
О распределении тепла в процессорах и соответствующих тепловых потоках. Часть 3
В прошлой части я получил несколько вопросов, уточнений и претензий. Поэтому давайте сначала разберем это (не стал отвечать в прошлой заметке, т.к. она уже старая).
1) Камрад Anglesmith уточнил, что ALU в моём понимании это ALU+FPU + все исполнительные устройства. Спасибо. Почему-то всегда считал, что все исполнительные устройства это подвид АЛУ, но оказалось - это не так. (Вообще спасибо Anglesmith'у т.к. он ответил на кучу вопросов вместо меня и сэкономил моё время)
реклама
2) Далее, был поставлен под сомнение тезис о том, что основным источником тепла в кристалле процессора является блок исполнительных устройств x86, с указанием того, что вывод основан на статье 2004 года.
Ответ: та ссылка была приведена для примера, вот ссылка поновее (2018). Статья исключительно интересная. Для желающих TL;DR: Берётся APU A10-5700, с него снимается крышка, затем ставится водоблок на голый кристалл. Водоблок не простой - у него два сапфировых окна, а вместо воды минеральное масло - этакий "Маслоблок". При этом нижнее окно напрямую контактирует с кристаллом, масло течёт между двумя окнами. Преимущество данной схемы в её прозрачности в инфракрасном диапазоне - горячий кристалл испускает, в основном, ИК излучение. Затем инфракрасная камера измеряет температуру поверхности кристалла. Ниже приведен пример температурного поля на поверхности кристалла:
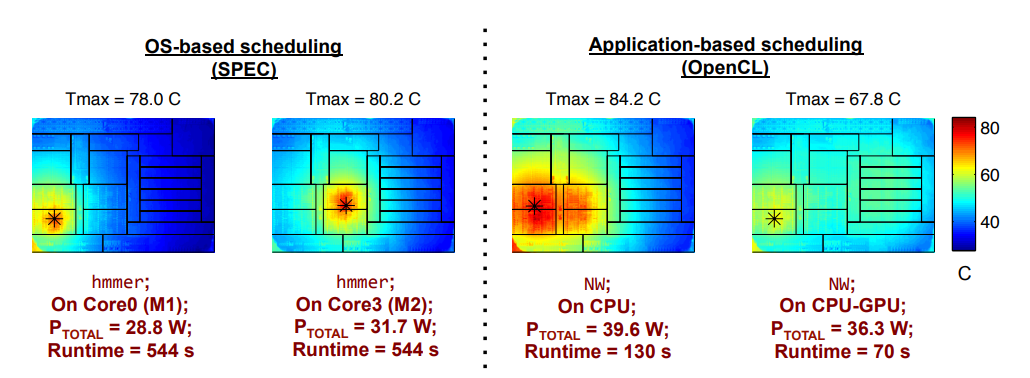
Левая половина - одноядерная нагрузка на x86 блоки, третий снимок – 4-х ядерная х86 нагрузка , последний снимок - гетерогенная CPU-GPU нагрузка. На третьем снимке можно заметить следствие планарного теплопереноса в область холодного кремния. Либо это следствие несимметричной нагрузки, что сомнительно.
