Слишком большой CL. Есть ли смысл в том, чтобы задать CL для такой памяти еще меньше, например CL=1? Нет, потому что передача пакета занимает 2 такта. Делать CL меньше чем число тактов в пакете нет смысла, потому что при конвейерной передаче пакеты будут следовать друг за другом без пустых тактов начиная с CL численно равной числу передач в пакете.
Если у нас есть параметрически более скоростная память, лучше чем эквивалент 30нс DRAM, то надо повышать частоту CLC. Например, для эквивалента 24нс DRAM, CL=2 и размере пакета в 2 такта CLC, эта CLC=(1/12)*2=166МГц.
Слишком маленькая внутренняя ширина шины. Есть ли смысл в том, чтобы не «учетверить», а, например, «увосьмерить» внутреннюю шину данных DDR памяти? Нет смысла увеличивать внутреннюю шину в большее число раз, чем размер пакета. Для четырех передач пакета DDR максимальная внутренняя логическая ширина 256 бит, для восьми передач пакета DDR3 максимальная внутренняя логическая ширина 512 бит.
Для восьми передач пакета DDR3 нужен 64 битный процессор или процессор с кэш линией 64 байта, а не 32 байта.
Если взять элемент памяти DDR параметрически эквивалентный 30нс DRAM и засунуть его в DDR3, то поскольку размер пакета равен не двум, а четырем тактам CLC, минимальный CL=4, минимальная частота CLC=266, максимальная внутренняя ширина 512 бит. Посчитаем пропускную способность:
266(МГц)/4(такта/трансфер)=66(Мтрансферов/с)
66(Мтрансферов/с)*64(байта/трансфер)=4256(Мбайт/с)
Скорость в 16 раз выше, а параметрически это только в два раза лучше, чем на i486 или pentium I, все преимущества достигнуты схемотехнически.
В чем же смысл «х» усовершенствований для DDRx? В том, что изменяются в основном электрические параметры, а не принцип работы, это связано с уменьшением напряжения и увеличением частот.
Каковы параметры реальной DDR3 PC-10600 c CL=8?
666(МГц)/8(такта/трансфер)=83,25(Мтрансферов/с)
83,25(Мтрансферов/с)*64(байта/трансфер)=5328(Мбайт/с)
666(МГц)/2(такта/выборку)=83,25(Мвыборок/с)
1/83,25(Мвыборок/с)=12нс/выборку на режим «только CAS»
Это эквивалент 24нс DRAM.
6. CPU cache test (console version) и память им. Б. Гейтса.
Рассуждая о скоростях памяти мы не можем, не должны обойти стороной такой знаменитый шедевр программистской мысли, как бесплатная консольная версия утилиты для тестирования кэша процессора - cctc (см. Еще один тест скорости системной памяти и кэша процессора с открытым исходным кодом).
Если избавиться от высокопарных слов, то cctc это та самая надежная и любимая еще с ДОС времен утилитка, которая показывает нам размер кэша и скорость его работы.
Наупражнявшись в теории, всегда хочется проверить ее на практике: а как сконфигурирована моя система с точки зрения производительности подсистемы памяти? Как на подсистему памяти влияет, например, добавление второго канала, изменение CL памяти, частоты NB_CPU или CPU?
Например, если верить популярной в сети информации, то добавление второго канала увеличивает производительность подсистемы памяти всего на 5%, хотя мы только что убедились, что добавление второго канала внутрь микросхемы удваивает скорость ее работы, это же «специальная архитектура 2n Prefetch»! Т.е. Если все нормально, то должна удваивать.
