
Микроархитектура процессоров AMD следующего поколения: от K8 к K8L
K8L изначально проектируется как четырёхъядерный чип. Все четыре ядра будут находиться на одной кремниевой пластине, подключенные к общему кэшу третьего уровня, а также общим коммутатору и контроллеру памяти.
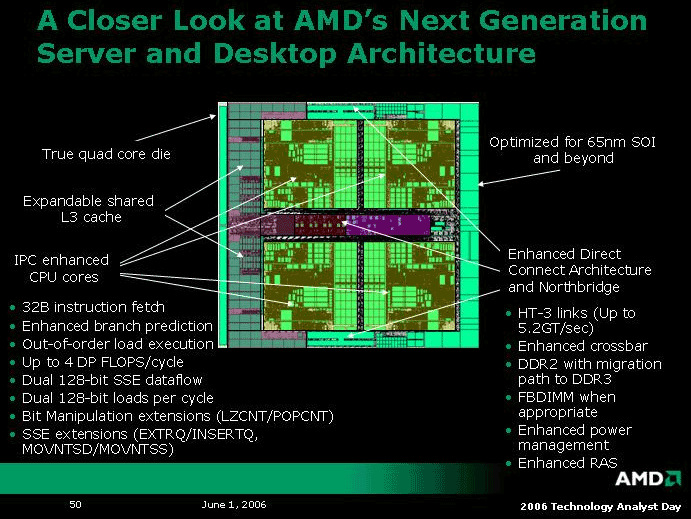
В данной статье мы попытаемся проанализировать известные и ожидаемые микроархитектурные улучшения будущего процессора, сравнить его с микроархитектурой Conroe и оценить его возможные слабые и сильные стороны, а также перспективы.
Выборка инструкций
Процессор K8 каждый такт производит выборку инструкций из кэша команд L1I выровненными 16-байтными блоками в буфер, где происходит выделение инструкций из блоков и их отсылка в каналы декодера. Темп выборки, составляющий 16 байтов за такт, позволяет отправлять на декодирование в каждом такте по 3 инструкции средней длиной до 5-ти байтов. Однако в некоторых алгоритмах средняя длина инструкций в цепочке может превышать 5 байтов.
В частности, длина SSE2 – простой инструкции с операндами типа регистр-регистр (например, MOVAPD XMM0, XMM1) составляет 4 байта. При применении в команде косвенных схем адресации с использованием регистра базы и смещения (например, MOVAPD XMM0, [EAX+16]) длина команды увеличивается до 6-8 байтов. В 64-битном режиме при использовании дополнительных регистров к коду команды добавляется ещё один однобайтный REX-префикс. Таким образом, в 64-битном режиме длина SSE2-команд может достигать 7-9 байтов. Длина SSE1-команды, если это команда векторная (то есть над четырьмя 32 битными значениями), на 1 байт меньше, но скалярные (над одним операндом) SSE1-команды также могут достигать длины в 7-9 байтов при тех же условиях.
В этой ситуации темп выборки в 16 байтов за такт уже не кажется достаточным для поддержания скорости декодирования команд по 3 за такт. Для процессора K8 это ограничение не является существенным, потому что скорость декодирования векторных SSE и SSE2-команд производится в темпе 3 команды за 2 такта (1.5 команды за такт), что является достаточным для загрузки двух 64-битных FPU-блоков. Однако в будущем процессоре необходимо поддерживать темп как минимум в 3 команды за такт. C этой точки зрения, выборка инструкций блоками по 32 байта, анонсированная в презентации архитектурных новшеств K8L, уже не кажется избыточной. Выборка 32-байтными блоками позволяет за один такт прочитать из кэша до 4-х восьмибайтных команд

На рис.2 показан пример расположение пяти длинных команд в 32-байтном блоке, которые могут быть выбраны за 1 такт. Если последовательность таких длинных команд занимает несколько смежных 16-байтных блоков, то в случае выборки команд 16-байтными блоками средний темп выборки в 3 команды за такт не достигается.
