Вместо вступления.
HDD, он же Hard Disk Drive, он же НЖМД – Накопитель на жестких дисках. Не находите, довольно странно обнаружить в названии устройства указание на твердость используемых дисков? Дело в том, что первоначальный диск был мягким, FDD, Floppy Disk Drive, что требовалось для съемного носителя (дискеты). Прошло совсем немного времени и стала чувствоваться нехватка не только емкости, но и производительности FDD. Этапы развития технологий HDD пропустим, важнее здесь другое – диски пришлось сделать жесткими для повышения качества поверхности и плотности магнитной поверхности. Вот отсюда и появилось ”hard” в названии дискового накопителя.
Между форматами работы FDD и HDD, особенно ранних версий ATA, общего было больше, чем различий, но в современную эпоху встретить FDD довольно проблематично. Возникает вопрос о смысле использования в классификации явно устаревшего разделения на твердость диска. Довольно часто в качестве русской альтернативы HDD используют определение 'жесткий диск'. Вам не смешно? В статье будет использоваться термин ”HDD” для отождествления данного типа накопительных устройств.
SSD, Solid-State Drive, Твердотельный накопитель. Довольно странно, скорее уж 'монолитный' накопитель, хотя правильнее его называть ”Накопитель без движущихся частей”. Опять какая-то ерунда с логикой, далее будет использоваться общеупотребимое ”SSD” без вникания в смысл акронима.
MCP, Multi-Chip-Package – размещение нескольких микросхем в одном корпусе.
LUN – в терминологии ONFI это минимальный полностью независимый исполнительный элемент в микросхемах NAND, может состоять из двух плоскостей. Подробнее этот и последующие определения будут описаны в разделе технологий NAND.
Plane, плоскость – аналогично LUN, но с массой ограничений в применении. Входит в состав LUN.
Die – электронная схема, кристалл. По отношению к NAND почти всегда понимается (если нет очередной путаницы) аналогом термина ”LUN”. Пожалуйста, запомните это! Иначе всё запутается окончательно. Die = LUN. В тексте будет использоваться термин ”LUN” во всех случаях, когда им можно заменить ”Die” – так меньше путаницы в понятиях.
Target – элемент MCP с отдельным сигналом выборки CE. При обращениях к конкретному устройству надо как-то отождествить его на общей шине данных, для чего используются сигналы CE (Chip Enable, микросхема выбрана). Внутри одного target может быть несколько микросхем с разделением по адресам. Это означает, что в составе одного target может быть несколько Die (читай - LUN).
Описания на формат данных современных HDD отсутствуют, поэтому пойдем от FDD и ранних версий ATA. Некоторое представление можно получить на странице сайта remont-kompa.ru.
Формат записи определяет наличие маркера начала трека и зонной структуры секторов.
При некотором упрощении, формат сектора состоит из следующих элементов:
| 1. | зона синхронизации |
| 2. | адресный маркер |
| 3. | спецификация положения сектора на носителе - номер головки, стороны, дорожки,... |
| 4. | контрольная сумма |
| 5. | первый пустой промежуток (защитный интервал) |
| 6. | зона синхронизации |
| 7. | маркер данных |
| 8. | сектор данных |
| 9. | контрольная сумма |
| 10. | второй пустой промежуток |
Если присмотреться внимательнее к этому списку, то можно заметить две одинаковые структуры - с 1 по 4 и с 6 по 9. Вроде бы, не столь ясен смысл усложнять формат и зачем-то записывать два блока, адрес и данные, вместо одного. Но смысл всё же есть - адресные записи формируются при форматировании дискеты и больше никогда не меняются, а вот блоки 'данные' читаются и перезаписываются при работе с носителем.
Хочется сразу обратить внимание на важный момент - второй блок (данные) переписываются без затрагивания предыдущего и последующего адресных блоков, поэтому они обрамлены пустыми промежутками. Первый, после адресного блока, служит для компенсации времени переключения накопителя с чтения (адресного блока) на запись, второй (после блока записи) нужен на естественный разброс скорости вращения диска и время переключения магнитной головки с записи на чтение. То есть, длина сектора может немного меняться и в конце записи всегда есть немного мусора.
Попробую предположить, что современные HDD именно такой формат не используют - очень уж он нерационален по объему дополнительной информации. Ну, сами посудите, зачем в каждом секторе хранить номер дорожки, номер поверхности, да и номер сектора? Гораздо проще адресные метки оставить в ограниченном количестве, а сектора разделять просто зонами синхронизации с маркерами данных. Но и это не всё, зачем вообще вводить пустые промежутки между секторами данных? Это бессмысленная потеря места, причем весьма существенная.
Второй момент, не столь явный, но важный при выборе размера сектора. А именно - сбой при чтении данных. При кодировании информации на дискетах используется сигнал с совмещением данных и синхронизации. Четный фронт, точнее его изменение, индицировало данные, а нечетный - синхронизацию. Поля синхронизации и маркеров служили для того, чтоб контроллер отыскал в потоке ноликов и единиц определенный шаблон и далее правильно разбирал считываемую информацию. При механическом повреждении носителя может происходить перестановка четного-нечетного фронтов и, как следствие, 'данные' начинали восприниматься контроллером как синхросигнал, а 'синхросигнал' как данные. Если в секторе есть такое повреждение, то все последующая информация будет неверна в принципе.
Если бы сбой не сорвал синхронизацию, то сломалось бы всего несколько десятков бит, что можно поправить сдвигом остатка сектора и восстановления поврежденных байт каким-либо алгоритмом избыточного кодирования (например, коды Рида - Соломона). Короче, если информация на дискете портится, то выбивает весь сектор. Отсюда вытекают два логичных вывода - нет нужды делать побайтовые средства восстановления и вряд ли стоит использовать очень большие сектора. Но все сказанное опиралось на формат хранения данных FDD и было бы слишком оптимистично прямо переносить эти технологии на современный HDD.
Есть и третий момент - достоверность считывания. При уменьшении геометрического размера места хранения бита информации на поверхности носителя возрастает уровень шума, ведь поверхность магнитного носителя не идеальна и обладает микронеровностями. Сюда же надо добавить пыль, которая неизбежно присутствует в гермоблоке.
Кроме локальных сбоев чтения и записи, пыль увеличивает дефектность поверхности носителя не только попаданием под магнитную головку, но и просто соприкасаясь с поверхностью. Современные HDD с их скоростью вращения (5-7-10(15) тысяч оборотов в минуту или 80-170(250) оборотов в секунду) как-то не способствует спокойному и ламинарному течению потока воздуха. Впрочем, в гермоблоке устанавливается пылеуловитель, который собирает частицы за некоторое время работы HDD.
Итак, пыль может вызывать локальные (неповторяющиеся) ошибки чтения, причем достаточно продолжительные по объему информации. Если брать размер бита на магнитном носителе в 25 нм, то обычная пылинка в 0.5 мкм вроде бы нарушит прием трех байт. Однако просто представьте - магнитная головка парит над поверхностью диска на высоте порядка 5 нм и натыкается на пылинку 500 нм. Согласитесь, вряд ли магнитная головка сможет пролететь над помехой, скорее будет удар, который способен даже снести головку с дорожки.