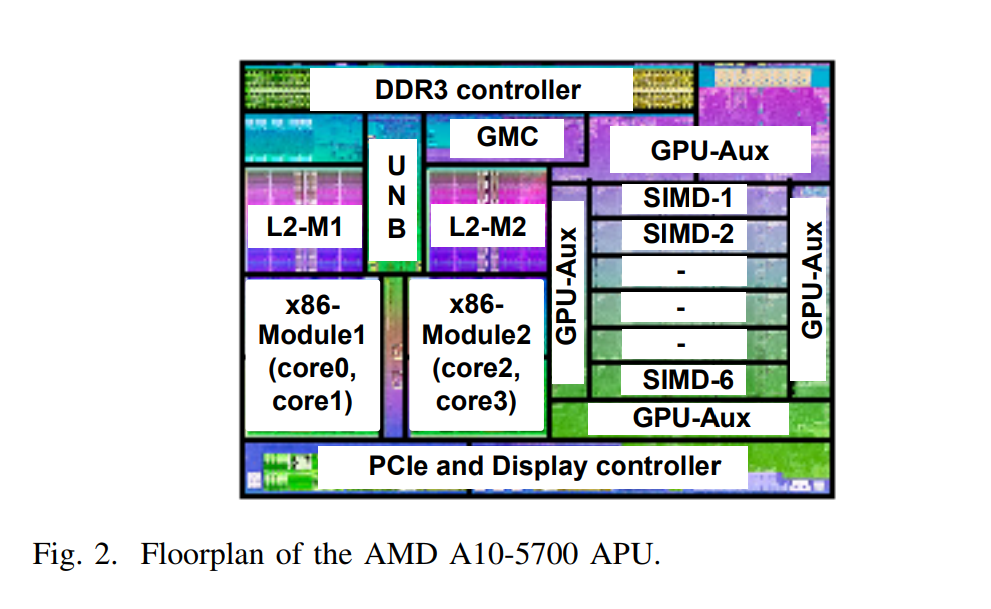
И топология кристалла:
реклама
Сравнивая снимки и схему видим, что основной нагрев происходит в малой области x86 ядра или же всего x86 блока.
Далее авторы решают обратную задачу теплопроводности - если в случае прямой задачи мы находим распределение температур по заданным источникам тепла, то при решении обратной задачи мы находим распределение источников тепла по заданной температуре. В результате они получают мощность, выделяемую каждым блоком APU. Например, в бенчмарке CFD (вычислительная гидродинамика, интенсивно задействует FPU/векторные блоки, высокий показатель заполнения SSE/AVX регистров), они получают следующее распределение мощностей и температур (нас интересует только правая половина):
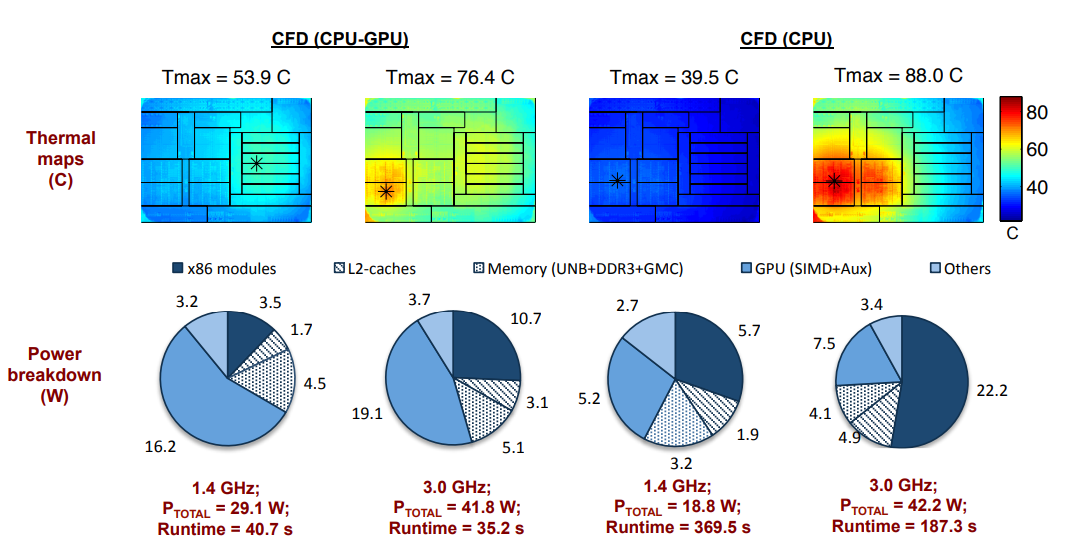
Как можно видеть на частоте 3 ГГц, x86 модули потребляют ~50% мощности CPU, L2 -кэши ~11.5%, графика - 17.8%, оставшаяся обвязка ~20%. Если рассматривать просто CPU часть, без GPU, то получим, что x86 потребляет (22.2/34.7) = 64%, L2 кэши - 14.1%, оставшаяся обвязка ~22%.
Слабость потребления x86, в данном случае, обусловлена разделяемым блоком FPU - он здесь один на два ядра.