Давайте посмотрим на вывод от cctc для моего AMD-FX4100 и что мы там сможем увидеть:
1 - output thread file testout.01
#FSB:4242.0 MHz
#CPU_mult: 1.0
#Estimated CPU speed: 4.242 GHz
#test pattern: '0x01'
#test version: v0.06
#number of threads: 1
#base output file name: "testout"
pass: block size: clc: seconds: transfer rate:
----------------------------------------------------------------------------------------------
01: 2K: 2.178500e+004: 5.135549e-006s: 31155381.20Kb/s ( 30425.18Mb/s, 29.71Gb/s )
02: 4K: 3.630100e+004: 8.557520e-006s: 35056884.43Kb/s ( 34235.24Mb/s, 33.43Gb/s )
03: 8K: 1.260710e+005: 2.971971e-005s: 18842715.04Kb/s ( 18401.09Mb/s, 17.97Gb/s )
04: 16K: 2.781690e+005: 6.557497e-005s: 15859710.70Kb/s ( 15488.00Mb/s, 15.12Gb/s )
05: 32K: 4.895290e+005: 1.154005e-004s: 16637706.35Kb/s ( 16247.76Mb/s, 15.87Gb/s )
06: 64K: 1.158328e+006: 2.730618e-004s: 12890856.09Kb/s ( 12588.73Mb/s, 12.29Gb/s )
07: 128K: 1.962017e+006: 4.625217e-004s: 13837188.56Kb/s ( 13512.88Mb/s, 13.20Gb/s )
08: 256K: 4.518844e+006: 1.065263e-003s: 10814234.46Kb/s ( 10560.78Mb/s, 10.31Gb/s )
09: 512K: 6.286528e+006: 1.481973e-003s: 13819417.87Kb/s ( 13495.53Mb/s, 13.18Gb/s )
10: 1024K: 1.316896e+007: 3.104422e-003s: 11544821.95Kb/s ( 11274.24Mb/s, 11.01Gb/s )
11: 2048K: 4.115773e+007: 9.702435e-003s: 6332431.14Kb/s ( 6184.01Mb/s, 6.04Gb/s )
12: 4096K: 7.228155e+007: 1.703950e-002s: 6009566.58Kb/s ( 5868.72Mb/s, 5.73Gb/s )
13: 8192K: 2.316389e+008: 5.460606e-002s: 3000399.82Kb/s ( 2930.08Mb/s, 2.86Gb/s )
14: 16384K: 3.440554e+008: 8.110688e-002s: 3030075.91Kb/s ( 2959.06Mb/s, 2.89Gb/s )
15: 32768K: 4.967994e+008: 1.171144e-001s: 2797947.40Kb/s ( 2732.37Mb/s, 2.67Gb/s )
16: 65536K: 4.782120e+008: 1.127327e-001s: 2906699.36Kb/s ( 2838.57Mb/s, 2.77Gb/s )
1 - output completed
Мы можем выяснить размер кэш памяти глядя на скорость работы с блоками разной длины. Это возможно, потому что если блок полностью помещается в кэш данного уровня, то скорость работы с ним возрастает. Когда размер блока становится слишком большим, чтобы поместиться в этот кэш, он уже вытесняется в более медленный кэш или в память, что выглядит как снижение скорости работы с памятью.
Так, перепад 33.43Gb/s-17.97Gb/s на границе блока 4K для теста '0x01' показывает, что у меня не более 8К L1 кэша данных.
Для теста '0x01' реальный размер переданных данных в два раза выше чисел, которые указаны в таблице, поэтому для теста '0x01' вычисление размера переданных данных сводится к умножению на 2 этих значений. Умножать на два надо потому, что в тесте '0x01' реально передается в два раза больше данных, чем указанный размер блока.
CPUz рапортует о 16K L1 кэша данных на ядро, но в FX4xxx L1 кэш только для чтения, поэтому при операциях чтения+записи, как в тесте '0x01', этот read-only кэш действует как обычный L1 кэш, но меньшего размера. Более точные измерения с другими тестами '0x??' показывают, что он действует как обычный L1 кэш (пригодный для записи) размером 4К и как L1 кэш только для чтения размером 16К.
Далее, перепад 11.01Gb/s-6.04Gb/s на границе блока 1024K для теста '0x01' показывает, что у меня не более 2048K L2 кэша. CPUz согласен, что у меня 2048K L2 кэша на ядро.
Затем, перепад 5.73Gb/s-2.86Gb/s на границе блока 4096K для теста '0x01' показывает, что у меня не более 8192K L3 кэша. CPUz согласен, что у меня 8192K L3 кэша.
Помимо размеров кэша можно определить скорость работы каждого кэша и памяти. Понятно, что «скорость работы» это понятие не очень точное, поскольку она зависит от того, какая программа выполняется, для измерения скорости разных программ cctc имеет несколько тестов, самый простой из которых это '0x01'.
Для теста '0x01' реальная скорость передачи данных в два раза выше чисел, которые указаны в таблице, поэтому для теста '0x01' вычисление скорости сводится к умножению на 2 этих значений. Умножать на два надо потому, что в тесте '0x01' реально передается в два раза больше данных, чем размер блока, а эти числа показывают скорость передачи в одном направлении при одновременном двунаправленном обмене с памятью.
Вообще тест '0x01' показывает потоковую скорость передачи при традиционных операциях с памятью, т.е. когда процессор читает и пишет долгие непрерывные блоки данных простыми строковыми командами, с помощью которых программа не может явно учесть существование кэша, а предлагает процессору самому оптимизировать обращения к памяти. Именно такой режим позволяет выявить пиковую пропускную способность памяти и именно в таком режиме большинство нынешних программ работает с памятью, предлагая процессору размещать данные в кэшах самостоятельно.
Максимальное значение 2.89Gb/s для блоков больше чем размер всего кэша процессора на блоке 16384K показывает, что моя DDR3 память в двухканальном режиме работает со скоростью 5,78Gb/s.
Для справки, на тесте '0x01' в одноканальном режиме этот процессор показывают скорость 4,2Gb/s, а вот процессор i3 на LGA1156 в двухканальном режиме без всяких попыток разгона показывает скорость 9,2Gb/s, а в одноканальном режиме 4,4Gb/s.