Если в этот момент происходила запись данных, то 'увы', вплоть до стирания адресного блока, что означает появление soft-bad сектора. Если сказанное показалось незначительным, то хочу обратить внимание, что все дефекты от пыли (царапины) носят круговой характер и располагаются по дорожкам. Кроме того, пыльная взвесь нагревает магнитную головку, что может ухудшить качество ее работы.
Как говорится, всё меньше и меньше известно что-то вообще. Ну, продолжим.
Магнитная головка считывает и записывает данные последовательным способом, побитно, что означает очень высокую частоту передачи данных. Другая, не столь очевидная, проблема - на магнитный носитель нельзя записывать данные с постоянной составляющей. Если попытаться записать что-то вида 0001000 в виде полярности намагниченностей, то из-за группового эффекта 'единица' будет считана с меньшим уровнем - на нее частично наложится поле от множества соседних 'ноликов' (противоположная полярность намагничивания) и поле единички станет меньше вплоть до 'нечитаемого'.
Высокая частота передачи данных порождает отражения в канале передачи, что искажает информацию самым причудливым образом. Но есть и более неприятная вещь - из-за деградации высокочастотной части спектра уменьшается амплитуда коротких импульсов. Как следствие - можно их потерять. Если у вас когда-нибудь был магнитофон, то эта беда хорошо известна - чем больше слушаешь одну и ту же композицию, тем глуше звук. Сюда же можно отнести копир-эффект - громкие низко-среднечастотные звуки могут копироваться из одного витка ленты в другой между слоями пленки.
Не знаю как в технологиях HDD, а в системах передачи данных для компенсации этих дефектов применят механизм избыточного кодирования с исключением неудобных кодовых комбинаций.
Маленький пример.
Например, нам надо передать два бита. Всего вариантов четыре: 00, 01, 10, 11.
Если присмотреться, то варианты вида 00 и 11 дают постоянную составляющую. Точнее, они передают постоянный уровень.
Давайте передавать три бита вместо двух. Для трех бит будут комбинации: 000, 001, 010, 011, 100, 101, 110, 111.
Понятно, что 000 и 111 нам не подходят, а другие можно использовать, предположим, таким образом: 00 = 001, 01 = 010, 10 = 011, 11 = 100
В результате избавились от передачи постоянного уровня и получили условный признак сбоя передачи данных. При получении комбинации бит, которые не определены в списке, контроллер будет знать об ошибке. Подобное кодирование, как в примере, 2B3B, не применяется из-за больших накладных расходов (приходится передавать информации в полтора раза больше). Для 100BASE-TX используют кодирование 4В5В (не более трёх нулей), а под один гигабайт пришлось дополнить кодированием 8В10В (для передачи восьми информационных бит требуется отправить 10 бит).
С помощью избыточного кодирования удаляется не только постоянная составляющая (сигнал с неизменным уровнем), но вообще все среднечастотные и низкочастотные составляющие. Это позволяет решить проблему с уменьшением высокочастотного спектра, ведь только он и остается. Жертвовать приходится возрастанием частоты передачи на 25-40 процентов. Это много, очень много, но узкополосный высокочастотный усилитель сделать проще, чем широкополосный, хоть и с меньшей граничной частотой.
Интересно, используется в HDD технология избыточного кодирования, совмещенная с кодами восстановления? По идее, если вводить дополнительные биты для исключения неудобных комбинаций, так почему попутно не увеличить количество дополнительных бит и использовать их для восстановления? Скажем, что-то типа модифицированного кода Хемминга при кодировании 12B16B.
PRML можно перевести как "неполный отклик - максимальное подобие". Обычный способ оцифровки сигнала состоит в определении пиков уровней, для чего используется набор пороговых элементов (компараторов). Но для применения такого способа приема присутствует серьезная проблема – информационный сигнал весьма высокой частоты и в нём неизбежно присутствуют отражения сигнала, которые разрушают четкие логические уровни. Кроме того, носителем информации является магнитное покрытие диска, который к тому же еще и вращается, что не способствует надежному приему из-за высокого уровня шума.
Обычные способы повышения качества, в виде фильтрации и эквалайзера перед нелинейными элементами, уже не могут обеспечить приемлемую достоверность перевода аналогового сигнала в битовой поток логических “0” и “1”. Для работы с настолько некачественным сигналом необходимо перейти на принципиально иной уровень – оцифровывать сигнал с помощью высокоскоростного АЦП и далее выполнять цифровую обработку сигнала.
Идея алгоритма в том, что известны частота и фаза сигнала, что позволяет эффективно удалять отражения (они повторяют исходный сигнал, задержанный во времени) и шумы. По методам подавлений отражений можно почитать эхоподавление, сходная технология.
С шумом сложнее, у него широкий спектр и большая амплитуда – прямая компенсация невозможна. Вот тут на сцену и выходит PRML – алгоритм определения учитывает историю сигнала и возвращает наиболее вероятное значение. Обратите внимание, не четкий '0' или '1', а наиболее вероятное значение. Это тоже будет '0' или '1', но не с 100%-ной гарантией. Для улучшения декодирования и подавления постоянной составляющей используется избыточное кодирование, поэтому в рассуждениях выше есть какой-то смысл, хотя мысль об использовании кодов Хемминга несколько избыточна.
Информация на магнитном диске записывается побитно и его геометрические размеры можно посчитать из скорости вращения, производительности и геометрических размеров диска.
Размер хода головки около 25 мм, средний диаметр рабочей зоны диска примерно 64 мм (длина ~200 мм), зависит от разметки.
Подробнее по геометрическим размерам можно почитать на сайте в статье "Взгляд на жесткий диск «изнутри»":
Попробуем прикинуть, каковы размеры того, что хранится на поверхности магнитного диска. Информация на нем записывается побитно и его размеры элементов можно посчитать из скорости вращения, производительности и геометрических размеров диска.
Для вычислений необходимо знать средний диаметр дорожки и величину перемещения магнитной головки диска, то есть ширину всех дорожек. И то и другое мало зависят от модели HDD, поэтому их можно принять как 200 мм и 25 мм соответственно.
Количество дорожек можно определить из того факта, что скорость вращения диска известна и за один оборот считывает только одна дорожка. Величина бита вычисляется из емкости и длины одной дорожки. Емкость дорожки (усредненное значение) можно вычислить как средняя скорость чтения, деленную на скорость вращения диска.
| HDD | Скорость вращения, об/мин | Емкость диска, Гбайт | Дорожек, х1000 шт. | Ширина дорожки, нм | Длина бита, нм |
| WDC Green | 5400 | 250 | 173 | 145 | 35 |
| WDC Green | 5400 | 333 | 200 | 125 | 30 |
| Samsung Ecogreen F2 | 5400 | 500 | 250 | 100 | 25 |
| Seagate Barracuda LP | 5900 | 500 | 260 | 96 | 26 |
| WDC Black | 7200 | 333 | 223 | 112 | 33 |
| Seagate Barracuda 7200.11 | 7200 | 333 | 238 | 105 | 36 |
| Seagate Barracuda 7200.12 | 7200 | 500 | 288 | 87 | 29 |
| Samsung Spinpoint F3 | 7200 | 500 | 268 | 93 | 27 |
| Hitachi Deskstar 7K1000.C | 7200 | 500 | 280 | 89 | 28 |
Расчеты обладают низкой точностью из-за массы грубых допущений, но позволяют получить общее впечатление. С толщиной волоса сравнивать не стоит, избитый штамп, но вспомните о технологических нормах производства современных микросхем – подчас размер транзистора может быть больше бита на поверхности диска.