Результаты на 1.4 ГГц более интересны - они позволяют нам оценить величину статического потребления - т.е. потребления, не зависящего от частоты, либо же слабо зависящего от неё и напряжения.
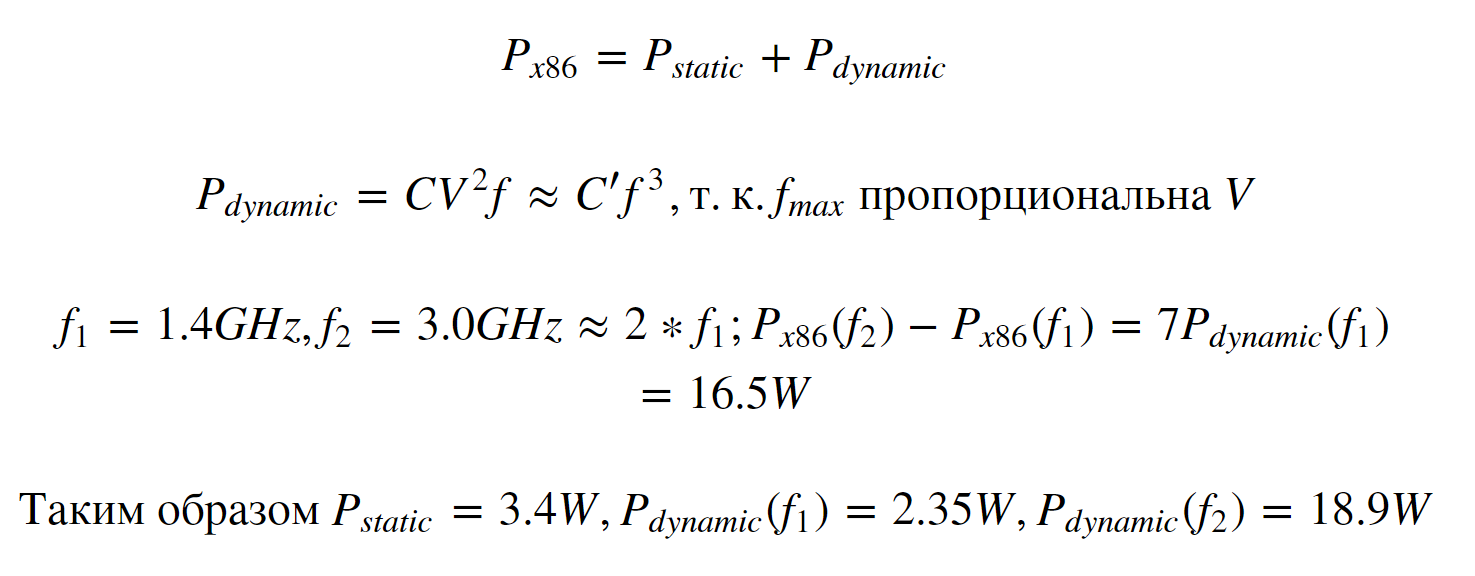
реклама
Из приведенного расчёта, а также сравнения приращения по другим компонентам, можно понять, что на более высоких частотах x86 будет потреблять существенно больший удельный процент мощности. Вообще, без доказательств, утверждается, что x86 потребляет 80 - 85% на частотах 4-4.2 GHz в случае наличия у каждого ядра своего FPU блока (без разгона контроллера памяти).
Вывод: можно утверждать, что горячими точками в кристалле процессора являются области исполнительных устройств (то, что я ранее называл ALU). Основная мощность выделяется там же. С учётом малой относительной площади исполнительных устройств наиболее критичные/высокие тепловые потоки также должны наблюдаться из этой области.
3) Тезис Furmanoff
Повторюсь, как я писал в первой статье, не самую последнюю роль в теплоотводе играет площадь контакта кристалла с подложкой через шарики припоя
Крайне сомнительно - для того чтобы создать приличный тепловой поток, нужен сток тепла, как радиатор кулера, например. У шариков припоя я банально не вижу такого хорошего стока. Может на начальных этапах нагрева, когда всё холодное, это сказывается, но после выхода на стационар ... вряд ли.