Кстати говоря, процессоры Conroe выбирают инструкции блоками по 16 байтов, как и процессоры K8, поэтому они могут эффективно декодировать поток команд в темпе по 4 за такт лишь в том случае, когда средняя длина инструкции не превышает 4-х байтов, в противном случае декодер не сможет эффективно обрабатывать не только 4, но и 3 инструкции за такт. Однако для борьбы с этим недостатком в коротких циклах в Conroe применяется специальный внутренний 64-байтный буфер, кэширующий циклы размером до 64 байт (четыре 16-байтных блока) и позволяющий в таких циклах проводить выборку с темпом 32 байта за такт. Если цикл не помещается целиком в 4 блока, то он не может быть кэширован в этом буфере.
реклама
Выборка очередного блока инструкций при наличии команд условного перехода производится с использованием механизма предсказания переходов. Предсказание переходов в процессоре K8 происходит по более простым алгоритмам, чем те, которые реализованы в Conroe. Например, процессор K8 не умеет предсказывать чередующиеся косвенные переходы, что может, например, снижать эффективность исполнения объектно-ориентированных полиморфных кодов, а также не всегда чётко предсказывает регулярные последовательности. В процессоре K8L механизм предсказания переходов будет усовершенствован, но детальной информации об улучшениях, к сожалению, пока нет. Среди возможных улучшений предсказателя могут быть увеличение размеров таблиц переходов, счётчиков и усовершенствование механизма предсказания переходов, чередующихся по регулярным последовательностям.
Декодирование
Выделенные из блока байтов x86-инструкции декодируются в макрооперации (МОПы, macro-ops в терминологии AMD). МОПы состоят из пары микроопераций (micro-ops): целочисленной или вещественной арифметики и адресной операции обращения к памяти. Расщепление на микрооперации производится планировщиком при отправке на исполнение. C точки зрения декодеров процессора K8, существует три разновидности инструкций:
- простые одиночные инструкции (DirectPath Single) декодируются в 1 МОП в аппаратном декодере;
- простые двойные инструкции (DirectPath Double) декодируются в 2 МОПа в аппаратном декодере;
- сложные инструкции (VectorPath) декодируются в 3 (или более) МОПа в микропрограммном декодере.
Простые и сложные инструкции в процессоре K8 не могут быть отправлены на декодирование одновременно. Декодеры выдают результаты декодирования с темпом 3 МОПа за такт. Таким образом, аппаратным декодером за 1 такт может быть декодировано 3 простых одиночных инструкции, 1 двойная и одна одиночная инструкция, 1.5 двойных инструкции (3 двойных инструкции за два такта). Так как одна сложная инструкция может декодироваться в более чем 3 МОПа, декодирование таких инструкций может продолжаться в течение более чем 1 такта.
Выходящие каждый такт из декодера МОПы объединяются в группы. Из-за чередования DirectPath и VectorPath команд или различных задержек в выборке инструкции для декодирования на выходе декодера может сформироваться группа, содержащая 2 или даже 1 МОП. Такая группа заполняется до трёх пустыми МОПами и в таком виде отправляется на исполнение.
Векторные SSE, SSE2 и SSE3-команды в процессоре K8 разбиваются на пары МОПов, раздельно обрабатывающие верхнюю и нижнюю 64-битные половины 128-разрядного SSE-регистра на 64-битных устройствах. Поэтому темп декодирования таких команд в K8 не превышает 3 за 2 такта. Так как ширина SSE-устройств в будущем процессоре K8L будет расширена до 128 бит, необходимость дробления векторных команд на две части отпадёт, и, очевидно, схема декодирования таких команд будет изменена таким образом, чтобы декодировать векторные команды в одиночные 128-битные МОПы с полным темпом 3 за такт.
Несмотря на то, что декодер K8L не сможет декодировать по 4-5 команд за такт, как это может делать декодер Conroe в благоприятных условиях, он не станет ограничивающим фактором при исполнении программ, так как средний темп исполнения команд всё равно обычно меньше 3-х. В среднем К8L будет декодировать одну x86-инструкцию в меньшее количество МОПов, чем процессор Conroe, что вместе с 32-байтной выборкой делает его декодер достаточно эффективным.