Итак, числа перед вами, хочется лишь обратить внимание, что повышение скорости вращения потребовало увеличить длину бита и уменьшить ширину дорожки. Этому есть логичное объяснение - повышение скорости вращения увеличивает частоту сигнала в магнитной головке и ухудшает качество ее работы – при записи на поверхности диска растет минимально необходимый интервал между битами данных. Уменьшение ширины дорожки добром не кончится, к этому вопросу еще вернемся.
В HDD информация хранится на поверхности магнитного слоя дисков. Для чтения и записи информации используется магнитная головка.
Активные размеры магнитной головки меньше одного микрона, поэтому детальную фотографию сделать достаточно проблематично – придется, как всегда, объяснять 'на пальцах'. Она состоит из двух элементов - узла считывания, основанного на эффекте изменения сопротивления от приложенного магнитного поля, и магнитной (соленоидной) головки записи. Эти два элемента расположены вдоль траектории рабочей поверхности, то есть по прямой, друг за другом. Но сразу хочу отметить - активные зоны узла считывания и узла записи несколько разнесены по пути движения. Причина тривиальна, нельзя же два узла поставить один на другом, поэтому их разместили последовательно, друг за другом.
Понятное дело, что на картинке весьма условное изображение. Немного подробнее с GMR магнитной головкой можно ознакомиться на этой странице. Приведу картинку из статьи, очень уж она информативная.
Есть неприятность, спрятавшаяся в принципе перемещения головки. Это только один способ установить магнитную головку на нужную дорожку – повернуть позиционер. Но при этом и сама головка повернется, и будет двигаться по дорожке под некоторым углом. Вначале картинка:
Пояснения:
Красные линии – три положения позиционера – конец рабочей поверхности диска (ближе к его центру), примерно середина и начало;
Синие – касательные линии к направлению дорожек в месте положения магнитной головки;
Зеленые точки – положение магнитной головки на конце коромысла позиционера.
Угол поворота позиционера порядка 30 градусов и это много. Можно несколько снизить остроту проблемы, если немного придвинуть его центр вращения ближе к диску. При этом дуга движения головки станет несколько выше радиуса к центру диска. Тогда в зоне от центра до середины рабочего хода угол поворота головки к дорожке будет небольшим.
Ранее я ссылался на статью "Взгляд на жесткий диск «изнутри»", воспользуюсь картинкой из нее:
Я не знаю, как именно получено данное изображение, но оно весьма четкое. Отчетливо видны зоны намагниченности.
При повороте головки относительно направления движения, точно так же ‘повернутся’ и зоны намагниченности. Для компенсации этого дефекта придется увеличивать шаг размещения битов и (в качестве вынужденной меры) уменьшить ширину дорожки.
В принципе, подстройки небольшие, хуже другое – головка записи хоть и рядом с головкой чтения, но всё же не на одном и том же месте. Это значит, что при повороте магнитной головки центры головок (по отношению к дорожке) разойдутся.
Позволю себе изобразить коллаж по этому вопросу:
Поворот всего на 15 градусов, а смещение между головками чтения - записи уже заметно и довольно отчетливо. Для обхода дефекта можно или банально увеличить ширину дорожки или дополнительно сдвигать магнитную головку при смене режима чтение - запись. Не слишком ли накладно? Время смены дорожки порядка 1 мсек. Сдвиг не настолько сложная процедура, поэтому попробуем весьма безосновательно предположить на порядок меньшее время. За 0.1 мсек под головкой пройдет 10 Кбайт данных.
Гм, вроде бы тривиальная процедура 'прочитать сектор' из 'прочитал адресный маркер – записывай данные' превращается в нечто монстроидальное – прочитал адресный маркер с номером ‘-10 Кбайт’, неторопливо сдвинул головку, записывай. И, желательно, в свой сектор. Короче говоря, техническая проблема есть.
Пока с этим дефектом мирятся – шаг дорожек на внешних треках делают больше, учитывая смещение головок. Вторым действием является некоторое уменьшение ширины головки чтения (на рисунке отмечено желтым) и небольшое смещение её центра на дорожке в режиме 'запись'. В результате, она оказывается выравнена по краю, а головка записи не выходит за пределы дорожки. Цена – небольшое снижение эффективности работы головки чтения, но отпадает необходимость динамически смещать всю магнитную головку в режиме записи. Но - снижение эффективности будет только в режиме записи, для чтения нет необходимости удерживать головку чтения у края дорожки.
При движении по дорожке магнитная головка постоянно центрируется по ней, поэтому дополнительный сдвиг можно совместить с процедурой стабилизации на дорожке. Весьма упрощенно, механизм удержания на дорожке работает следующим образом – между дорожками по всей их длине (по кольцу) расположены специальные маркеры. Несколько упрощенно, маркеры расположены попеременно с правой и левой сторон по ходу движения. Когда головка движется по дорожке, она определяет наличие маркеров (с обеих сторон) и запоминает амплитуду разностного сигнала от них. Величина и знак полученного сигнала говорит о смещении от середины между маркерами, а именно - от центра дорожки.
Да, это весьма медленный способ центровки и он потенциально не способен учесть смещение головки между маркерами разметки. Магнитная головка движется не в вакууме, на нее весьма интенсивно действуют воздушные потоки (и пыль), да и сам диск вибрирует, поэтому ее траектория движения слегка флуктуирует. Если сравнить с огнестрельным оружием, то пуля никогда не движется по прямой (скорее параболе). Для стабилизации пулю закручивают, но вряд ли кто-то станет закручивать магнитную головку в HDD, по крайней мере, я об этом не слышал.
Для полноценной системы стабилизации необходимы две дополнительные обмотки, что дает возможность постоянно измерять величину смещения и оперативно ее компенсировать. Но … одну-то головку сделать трудно, вспомните о ширине и длине бита информации, а еще две дополнительные – просто жуть.
Зоны серворазметки занимают существенное место, причем в смежных дорожках одновременно, что снижает полезную площадь диска, их количество стараются делать не слишком большим. Конкретное значение зависит от фирмы производителя и области применения HDD, обычно находится в диапазоне 200-800 штук на дорожке. Много? Одна метка на 2-4 Кбайта.
Если магнитная головка начала уходить с курса (из-за механического воздействия или собственного колебательного процесса), то о сей неприятности она узнает только через 4-8 секторов, на следующей сервометке. При чтении ничего страшного, пропустит оборот и повторит операцию, а вот при записи всё хуже – считывать-то адресные маркеры магнитная головка наверняка сможет, а вот записывать она точно будет 'по диагонали'. Попользовались таким диском, и дорожки будут выглядеть как ёж – ”/\/\/\”. Безрадостно? Наложите на это аналогичный 'слалом' соседних дорожек.