Сравнение значений для i3 на LGA1156 говорит нам о том, что этот процессор на LGA1156 реализует преимущества «специальной архитектуры 2n Prefetch» в полной мере и без всяких сюрпризов, удваивая пропускную способность, что нельзя сказать о известных мне процессорах Athon для AM3 и FX для AM3+, первый из которых в двухканальном режиме действительно дает те самые популярные 5% прироста по сравнению с одноканальным режимом, а второй даже без разгона NB_CPU дает почти 50% прироста по сравнению с одноканальным режимом, хотя и уступает приросту по сравнению с одноканальным режимом для i3 на LGA1156 почти на столько же, на сколько сам опережает Athlon.
Таким образом, многие известные по тестам отставания Athon для AM3 от i3 на LGA1156 обусловлены тем, что Athon для AM3 не может использовать двухканальный режим DDR3 для роста скорости и не может использовать преимущества «специальной архитектуры 2n Prefetch».
Исторически, ситуация очень напоминает сравнение AMD-Am5x86-Pxx на шине i486 и Pentium-xx для socket7, когда более высокочастотный Am5x86 не мог догнать менее высокочастотный Pentium-xx на обычных программах из-за двухканальности шины Pentium по отношению к i486. Но если для Am5x86 проблемой была шина от socket3 для i486, то для AM3/AM3+ проблемой является сам процессор, контактов в AM3 достаточно для двухканальной работы памяти в виде «специальной архитектуры 2n Prefetch».
Посмотрим на скорости работы кэша. Мой L3 кэш дает 12Gb/s, что чуть выше, чем установленная DDR3 PC-10600, CL=9 должна бы дать в двухканальном режиме и примерно равна одноканальной DDR3 PC-12800; L2 кэш дает 26Gb/s, что примерно равно двухканальной DDR3 PC-12800; L1 кэш дает 67Gb/s, но cctc не может точно измерять столь малые интервалы времени и разные ошибки вычислений не дают нам возможности полагаться на абсолютные значения для L1, оценка примерная - явно быстрее чем L2.
Сравнение кэш памяти с DDR3 памятью проведено в смысле пиковой передачи, потому как в отличие от пакетной DDR3, кэш память это память имени Б. Гейтса, т.е это может быть настоящая RAM память (память с произвольным доступом), т.е. для нее скорость отдельных случайных операций чтения записи такая же высокая, как и скорость потоковых операций.
7. Потребительские перспективы.
Нарисуем структуру микросхемы памяти с нашей «специальной архитектурой 2n Prefetch». Нарисуем, потому что именно сегодня я ощущаю в себе большой художественный талант. И вдохновение.
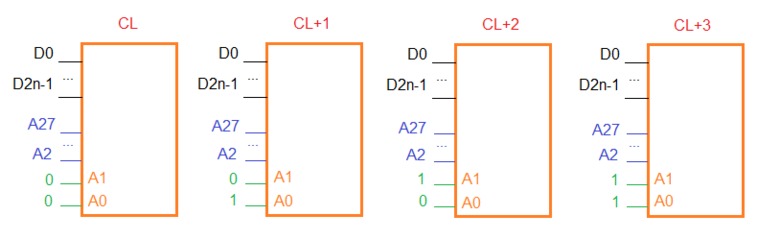
Вот, рисунок «2n_prefetch.png».
Это типовая структурная схема внутренней организации для DDR3 памяти с числом передач данных в пакете равным 8 (4 такта CLC). Каждый коричневый прямоугольник это блок памяти, который имеет удвоенную ширину данных (2n) по отношению к ширине DDRx памяти (n=64). Удвоение шины обслуживает ddr, т.е. позволяет передавать две порции данных за один такт CLC.
Всего здесь 4 блока, что необходимо для DDR3 с ее 8 передачами в пакете, для DDR с числом передач равным 4 (2 такта CLC), таких блоков надо только два. Адресные линии A0-A1 каждого блока фиксированы и в месте с линиями A2-A27 выбирают данные в пределах 4Гбайт.
Блоки помечены как CL, CL+1, CL+2, CL+3, потому как при обращении к пакету данных по нулевому адресу они выдают данные после CL числа тактов CLC с задержкой в 0,1,2,3 такта соответственно.
Интересно отметить, что если процессор будет выравнивать свои обращения по границе DDR3 блока (64 байта), то задержка в 0,1,2,3 такта сохранится всегда и такие блоки смогут иметь разный CL (для реальной DDR3 PC-10600 c CL=8 это будет 8,9,10,11), что может быть выгодно, потому что разный CL для блоков позволит уменьшить общий CL не повышая стоимость, например если вместо первого блока использовать дорогостоящий блок с CL=6 (25%объема), вместо второго чуть менее дорогостоящий с CL=7, вместо третьего обычный с CL=8, вместо четвертого самый дешевый с CL=9, при этом общий CL для памяти будет 6, при том что 75% компонентов менее скоростные.
Обсуждение этой заметки в форуме.
Создано: 04.11.12
Последний раз отредактировано: 04.11.12
Лента материалов
Правила размещения комментариев
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.