Исполнение целочисленных команд
Декодированные тройки МОПов поступают в блок управления командами (instruction control unit – ICU), который заносит информацию о МОПах в буфер переупорядочивания (reorder buffer – ROB), а затем передаются в планировщики. Буфер переупорядочивания отслеживает состояние МОПов и контролирует порядок их отставки. МОПы поступают в очереди и отправляются в отставку группами по три (линиями) в том виде, в котором они вошли в ICU, однако поступают в планировщики и отправляются на исполнение независимо.
МОПы из каждой группы распределяются в три независимые очереди планировщика размером по 8 элементов каждая (всего 24 МОПа), привязанные к трём симметричным целочисленным каналам. Номер очереди соответствует положению МОПа в группе в том виде, в котором группа была сформирована на выходе из декодера. По мере готовности данных планировщик может запускать на исполнение из каждой очереди одну целочисленную операцию в устройство ALU и одну адресную операцию в устройство AGU. Количество одновременных обращений к памяти ограничено двумя. Таким образом, за каждый такт может запускаться на исполнение 3 целочисленных операции и две операции с памятью (64-битного чтения / записи в любой комбинации). Целочисленные операции отправляются на исполнение из очередей во внеочередном порядке по мере готовности данных для них. Однако операции загрузки из памяти выбираются в программном порядке. Например:
реклама
add ebx, ecx
mov eax, [ebx+10h] – быстрое вычисление адреса
mov ecx, [eax+ebx] – адрес зависит от результата предыдущей команды
mov edx, [ebx+24h] – эта команда не будет запущена до тех пор, пока не будут вычислены адреса всех предыдущих команд.
Это является одним из ограничивающих факторов в процессоре K8, из-за которого на некоторых кодах процессор K8, несмотря на возможность запуска двух команд чтения за такт, может обращаться с памятью менее эффективно, чем процессор Conroe, запускающий одну команду чтения за такт, но при этом обладающий механизмом спекулятивного внеочередного исполнения команд чтения в обход предшествующих команд чтения и записи. К счастью, в процессоре K8L появится механизм внеочередного запуска команд загрузки, и это узкое место будет ликвидировано. Подробной информации о деталях реализации данного механизма пока нет, однако, скорее всего, переупорядочивание команд чтения не затронет команд записи, что может стать причиной несколько менее эффективного исполнения некоторых кодов.
Группа из трёх МОПов удаляется из ROB после того, как все операции из этой группы будут выполнены. Постановка МОПов в очереди и удаление их группами существенно упрощает управление ресурсами и позволяет более эффективно нагружать планировщики при том же количестве ресурсов. В случае полного заполнения одной из трёх очередей в планировщик не могут поступать новые тройки МОПов, и в других очередях могут образовываться свободные слоты. Однако на практике пустые слоты не составляют большого процента от занятых, поэтому ухудшения эффективности из-за них не наблюдается.
Кроме того, теоретически возможно небольшое снижение эффективности планировщика вследствие статической привязки позиции МОПа в группе к очереди планировщика из-за того, что в одной очереди может быть две или более микрооперации, готовые к исполнению, а в другой не быть ни одной (рис. 3). Однако на практике оно маловероятно и, как правило, не наблюдается, так как обычно на конвейере вполне достаточно команд, ожидающих исполнения.

В процессоре Conroe, в отличие от K8, используется общая очередь для всех команд (в том числе вещественных) длиной 32 МОПа. Общая очередь теоретически позволяет избежать появления пустующих позиций и возможных ограничений вследствие статической привязки к устройствам. Кроме того, благодаря механизму stack engine в Conroe уменьшено количество зависимостей по данным между командами PUSH, POP, CALL и RET. Однако на практике полностью ассоциативную очередь, из которой можно одновременно запускать на исполнение 5 микроопераций, организовать чрезвычайно сложно, поэтому общая очередь всё равно разбивается на секции. Это приводит к обратному эффекту: из-за недостаточно упорядоченного выбора команд для исполнения появляется проблема процессоров семейств P6+, известная как "хаотическое планирование" и снижающая эффективность исполнения. Кроме того, Conroe имеет ограничение на количество регистров, которые могут одновременно быть считаны из ROB (не более трёх), что накладывает ограничение на планирование потока команд.