Перед выполнением операций с секторами, HDD должен выставить головки на нужную дорожку. Собственно, на этом заканчивается достоверная информация и начинаются гадания. Как и всё, что касается низкоуровневого представления, закрыто плотным NDA. Что бы ни означали эти буквы, но информации нет. Что же, будем использовать "здравый смысл".
При переходе с дорожки на дорожку контроллер выдает новое значение тока соленоида позиционера, что вызывает перемещение головок. Вполне очевидно, что форма тока не постоянна во времени, применяется активный разгон и активное торможение (кстати, это вызывает повышенное потребление, поэтому степень 'активности' зависит от модели и области применения данного накопителя).
Позиционер лишен четких положений, нельзя гарантированно точно изменить его положение на нужное количество дорожек. Это раньше применялись шаговые двигатели (а в приводах на гибких магнитных дисках и сейчас), которые могли смещаться на одну дорожку при одном импульсе управления. В HDD для перемещения головок используется соленоид, а это означает весьма условную величину перемещения на изменение его тока.
С точки зрения математики, нет никаких проблем перевести нелинейное преобразование величины тока в целевое положение, вот только мешают случайные факторы - напряженность магнитного поля магнитов соленоида и ориентация HDD в пространстве, вещи довольно нестабильные. Поэтому контроллер может 'толкнуть' позиционер только на предполагаемое положение дорожки, а потом уточнять реальное положение и "дальше по обстановке". Для того чтобы узнать положение, используется чтение специальной разметки с номерами дорожек (и секторов). Значит, алгоритм позиционирования состоит в 'прыжке', потом головка выравнивается на текущей (куда попала) дорожке и осуществляется поиск записи с номером дорожки. То есть тупо сидит и ждет.
Поэтому есть довольно четкая зависимость между количеством адресных меток со временем позиционирования. Утрированно: если на дорожке только одна метка, то контроллеру придется, в среднем, ждать 1/2 времени оборота диска. Чем больше количество меток, тем меньше бессмысленные траты времени, но сами метки занимают место на дорожке, что уменьшает полезную площадь. Одна метка явно плохо, а, например, 50 или 100 почти одинаково малы и не мешают позиционированию. Сколько в реальности - не знает никто, из простых смертных. Но, судя по всему, количество меток уменьшается.
Впрочем, это не самое интересное в данном процессе. После нудного ожидания номера дорожки, контроллер всё-таки его получает и принимает решение по следующему перемещению позиционера, ведь это точно не та дорожка. Теория вероятности не исключает возможности сразу попасть на свою дорожку, но такого никогда не произойдет - на современных дисках порядка 200 тысяч дорожек. При перемещении на 100 тысяч, каков шанс, что удастся попасть именно на нужную, даже при условии довольно точных предсказаний перемещения? Практически нулевой.
Итак - 'промазали', значит надо сдвинуться и повторить-повторить...повторить. Пока конец дорожки не будет найден. Дорожка найдена, но операции надо выполнять не над первым попавшимся сектором, а с вполне конкретным. То есть контроллер должен ждать нужный сектор. Теперь вопрос - что делает контроллер в те моменты, когда 'ждет'? Самый простой и бессмысленный ответ - ничего. Однако во время ожидания контроллер мог считать довольно много информации с нескольких дорожек, в том числе и целевой. У него есть буферная память, где эту информацию можно сохранять. Понятное дело, что полученные данные никак не пригодятся при записи (хотя, и тут не всё гладко), но бо́льшую часть времени HDD выполняет операции чтения.
Последовательное чтение означает получение информации с (обычно) последовательно расположенных секторов. Причем, операции выполняются блоками, величиной от одного сектора до MaxTransferLength. Последний параметр считывается из конфигурации привода операционной системой и обычно составляет 128 Кбайт. Обычно. Но некоторые устройства, чаще всего экзотические на Flash памяти, не поддерживают блочный режим, что крайне негативно сказывается как на общей производительности накопителя, так и на загрузке процессора при выполнении обмена с ним.
Для операционных систем *nix есть программа, которая возвращает параметр MaxMultSect, который есть то же самое, что и MaxTransferLength, только измеренное в 'секторах', а не байтах.
Итак, при выполнении команды чтения контроллер устанавливает головки в нужное положение на диске (дорожке), ждет появления конкретного сектора и начинает читать его в буферную память. Считав нужное количество секторов, контроллер накопителя выставляет в устройство ввода-вывода настройки для передачи считанного блока и начинает саму передачу данных. После этого он переходит к обработке следующего запроса. Данный вариант описан для обычного режима (IDE), в спекулятивных вариантах (AHCI или RAID+AHCI) будет несколько иначе, но не важно.
Важно другое - если вы думаете, что происходит именно так, то гарантированно ошибаетесь. Подчеркиваю - ошибаетесь безвариантно. Если бы контроллер обрабатывал запросы подобным 'последовательным' образом, то к началу обработки второго запроса (смотрите название параграфа - последовательное чтение) диск бы здорово сместился, и некоторое количество секторов просто пролетело мимо. То есть контроллер обязан (!) читать в буферную память то, что идет после (!) запрошенных данных. По некоторым слухам, HDD читает всю дорожку сразу. Может и не 'всю', но существенную часть точно.
В параграфе "Позиционирование" описывалось возможное поведение контроллера при позиционировании на целевой дорожке и, по логике вещей, выходит, что он может считывать информацию до нужного сектора. При выполнении самой команды чтения считывается нужное количество секторов (которое всяко меньше объема данных на дорожке одной поверхности) и далее хотя бы один сектор. Попробуем предположить, что он дочитывает сектора до полной дорожки.
С точки зрения операционной системы, данные считываются в последовательности 'установил дорожку' - 'прочитал' - 'передал', и так множество раз. А в реальности? Какой смысл что-то считывать, если это уже лежит в буферной памяти, да и само чтение потребует еще одного оборота диска? Естественно, никто так не делает. Команды чтения выполняются по несколько измененному пути: один раз 'установил дорожку' - 'прочитал' - 'передал' и во множестве 'взял из памяти' - 'передал'. При этом сам контроллер может начать выполнение следующей команды (для режимов AHCI).
Этот режим во многом повторяет идеологию последовательного чтения, только для случая записи кэшировать считываемые данные не надо и "пишется, как пишется". Естественно, контроллер будет 'умничать', он обязан (!) это делать - при записи данные собираются в буферную память, но не записываются до тех пор, пока не соберется достаточно большой последовательный набор секторов.
Причина здесь та же, что и в последовательном чтении - если долго копаться, то нужный сектор уже успеет пролететь под магнитной головкой и для получения доступа к нему придется ждать еще один оборот диска. То есть HDD без кэширования записи не работают. Объем локального кэширования должен быть не меньше количества секторов между адресными метками, если они поделены на блоки секторов, а лучше равняться размеру всей дорожки.
При последовательной записи, да и записи вообще, есть серьезная техническая проблема - запись неполного блока. В таком случае контроллер лишен права начинать запись без предварительного считывания всего блока хранения информации (сектора). И здесь могут быть проблемы. Гипотетически, было бы просто здорово поставить головку чтения на 'много' вперед и она бы считала тот блок информации, который сразу же был бы перезаписан с добавлением новых данных. Но... увы, позиционер поворачивает головку на дорожке при перемещении между ними, что исключает "гипотетически". Значит, придется тратить еще один оборот диска на считывание нужных секторов.