реклама
4) Anglesmith, о температуре поверхности крышки процессора:
А если при более реальных условиях посчитать? 50°C, например. Этому кулеру же тоже надо тепло отдавать, а при такой маленькой дельте температур окружающей среды и подошве кулера это непросто.
Дополню, что тепловые трубки, например, работают при температурах от 45-55°С
http://www.electrosad.ru/Ohlajd/Cooltt1.htm
Принято. Спасибо. Теперь поверхность крышки будет 50° С .
30° С скорее подходило для чиллера, что в преобладающем большинстве случаев недоступно.
5) Денис
Моё утверждение: Ещё кэши свою роль играют - в Haswell (произносится как Ха́суэлл) повысили их ПСП на ~100%, в итоге он стал обходить Ivy Bridge на ~30-40%.
Ваше утверждение: Это в мечтах маркетологов, даже Coffee Lake хорошо если на 15% обгонит Ivy Bridge.
А к какому применению относится Ваше утверждение? В данном случае, я просто прогнал две FEM задачи на процессорах i5-4690 и i5-3570. Собственно скорость между поколениями выросла на 30-40%. Было это в 2014 году ещё.
За произношение спасибо, буду знать.
6) Zystax, k2viper, coolio - о толщине меди в теплораспределителе:
Согласен, крышка толстовата - теперь она будет 1 мм. Спасибо.
7) coolio - про фетиши
Что за фетиш с поврежденным кремнием? Напыление электронных схем никак не может ему навредить. Пайка к крышке тоже, иначе бы от нее отказались все.
Вы с производством полупроводников работаете (ли)? Я без сарказма. У меня профиль не электроника, но одна из специализаций - это поведение материалов после воздействий, различных.
Кремний повреждается после нарезки пластин - эти дефекты частично убираются отжигом и травлением. Затем он "травмируется" из-за воздействия излучения и термических градиентов, на малых масштабах. Довершает картину диффузия металлов и остатков фоторезиста, и прочего технологического добра, при (внимание!) отжиге, цель которого избавление от нетермических дефектов. В области где-то 50 микрон под слоями металлизации теплопроводность может падать до 50-70 Вт/м-К. Для того, чтобы учесть этот эффект, я понижаю теплопроводность кремния (всего кремния) до 120 Вт/м-К. Бесспорно, техпроцесс Intel и прочих разрабатывается так, чтобы минимизировать эти эффекты, но полностью сгладить их проблематично, особенно при массовом производстве.
Такой сильный эффект дефектов проявляется для материалов с высокой теплопроводностью - у них большую роль играют "длинные" фононы, которые, собака, чувствительны к малым дефектам в решетке.
8) _tonis
А что за FEM у вас, если не секрет? Comsol? И какой версии?
Вообще было бы интересно посмотреть на сравнение AMD Ryzen с Intel Core в этом классе задач. Ведь, судя по всему, у вас есть доступ к обоим типам систем. Со своей стороны могу потестировать на свежеприобретённом i9-9900k, старичке i7-3820 и, прости господи, 8-ядерной печке FX.
Да, таки Comsol, он самый. Версия 5.4. Но я его не использую, просто для заметки потребовался. Часть времени использую FEM-коды, написанные коллегами. Часть времени, это не-FEM.
Касательно сравнения: Вы меня немного в лужу посадили - мы взяли код оптимизированный под Skylake (FEM, поведение золотых микрошариков при воздействии электромагнитной волны - порядка сотни тысяч элементов, сетка неоднородная, частично адаптивная. Потребление памяти в пике ~11 GB. Оптимизировано под 16 потоков. Если потоков больше, то код сам садится на физические ядра). Тестовые системы:
A - Core i7-5930K, RAM DDR4 - 2400, 4 канала, 32 GB.
B - Core i7-5960X, RAM DDR4 - 2400, 4 канала, 32 GB.
C - R7 2700X, RAM DDR4 - 3200, 2 канала, 16 GB.
D - TR - 1920X, RAM DDR4 - 2933, 4 канала, 32 GB.
E - TR - 1950X, RAM DDR4 - 2933, 4 канала, 32 GB.
Все системы в стоке, только оперативка разогнана. Ничего не твикается, как есть.