В целом реализации механизма внеочередного исполнения команд у K8L и Conroe незначительно отличаются по эффективности, так как оба процессора могут запускать на исполнение по 5 микроопераций за такт (3 ALU + 2 Mem). Особенности реализации механизмов планирования и запуска могут по-разному проявляться в зависимости от кода, сгенерированного компилятором.
Исполнение вещественных команд
В процессоре K8 планировщик вещественных команд отделён от планировщика целочисленных команд и устроен несколько иначе. Буфер планировщика вмещает до 12 групп по три МОПа (36 вещественных операций теоретически). Кроме того, применяется механизм уплотнения очередей, позволяющий из двух частично заполненных троек получить одну полностью заполненную и одну пустую. В отличие от блока исполнения целочисленных команд с симметричными вычислительными каналами блок плавающей арифметики содержит три различных устройства FADD, FMUL и FMISC (он же FSTORE) для вещественного сложения, умножения и вспомогательных операций, поэтому в буфере планировщика нет привязки положения МОПа в группе команд к конкретному вычислительному устройству (рис. 4).

Каждый такт в каждом из устройств вещественной арифметики в K8 может запускаться на исполнение по одной операции. Устройства являются 80-битными. 128-битные SSE-команды разбиваются на этапе декодирования на два 64-битных МОПа, которые запускаются на исполнение последовательно в разных тактах. Несмотря на то, что теоретически за каждый такт может запускаться на исполнение до трёх МОПов, на практике такой темп недостижим из-за ограничения декодирования, поскольку кроме вещественных команд в коде также присутствуют вспомогательные команды загрузок, организации циклов и т.п. Кроме того, из-за простого алгоритма планирования операции не всегда распределяются по свободным устройствам в оптимальном порядке, что может снижать темп запуска из-за неполной загрузки устройств.
Благодаря двум 64-битным шинам чтения процессор K8 может получать из кэша первого уровня до двух 64-битных операндов за такт, что позволяет процессору поддерживать высокий темп исполнения при частом обращении вещественных команд к данным в памяти. Это очень важная особенность архитектуры, так как для параллельного выполнения двух команд нужно 4 операнда (по 2 на команду), а в ряде алгоритмов поточной обработки данных два из четырёх операндов, как правило, считываются из оперативной памяти.
В процессоре K8L устройства FADD и FMUL расширятся до 128 бит (рис. 5), что позволит удвоить теоретическую производительность вычисления с плавающей точкой в кодах с применением векторных SSE-команд не только за счёт удвоения темпа запуска команд, но и за счёт увеличения темпа декодирования и отставки вследствие уменьшения числа генерируемых МОПов.

Шины чтения данных из кэша также станут вдвое шире, что позволит процессору выполнять две 128-битные загрузки данных из кэша первого уровня за такт. Возможность выполнять два 128-битных чтения данных за такт в ряде алгоритмов даёт K8L потенциальное преимущество над процессором с ядром Conroe, которое каждый такт может выполнять только одну 128-битную загрузку из памяти.
А вот устройство FMISC (FSTORE), согласно представленной информации, останется по-прежнему 64-битным. Однако это нелогично, потому как в процессоре K8 операции записи 128-битных SSE-регистров в память запускаются через блок FMISC (FSTORE), и если этот блок не расширять, он автоматически станет узким местом в поточных вычислениях из-за невозможности выполнять 128-битное сохранение данных каждый такт. Поэтому есть мнение, что в презентацию AMD на самом деле вкралась ошибка, и блок FMISC (FSTORE) всё же будет выполнять операции сохранения в полном темпе: 128 бит за такт. Или же функция сохранения 128-битных данных будет реализована в двух других блоках, а блок вспомогательных операций останется работать в половинном темпе, что уже не так критично для производительности. Кроме того, доработки требует алгоритм планирования, не всегда работающий в K8 оптимальным образом.
Как уже говорилось выше, в Conroe, в отличие от К8, используется общая очередь для целочисленных и вещественных команд со всеми её достоинствами и недостатками. Кроме того, порты запуска целочисленных и вещественных команд совмещены, что не позволяет одновременно запускать на исполнение целочисленные и вещественные команды в некоторых комбинациях. Ещё одним ограничением Conroe, которое может проявляться в вещественных алгоритмах, использующих x87 команды (т.е. без применения SSE оптимизаций), является в два раза более низкий темп запуска команды умножения FMUL.