В любом случае, надо это непосредственно сейчас контроллеру или нет, но система кэширования через буферную память себя оправдывает.
Вначале о самой важной составляющей части - о микросхемах Flash памяти типа NAND. Их бывает три типа:
SSD на микросхемах SLC довольно дороги. Скорее всего, будущее за MLC, поэтому только о них и пойдет речь.
Формат хранения данных в Flash памяти типа NAND медленно эволюционировал к повышению емкости микросхем и к снижению времени доступа, но за последнее несколько лет этот тип памяти претерпел существенные, не побоюсь этого слова, революционные изменения. Если в младенческие времена NAND была очень простой - поставил адрес и читай или записывай страницу, то на данный момент вроде бы мелкие изменения привели к качественному скачку. Появилось разделение на несколько поверхностей (plane), несколько независимых банков (Logical Units, LUNs), количество независимых микросхем в одном корпусе превысило количество ‘один’. Кроме того, был добавлен синхронный режим работы. Если брать все эти изменения 'по одному', то выигрыш от применения будет небольшой, но их суммарное воздействие сказывается крайне приятно на общей производительности.
Давайте, процитируем организацию Open NAND Flash Interface (ONFI), специализирующуюся на разработке стандартов внутренней организации микросхем такого типа:
A device contains one or more targets. A target is controlled by one CE# signal. A target is organized into one or more logical units (LUNs).
Эта фраза означает, что в одном корпусе может находиться одна или несколько дискретных микросхем NAND, которые выбираются с помощью индивидуальных сигналов выборки CE (Chip Enable, выборка микросхемы). Каждая микросхема может содержать один или несколько логических блоков (LUN). Стоит сразу добавить, что один логический банк может содержать несколько плоскостей (plane).
Давайте возьмем что-то конкретное, а то от формулировок ONFI вида "один или несколько" меня уже в дрожь бросает.
Например, MT29F32G08. В ее спецификации написано:
1. # of CE# = 2
2. # of die = 4
3. Common
Пункт первый, тут просто - две независимые микросхемы (targets).
Пункт два, несколько сложнее - 4/2 = две микросхемы с двумя логическими блоками в каждом.
Пункт три - общая шина данных. Еще бывает "Separate", что означает раздельные выводы шины данных для всех микросхем в корпусе. Про последний вариант лучше сразу забыть - под MLC память его практически не встречается, как и 16-битной шины - банально дорого, требуется очень уж много выводов в корпусе, что стоит денег. Да и геометрические размеры растут, снова затраты.
Так, стоп! Давайте посмотрим на одну таблицу, сейчас поймете зачем:
Электрическая емкость выводов зависит от количества устройств, подключенных к данному сигналу внутри корпуса.
И что же выходит? ... емкость прямо пропорциональна количеству LUN'ов!
Так, всё, счищаем лапшу с ушей. Пусть господа ONFI и дальше играют в свое квазиумничанье, а я скажу прямо - и LUN, и Die (target?) есть одно и то же. Меняется принцип выборки - аппаратный сигнал CE для target и старший (старшие?) для LUN(s), но суть одна и та же - в корпус запихнули множество независимых микросхем NAND. Так что, не забивайте себе голову глупостями с разбивкой на LUN и target.
Кстати, в спецификации микросхемы указано "Density – 32Gb (quad-die stack)". Фууу, и на том спасибо. Четыре. Независимых устройств четыре и точка.
Итак, посмотрим на структурную схему NAND:
В принципе, здесь изображена половина микросхемы из примера (для одного target) - два LUN с двумя поверхностями на каждом.
Итак, про ‘разные’ LUN забыли, это не интересно, и сосредоточим внимание на детальную структуру одного LUN. Он состоит из пары плоскостей, состоящих из блоков, которые, в свою очередь, собираются из секторов. Неплохая выходит матрешка. Если присмотреться внимательнее, то замечается явная аналогия с форматом HDD. Сектор = страница, дорожка = блок, сторона диска = plane. Довольно странно - у диска две стороны, а у NAND всего две plane. Складывается ощущение, что в ONFI собрались ярые фанаты накопителей на жестких дисках.
Страница - минимальная адресуемая единица чтения (или записи) информации. Можно прочитать/записать и меньше, но все остальное, 'остаток' страницы, все равно считается из NAND при чтении или запишется мусором при записи. Однако некоторые типы микросхем (обычно это SLC) поддерживают работу с неполными страницами.
Блок - минимальная единица стирания информации. Если бы в NAND можно было стирать блоки, равные размеру страницы, то это было бы просто и красиво. Но разработчики видимо посчитали, что это было бы слишком уж просто и исключили возможность стирания одиночных страниц.
Плоскость (plane) - некий элемент для повышения скорости работы. Весь LUN делится на две равные сущности, которые могут работать (относительно) независимо. Возможно, вы спросите, почему бы не считать это разбиение аналогично дроблению одного корпуса на target и LUN? Да, плоскости могут независимо выполнять команды, но разработчики опять позаботились, чтоб пользователям было не слишком удобно. Например:
Two-Plane Addressing
Two-plane commands require two addresses, one address per plane. These two addresses are subject to the following requirements:
В переводе это звучит примерно так:
Последнее свойство объединяет плоскости лучше сиамских близнецов - разделять их на что-то независимое будет так же трудно, как (у автора кончилась фантазия, извините).
Слава разработчикам, они думают за нас, чтоб, ни дай Бог, что-то работающее не вышло.
Итак, через плоскости, то есть одновременно, можно выполнять команды:
в виду явной надуманности, не все микросхемы поддерживают режим чтения по плоскостям. Используйте конвейерный запрос чтения через буферный регистр.
Операции с четными банками будут выполняться на нулевой плоскости его контроллером, а для банков с нечетным номером - на первой плоскости силами его контроллера.
Да, 'уффф', тягомотина закончилась, переходим к чему-то более интересному.
При включении микросхема NAND работает в асинхронном режиме работы с передачей информации по управляющим сигналам. Это классический режим работы, только очень уж медленный.
Вычисление времени множества параметров долгая и весьма неточная процедура (из-за различий в быстродействии разных режимов), поэтому воспользуемся любезно предоставленной презентацией "ONFI 2 Source-Synchronous Interface Breaks the I/O Bottleneck".
В документе приводится информация, что асинхронный режим передачи данных ограничен 160 Мбайт/сек (страница 11).
Обратите внимание на максимальную высоту столбиков – ограничение именно из-за шины передачи данных. Для устранения этого досадного ограничения в ONFI 2.0 был введен режим синхронной передачи данных. При этом данные передаются по обоим фронтам управляющей частоты. Наверно, вы обращали внимание на странные цифры в маркировке микросхем NAND, довольно часто там фигурируют цифры вида "-12". Это означает, что для синхронного режима работы можно использовать задающий сигнал с периодом 12 нс, или 83 МГц, что означает скорость передачи данных 83*2=166 МГц.
Снова воспользуемся презентацией ONFI - в ней фигурирует скорость чтения, для подобного способа передачи, 800 Мбайт/сек (страница 21).