Время выполнения:
A ~ 69 min; AVX off - 80 min;
B ~ 69 min; AVX off - 74 min;
C ~ 80 min; AVX off - 83 min;
D ~ 41 min; AVX off - 39 min;
E ~ 37 min; AVX off - 34 min.
Странность в том, что 6 vs 8 ядер - нет разницы. Ryzen ускоряется от AVX (LOL). 16 ядер замедляются от AVX. Однозначной интерпретации я дать не могу. Непонятно.
Но, вообще, говорят "Ryzen is like Intel, but Ryzen" - Райзен - это такой Интел, только Райзен.
Теперь перерасчет модели:
Описание модели
Общее тепловыделение - 200 Ватт. 40 Вт на обвязку, 160 Ватт на ядра. 8 ядер.
Тепловыделение 20 Ватт на область исполнительных устройств площадью 5.4 кв. мм (одно ядро). -->Тепловой поток = 3.7 МегаВатт на метр квадратный. Источник тепла в силу своей пренебрежимо малой толщины моделируется просто как тепловой поток.
Область окружена мертвым кремнием площадью 120 кв. мм и толщиной 450 микрон (0,45 мм).
Термоинтерфейс - индиевый припой (80 Вт/м-К), толщиной 1 мм. Толщина медной крышки 1 мм (385 Вт/м-К). Боковые грани термоизолированы (тепловой поток равен нулю). Верхняя грань - крышка процессора контактирует с подошвой кулера, используя обычный кулер, зафиксирована температура 50° С. Термосопротивлением интерфейса между припоем и крышкой, а также между кристаллом и припоем пренебрегаем - идеальный термический контакт.
Модель осесимметричная и стационарная - мы не заинтересованы в переходных процессах.
1) Расчёт для указанных параметров. (Максимальная температура приядерной области 358 К = 85° C)
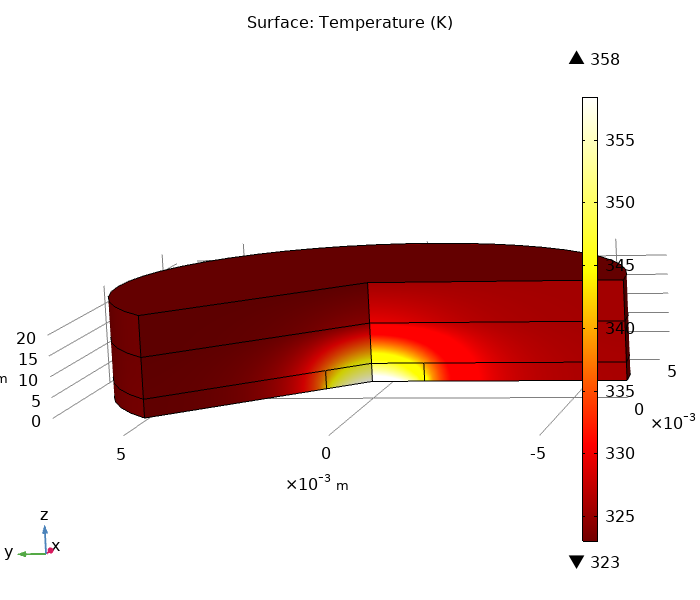
Теперь температура на поверхности кристалла

Черная линия - это граница "ядра".
И тепловой поток, исходящий через поверхность кристалла (на границе с припоем).
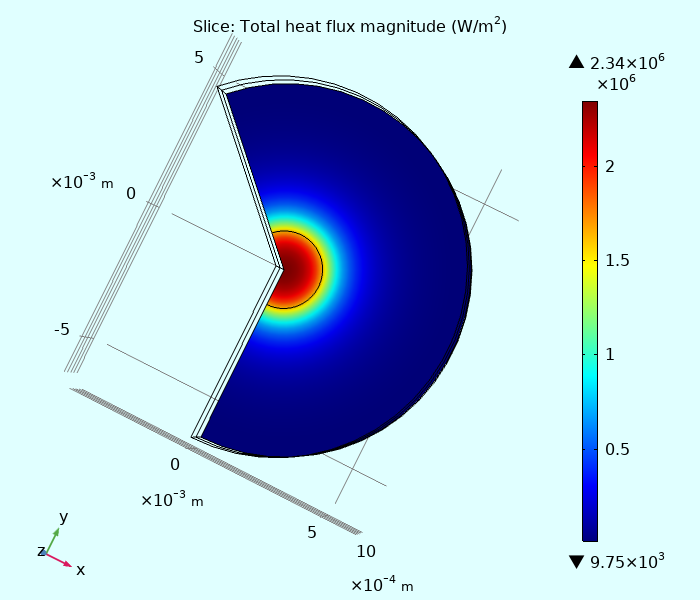
Поток в Ватт/м2.