Кроме расширения вещественных устройств в K8L будут расширены расположенные внутри блоков FADD и FMUL целочисленные устройства, занимающиеся выполнением команд SSE2, что приведёт к ускорению целочисленных приложений, использующих этот набор команд. Также K8L научится исполнять несколько дополнительных SSE-команд, на которых не будем останавливаться в этой статье.
В целом блок исполнения команд вещественной арифметики в K8L обещает быть весьма эффективным, по некоторым параметрам (например, возможности двух 128-битных чтений за такт) более эффективным, чем блок Conroe.
Подсистема памяти
Кэш первого уровня у K8 раздельный – по 64 КБ для команд и для данных. Ассоциативность кэшей равна двум, размер линии – 64 байта. Такая малая ассоциативность объясняется, скорее всего, возможностью производить ядром два чтения из кэша за такт. Малая ассоциативность компенсируется достаточно большим объёмом в 64 КБ: в неудобных алгоритмах эффективный объём кэша будет близок по эффективности кэшу размером 32 КБ с ассоциативностью, равной 4. Зато в алгоритмах с последовательным доступом кэш первого уровня большого объёма с возможностью двух чтений за такт выглядит предпочтительнее.
Кэш второго уровня (в паре с кэшем L1) имеет эксклюзивную организацию хранения данных: данные в кэше первого и второго уровня не дублируются. Кэши первого и второго уровней обмениваются данными по двум однонаправленным шинам (одна из L1 в L2, вторая из L2 в L1), шириной 64 бита (8 байтов) каждая (рис. 6). Из-за такой организации процессор получает данные, запрошенные в L2, с невысоким темпом 8 байтов за такт (8 тактов на передачу 64-байтной строки), что существенно увеличивает задержку получения данных ядром, особенно при одновременно доступе к двум или более строкам кэша второго уровня. Задержки несколько компенсируются увеличением количества кэш-попаданий вследствие увеличения суммарного объёма кэша за счёт эксклюзивности, а также высокой ассоциативности кэша второго уровня, равной 16.

реклама
На одной кремниевой подложке с ядром процессора расположен контроллер памяти. Данные из контроллера памяти через коммутатор направляются непосредственно в кэш первого уровня L1, минуя L2, что уменьшает задержку получения данных из оперативной памяти. В кэш второго уровня L2 попадают только данные, вытесненные из L1.
В процессоре K8L, как уже было сказано выше, кэш L1 сможет обеспечивать до двух 128-битных чтений или одно чтение и одну запись за такт. К сожалению, никаких данных об изменении ширины или организации шины между кэшами первого и второго уровня нет. Будем всё же надеяться, что эта шина тоже, как минимум, будет расширена вдвое. В противном случае медленная шина между кэшами будет ограничивать производительность процессора в кодах с поточными вещественными операциями, и мощные вычислительные ресурсы процессора будут просто простаивать в ожидании данных, считываемых из L2 с недостаточным темпом. Так же не будет увеличена ассоциативность кэша первого уровня. В таких условиях никаких чудес производительности от нового процессора нам ждать не придётся.
В процессоре K8L появится общий для 4-х (или менее) ядер на подложке кэш третьего уровня размером 2 или более мегабайт. Кэш третьего уровня, судя по всему, так же, как и кэш второго уровня, будет эксклюзивным. Вместе с улучшенным коммутатором (enhanced crossbar) кэш третьего уровня поможет снять проблему невысокой скорости обмена изменёнными данными между кэшами соседних ядер, который у K8 производится с использованием шины памяти. Эта проблема в значительной мере снята в процессорах с ядром Conroe благодаря общему для двух ядер кэшу второго уровня. Таким образом, четырёхъядерный процессор K8L, скорее всего, будет по своим характеристикам обмена данных между ядрами ближе к ядру Conroe.