Разница почти в пять раз, и вызвана тем, что протокол чтения состоит из фазы выдачи команды чтения, установки адреса ... (подождать) ... считывания данных. Эту цепочку нельзя прервать для выдачи новой команды, ведь и команда, и адрес, и данные передаются через одну и ту же шину. Поэтому сокращение бессмысленного времени на передачу данных снимает ограничение на производительность всего устройства.
В документации по NAND фигурирует понятие 'регистр данных' (Data Register), в котором хранятся данные на запись или уже считанные из матрицы. То есть рисуют на картинках и пишут в тексте 'регистр', но речь идет о блоке данных в одну страницу (плюс небольшая зона под коды коррекции). А именно, размерность порядка 2 или 4 Кб (зависит от размера страницы в конкретной NAND). Пусть вас не вводит в заблуждение слово 'регистр', там лежит вся страница.
Для ускорения работы каналов передачи данных применяют дополнительную буферизацию, снимающую требование обязательной синхронности процесса записи с выполнением, что устраняет дополнительные задержки на ожидание. В NAND применяется аналогичный прием, между выходом и регистром данных вставлен кэширующий регистр. Его основная функция - сохранять данные до тех пор, пока они не будут переданы из устройства (при чтении) или помещены в освободившийся регистр данных (при записи).
Для последующих иллюстраций я буду использовать "Optimizing NAND Flash Performance", представляемой организацией ONFI.
Процедура чтения состоит из фаз выдачи команды и адреса страницы, небольшого ожидания и вычитывания данных. Проблема в "небольшом ожидании".
Хочу обратить внимание – на картинках красным цветом обозначается ожидание готовности устройства. Чем больше 'красного', тем менее эффективно работает обмен.
Для устранения ожидания можно сделать конвейерное чтение через кэш-регистр. Суть его в том, что во время вычитывания данных из NAND происходит загрузка из матрицы информации по следующей странице. Конкретно (и несколько упрощенно), происходит следующее:
Как вы наверно заметили, дополнительные накладные расходы ожидания есть только для чтения первой страницы, все остальные идут без пауз - время ожидания выполнения чтения из матрицы Flash скрадывается временем передачи данных из микросхемы - они идут параллельно.
Дополнительную экономию можно получить, используя команду кэширующего чтения без передачи полного адреса, просто указывая "следующий". Экономия небольшая, но есть.
Запись выполняется примерно таким же способом, что чтение, только намного дольше. Наверно, не стоит детально расписывать последовательность выполняемых действий и событий, логика происходящего аналогична чтению, только 'наоборот'. Процедура записи состоит из фаз выдачи команды, адреса, пересылки страницы данных и дооооолгого ожидания. Само время ожидания уменьшить нельзя, запись делается аппаратно контроллером в микросхеме NAND (для каждой плоскости свой).
Немного ускорить процесс записи нескольких страниц можно приемом, аналогичным применяемому в операции чтения - воспользоваться буферным регистром. При этом запись первого блока ведется обычно, но после окончания отправки данных контроллер принимает команду и данные в буферный регистр, который хранит их до освобождения регистра данных и начала следующей процедуры записи. Экономия? - на времени передачи данных, что откровенная мелочь в сравнении со временем ожидания окончания записи.
Однако вовсе не случайно в NAND применяется деление на плоскости. Это позволяет выполнять такую длительную процедуру, как запись, параллельно на плоскостях. То есть можно выдать команду записи для страницы банка I, потом сразу, без ожидания окончания процедуры, выдать команду записи для страницы банка I+1.
Дальнейшее повышение производительности можно получить, комбинируя оба варианта - запись через буферную память сразу на обе плоскости.
Увы, разработчики не забыли о нас, простых смертных. Сделать стирание произвольной страницы было бы слишком просто для использования, этого они позволить не могли, видимо. Стереть выбранную страницу не получится, эту операцию можно сделать только над блоком ... который состоит из множества страниц. Ладно, без лирики, а то цензура не пропустит.
Время стирания блока самая долгая процедура в NAND. Оно исчисляется единицами миллисекунд. Для сравнения, время программирования страницы порядка 0.3 мс, а время ожидания данных при чтении 20-30 мкс. Понятное дело, что стирается сразу много страниц, ведь блок большой, но все равно долго. И, что особо неприятно, на всё это время будет занята вся плоскость.
Традиционный способ ускорения через буферную память здесь не применяется ввиду очевидной глупости экономии, да и ... при стирании нет нужды передавать данные. Единственный способ ускорить стирание - запустить такую команду на обеих плоскостях одновременно. Очистка будет идти практически в два раза быстрее, но будут заняты обе поверхности, причем на длительный интервал времени. К этому нюансу вернемся позже.
Для балансирования нагрузки на страницы, приходится перемещать данные из редко использованных страниц в сильно использованные, а освободившуюся память использовать для интенсивной работы. Среди команд NAND есть несколько, которые позволяют перемещать данные внутри одного LUN, точнее в пределах одной плоскости. Фактически, выполняется связка Read + Write, только данные пересылаются внутри микросхемы самим контроллером плоскости LUN (их пара на LUN, по одному на плоскость). Времени это занимает немногим меньше обычной команды записи, да и функциональность ограничена рамками LUN. Сложно сказать, используют ли контроллеры SSD сии команды, ведь механизм их работы сильно ограничивают возможности по перемещению данных, а выигрыш незначительный.
Воспользуемся измерением производительности из "Optimizing NAND Flash Performance", любезно предоставленной фирмой Micron.
Вначале для случая применения одного LUN. Память все та же, MLC.
Производительность одного LUN озвучена выше, что же дальше? Современные SSD обеспечивают чтение данных порядка 200 Мбайт/сек и запись 40-70 Мбайт/сек. Для обеспечения таких скоростей надо как-то одновременно считывать 200/36=6 LUN, а при записи использовать 40...70/9.6 = 5...8 LUN. Причем, последние цифры даны без учета затрат на стирание и перемещение данных внутри SSD для выравнивания нагрузки. Означает ли это, что в современных накопителях Flash памяти повсеместно применяется 5-10 независимых каналов? Отнюдь, это от лукавого!
Ранее было отмечено, что в одном корпусе может находиться несколько независимых устройств хранения информации, а именно - LUN. Организовано это собрание может быть различно, через разные управляющие сигналы выборки CE или/и через старший бит адреса. Но это способ, а суть не меняется - они независимы. Итак, сколько LUN может быть в одном корпусе?
А сколько угодно (почти шутка), стандарт это позволяет. На данный момент больше двух LUN на один target не изготавливают, хотя для этого нет никаких ограничений. В одном корпусе может быть 1-2 target.
Все сказанное относится к тем микросхемам, которые могут встретиться в распространенных SSD. Если брать 'вообще', то и не такие монстры попадаются ... но шанс увидеть их 'в живую' крайне мал.
Итак, в одном корпусе может быть 1-2-4 LUN. Все эти LUN независимы, что позволяет над ними выполнять то, что ранее делали с плоскостями - запустить команды одновременно на нескольких устройствах. При этом полная производительность 'корпуса' (назвать это просто 'микросхемой' язык не поворачивается) увеличится почти пропорционально. Давайте снова обратимся к "ONFI 2 Source-Synchronous Interface Breaks the I/O Bottleneck", страница 21.