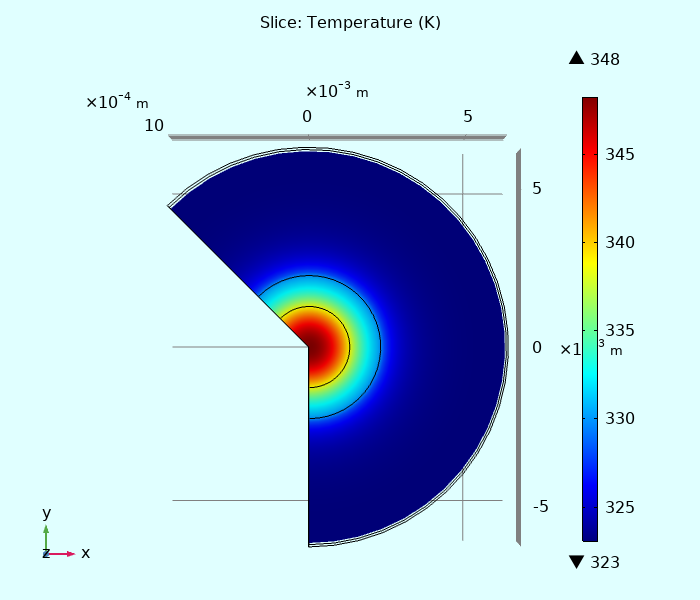
2) Теперь сократим область до 16 кв. мм (5.4 "ядро" + 10 кв. мм "мертвый кремний")

Температура на поверхности.
И тепловой поток на поверхности кристалла.
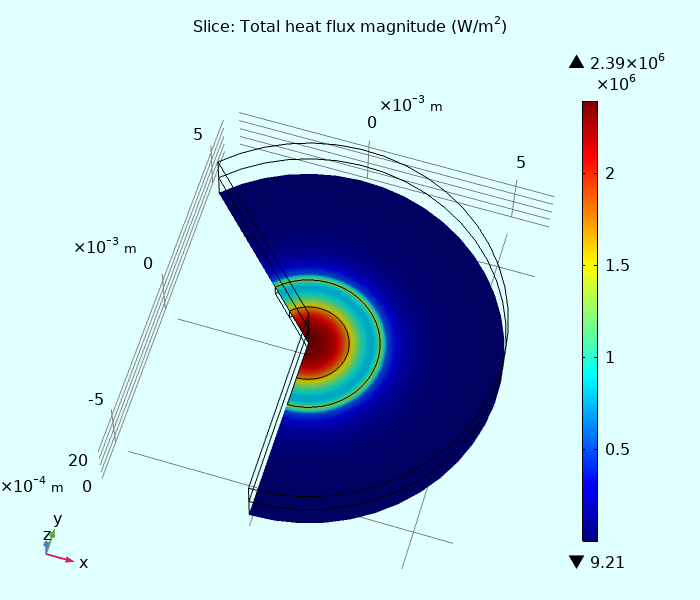
Обратите внимание - на краю кристалла тепловой поток возрастает, а не падает - происходит "отражение" радиального (планарного) теплового потока от теплоизолированной стенки.
Краткий вывод: "широкое" x86 ядро на 14 нм техпроцессе требует порядка 10 мм2 кристалла для эффективного теплоотвода. Что для 8 ядер даёт 80 мм2 - больше не требуется. (При условии использования припоя).
P.S. В предыдущей части был обещан анализ неоднородности температур ядер в процессоре и спекуляции на тему AVX. Но я решил дать ответы на накопившиеся вопросы и улучшить модель. Обещанное будет в части 4.
Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.