Что интересно, согласно имеющейся на сегодняшний день информации, будущий четырёхъядерный процессор Intel не будет обладать общим для 4-х ядер кэшем. Таким образом, у него могут появиться те же проблемы скорости обмена данными для поддержания когерентности кэшей, которые наблюдаются сейчас у двухъядерных процессоров без общего кэшаПроцессоры с ядром Conroe обладают очень развитой системой кэширования: кэш первого уровня размером 32 КБ и ассоциативностью равной 8 и кэш второго уровня размером 2-4 МБ с ассоциативностью равной 16 соединены полноскоростной шиной шириной 256 бит. Процессор обладает высокоэффективными блоками предвыборки, которые могут агрессивно загружать данные не только из оперативной памяти, но и из кэша второго уровня в кэш первого уровня. Именно расширением системы кэширования в Conroe по большей части могут быть объяснены резко выросшие в SPEC INT результаты (до 40% в некоторых подтестах) по сравнению с предыдущим ядром Yonah.
Cудя по всему, в процессоре K8L не появится ни предвыборка данных в кэш первого уровня L1 из кэша второго уровня, ни высокоэффективные блоки предвыборки. Если перечисленные недостатки подсистемы кэширования ядра K8 не будут устранены в K8L, то они не дадут раскрыть его потенциал и сделают его менее эффективным по сравнению с Conroe.
Кроме вышеперечисленного, в подсистему памяти K8L будут внесены некоторые другие модернизации, такие как поддержка в перспективе памяти DDR3 и FBDIMM и поддержка HyperTransport 3. Но эти технологии вряд ли окажут качественное влияние на производительность в настольных компьютерах.
Выводы
Будущий процессор AMD, известный на сегодняшний день как K8L, будет следующей ступенью эволюции в развитии линейки K8. Известные на сегодняшний день улучшения (расширение выборки команд до 32 байт, усовершенствование механизма предсказания переходов, введение внеочередного запуска команд чтения) помогут ликвидировать несколько узких мест и улучшить производительность в целочисленных приложениях. Расширение SSE-блоков поможет значительно увеличить производительность в ряде приложений с интенсивными вещественными или целочисленными вычислениями, использующими набор команд SSE, где K8L сможет составить достойную конкуренцию и даже превосходить Conroe. Отсутствие декодирования и отставки 4-х команд за такт в ряде случаев может вносить свой вклад в разрыв по производительности в целочисленных приложениях, но в целом, поскольку типичный темп исполнения инструкций в реальных целочисленных приложениях из-за зависимостей по данным не превышает 2-2.5 инструкции за такт, не будет иметь решающего значения в большинстве случаев.
Существуют и другие возможности повышения производительности K8L, которые могли бы улучшить его эффективность без увеличения числа каналов декодирования и отставки. Это увеличение глубины очередей планировщика, уменьшение количества ложных зависимостей по данным (например, за счёт применения механизма, аналогичного stack engine) и внеочередное чтение в обход записи. На сегодняшний день неизвестно, сможет ли AMD реализовать эти возможности в новом процессоре. Так же пока неизвестно, будут ли внесены изменения в подсистему кэширования и предвыборки. От этого во многом зависит, сможет ли K8L успешно конкурировать с Conroe во всём спектре приложений.
Наследникам архитектуры K8 требуется более серьёзная доработка. Для того чтобы не просто бороться на равных с компанией Intel, а превосходить её процессоры по производительности, необходимо разработать архитектуру – наследницу K8, лишённую её ограничений и способную декодировать и исполнять до четырёх команд за такт. Увы, разработка и отладка нового ядра – задача чрезвычайно трудоёмкая и требующая большого количества времени. Поэтому, даже если уже сегодня в недрах AMD ведётся работа над новой архитектурой, в ближайшие пару лет она вряд ли сможет выйти на рынок. А что будет через пару лет в этой быстро развивающейся отрасли промышленности, – предсказать сложно.
Автор выражает благодарность:
- Керученько Яну aka C@t – за конструктивную критику и помощь теоретическом анализе.
- Загурскому Сергею aka McZag и Романову Сергею aka GReY – за конструктивную критику, ценные подсказки и предложения.
- Десятниковой Марии – за помощь в подготовке статьи.
Лента материалов раздела
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.