Напоминаю, что 'Die' и LUN одно и то же, а 'Channels' следует понимать буквально - количество каналов (или корпусов микросхем на независимых шинах данных).
В таблице даны результаты для одного-двух-четырех LUN. Последний вариант, с четырьмя LUN встречается редко, поэтому прошу интерпретировать последний столбец как вариант установки двух корпусов. С точки зрения логики работы устройства, абсолютно неважно, будет ли использоваться один корпус с четырьмя target или два корпуса с двумя target. Просто будет заниматься больше или меньше места на печатной плате, а программное обеспечение контроллера SSD не заметит никакой особой разницы.
Обычно контроллеры, обслуживающие высокоскоростные NAND, поддерживают 4 (и больше) CE на один канал (4 target).
Пожалуйста, учтите важный момент - в презентации Micron использован классический, асинхронный режим LUN, что ограничивает скорость чтения. На запись такое замедление практически не оказывает влияния, ведь не оно ограничивает производительность (а время записи страницы).
Но, кому сейчас интересен асинхронный режим? Кто позволит себе 'просто так' потерять две трети производительности чтения? Так что, переходим к странице 21 и начинает очередную медитацию.
Начнем с режима чтения:
| Количество каналов | Скорость чтения, 1 LUN. Мбайт/сек |
Скорость чтения, 2 LUN. Мбайт/сек |
Скорость чтения, 4 LUN. Мбайт/сек |
Скорость чтения, 8 LUN. Мбайт/сек |
| 1 | 88 | 176 | 200 | 200 |
| 2 | 176 | 352 | 400 | 400 |
| 4 | 352 | 704 | 800 | 800 |
Если внешним интерфейсом устройства будет SATA 2 (максимальная производительность 250 Мбайт/сек), то вряд ли рационально применение больше двух каналов и общего числа LUN больше четырех.
Теперь о записи:
| Количество каналов | Скорость записи, 1 LUN. Мбайт/сек |
Скорость записи, 2 LUN. Мбайт/сек |
Скорость записи, 4 LUN. Мбайт/сек |
Скорость записи, 8 LUN. Мбайт/сек |
| 1 | 8 | 16 | 32 | 64 |
| 2 | 16 | 32 | 64 | 128 |
| 4 | 32 | 64 | 128 | 256 |
А вот для записи зависимость линейная – чем больше LUN, тем лучше результат, без каких-либо признаков насыщения.
Для SSD, эмулирующей SATA 2 с ее ограничением в 250 Мбайт/сек, скорости выше озвученных 250 Мбайт/сек лишены смысла. Иначе говоря, для режима 'чтение' вполне достаточно контроллера с двумя каналами, с парой LUN на каждом. Много или мало 2 LUN? Вообще-то, это один корпус. Иначе говоря, для обеспечения очень высокой скорости чтения достаточно поставить всего две микросхемы. Очень даже бюджетное решение.
С записью сложнее, для MLC это тяжелый процесс и требует более мощной конфигурации.
Если у SLC скорость записи в 224 Мбайт/сек с достигается при двух каналах и четырех LUN на каждом, то MLC получение похожей производительности потребует уже 6-8 каналов * 8 LUN.
Восемь LUN это много? Для современных микросхем - да. Хотя стандарт и поддерживает четыре CE, что означает максимум восемь LUN (по два на CE), но такие микросхемы пока не особо распространены. Даже вариант два CE * два LUN почему-то не ставят в SSD. Что же, приходится эти '8 LUN' набирать большим количеством микросхем (и каналов, если используются микросхемы с одним LUN на CE).
Современные тенденции развития электроники направлены на миниатюризацию, поэтому следует ожидать плавного перехода на 4-8 LUN микросхемы, что обеспечит компактность и снижение стоимости, ведь отпадет необходимость в 5-8-канальных контроллерах.
Ну хорошо, технология NAND может обеспечить высокую скорость чтения и сносную - записи, но ведь это еще не весь SSD. Для работы устройства необходим достаточно высокопроизводительный контроллер и "какие-то" алгоритмы его работы по обслуживанию среды хранения информации (NAND) и ее передачи в систему (SATA или PCI-Express). "Какой-то" заключено в кавычки по банальнейшей причине - если по аппаратуре ходят слухи, то по алгоритмам и их нет. Что ж, будем делать безосновательные предположения и безапелляционные выводы, они сами напросились.
Возьмем то, что подвернется под руку.
Intel 29F64G08CAMD1-17
Это означает, что на один target приходится один LUN. Признаки наличия плоскостей и синхронного режима отсутствуют.
Интересна маркировка скоростного режима '-17'. Стандарт ONFI декларирует для асинхронных режимов 4 и 5 время 25 нсек и 20 нсек соответственно. Более скоростного асинхронного режима нет, но если бы он все же был, то 17 нсек смотрелось бы очень к месту. Если же брать синхронные режимы, то близкими по значению могли бы быть Mode 2 (20 нсек) и Mode 3 (15 нсек). Нет, совсем не похоже.
' common' – выводы всех target объединены.
Micron MT29F32G08CBABBWP
Скучно, всего один LUN.
Micron MT29F64G08CFABAWP
Две target, на каждом один LUN.
Стоит сразу уточнить, интересует не выполнение какой-то конкретной операции, а методика взаимодействия массива LUN с контроллером. Повторюсь, лично я точной информацией по данному вопросу не располагаю и, извините, все сказанное будет измышлизмом, что делает предположения весьма условными. Данные лежат страницами в LUN, но - как конкретно? Вариантов исполнения множество и, по счастью, они все базируются на принципе чередования. Но и здесь не всё просто - чередование может осуществляться на разных уровнях и соответствовать разной гранулярности - байт-чередование, блок-чередование, страница-чередование, плоскость-.... и вообще без чередования. А что, так же проще всего.
Ближайшую аналогию происходящего можно сопоставить с технологиями массивов RAID 0, когда два (несколько) диска могут выполнять операции с одним и тем же файлом одновременно, что повышает общую производительность. В SSD множество LUN и этот путь развития возможен, но здесь выходит на первый план такой параметр, как размер Stripe (величина блока чередования). В RAID 0 при обмене информацией, меньший Stripe, работает только один из накопителей. Впрочем, не все могут детально знать механизм работы RAID 0, поэтому очень кратко - в данной организации несколько дисков (положим, два) подключаются к контроллеру, который представляет их как один диск большей емкости. Ни первый, ни второй физический диск в системе не видны, их нет - вместо них система видит 'нечто' удвоенной емкости.
При записи контроллер рассыпает запросы чтения/записи на оба диска, которые выполняют их независимо, то есть одновременно. Например, при Stripe = 32 Кб и системном запросе чтения файла 64 Кбайт сам контроллер отправит по одному запросу чтения 32 Кбайт в диск номер один и номер два. При этом первые 32 Кбайт контроллер получит через то же время (с той же производительностью), что и в режиме без RAID 0, зато вторые 32 Кбайт будут для него 'бесплатными'.
Иначе говоря, система получит данные быстрее только по оценке времени 'среднее', если же оценивать мгновенную скорость поступления данных, то это может быть даже медленнее режима без RAID из-за дополнительных временных расходов на обслуживание контроллера и сегментирование обмена от небольшого размера Stripe. Сюда же стоит добавить возросшую загрузку процессора на гораздо бо́льшую активность операций ввода-вывода, ведь простые встраиваемые контроллеры RAID 0 не соединяют блоки Stripe и чтение большого блока данных рассыпается на множество запросов с размером Stripe. Увы, но объединения нет. Поэтому, для оптимизации Stripe была создана программа HAB. Я буду еще ссылаться на эту программу, но пока давайте завершим микрообзор RAID 0, сейчас это не самое интересное.
Слегка упростим себе жизнь и рассмотрим режим однопоточный работы, без каких-либо вариаций NCQ. В режиме 'простой' для устройств подобного типа происходит весьма энергичная деятельность ... но давайте и здесь пока считать, что в режиме простоя контроллер спит.
Итак, контроллер спит (так или иначе, но любой контроллер в простое переходит в IDLE режим разной степени), и тут совершенное неожиданно приходит запрос на чтение последовательной группы секторов 4 Кбайт.
Первое, что он сделает, это отправит запрос в нужный LUN на чтение самого первого сектора, тут без вариантов. Но что будет происходить сразу после этого - как считывать следующие сектора так, чтобы не упала общая скорость?
Какие вообще можно применить методы расщепления для повышения производительности:
1. Байт-чередование.
Название условное и означает, что сектор данных равномерно распределяется между несколькими страницами NAND. Условность в размере чередования, вряд ли разумно распределять по байту в странице, ведь для получения сектора данных (512 байт) требуется считать одновременно 512 страниц NAND. Обращаю внимание на то, что при записи будет еще бо́льшая проблема. Все же, пока забудем о ней и рассмотрим, что данный прием может принести.
Понятно, что ‘байт’-чередование довольно глупо, скорее надо говорить о ‘строка-чередование’, скажем 512 байт. (Почему это число? Мммм - смотрит на потолок - скажем.)
Для получения обычного сектора в 4 Кб потребуется считать 4096/512=8 страниц.
Прелесть данного решения в том, что при чтении можно получить данные быстрее, чем будет считана одна страница NAND. Как было показано ранее, скорость считывания страницы около 27 Мбайт/сек или примерно 75 мксек. Если нужная информация находится в начале страницы, то для получения данных потребуется пропорционально меньшее время. С учетом задержек на выдачу команд, адреса и ожидания готовности это будет меньше, конечно, хоть и не в 8 раз.
Впрочем, вряд ли система будет позднее вычитывать данные, которые были на странице, но в ранних адресах, поэтому условие "если нужная" в предложении можно опустить.
Проблема возникнет при попытке записи по такой технологии. "These MLC NAND Flash devices do not support partial-page programming operations". Хороший подарок. Не то, чтобы непреодолимая проблема, но она есть. Вернемся к ней в разделе 'Запись'.
2. Страница-чередование.
Данный вариант мало отличается от предыдущего, кроме одного - размер блока чередования равен размеру страницы NAND, который обычно составляет 2 или 4 Кбайт.
При чтении первые данные будут получены через 75 мкс, последующие через меньшие промежутки времени из-за конвейеризации запросов буферизированного чтения.
3. Блок-чередование.
Если есть вероятность использования чередования маленькими блоками, то почему надо исключать чередование блоками, превышающими размер страницы или 4 Кб, (вроде бы) любимой операционными системами Windows? Блок стирания в NAND порядка 256-512 Кб. А что, даже в современных 'внешних', не встроенных, контроллерах RAID(0) используются близкие к такой величине рекомендации по выбору Stripe. Первая же мысль, которая закрадывается после прочтения данного предположения - ну это же бред. Просто так терять производительность - глупость полнейшая!
Однако позволю себе наглость обратить ваше внимание, что отдельные типы SSD существенно, буквально 'в разы', ускоряются при множественном режиме чтения (многопоточный доступ, AHCI). Это как раз и происходило бы при очень большом блоке чередования.
4. Без чередования.
По функциональности и внешним проявлениям очень напоминает режим 'страница-чередование', описанный выше. При этом будут выполняться практически такие же действия по считыванию и сохранению. Единственное отличие – размер доступа, когда переписывается весь блок, будет соответствовать размеру страницы. При наличии чередования эта величина в два раза больше. Впрочем, SSD обязан нормально работать с блоками 512 байт, что меньше размера страницы, поэтому возросший размер блока из-за чередования не существенен.
Если для носителей информации типа HDD нет особой принципиальной разницы в операциях ‘чтения’ и ‘записи’, то с SSD всё гораздо неприятнее. Здесь присутствуют два, даже скорее три, неприятных фактора - записывать можно только в стертую страницу и только ее целиком, стирается только куча страниц сразу (блок), да и сами процессы стирания и записи деструктивны - растет дефектность в градациях уровней ячеек, что снижает надежность хранения информации. Количество циклов MLC ячеек весьма невелико и составляет всего несколько тысяч циклов.
По технологиям SSD ходят только слухи, но все они совпадают в двух тезисах:
При добавлении данных они пишутся в массив свободных страниц.
Для ассоциации логического номера сектора и действительного места на NAND используется транслятор - таблица соответствия.
Иначе говоря, при поступлении измененных данных контроллер будет записывать не туда (не по тому адресу), где они располагались ранее, а в пул свободных страниц. Если вы десять раз переписали один и тот же файл, то, на самом деле, контроллер записал этот файл десять раз в свободное место на диске, каждый раз корректируя транслятор так, чтобы по логическим адресам 'снаружи' SSD читалась последняя копия файла. Такой нехитрый прием позволяет снизить вероятность неравномерной выработки NAND.
Итак, продолжим гадание, оно становится всё интереснее и интереснее.
У любого нормального контроллера SSD есть большая буферная память для временного хранения считанных данных и того, что надо (бы) записать. При получении данных на запись контроллер не станет сразу начинать процедуру записи в накопительную матрицу NAND. Все хитрее - контроллер будет стараться собрать последовательные запросы в блоки. По мере заполнения буферной памяти контроллер должен выбирать запросы с соседними адресами и отправлять их на запись. Попутно, он должен стирать неиспользуемые блоки NAND, и это важный момент, но пока опустим.
Итак, надо записывать. Тип чередования может различаться, но общая идеология сохраняется неизменной - надо записать несколько страниц данных, причем в разные LUN. Наверно, у Вас сразу возник вопрос - почему же обязательно 'в разные'? Да очень просто - нельзя организовать параллельное чтение из одного LUN! Конечно, в одном LUN есть две плоскости, но - смотрите числа, приведенные выше на презентации Micron - прям уж "в два раза" применение двух плоскостей не дает. Гм, может, поэтому у микросхем NAND фирмы Intel нет разделения на плоскости? Впрочем, не суть.
Иначе говоря, для получения высокой скорости чтения, именно чтения, надо записывать в разные LUN. Скорость записи и метод разбивки по LUN здесь не столь и важен, ведь сама запись выполняется в 'невидимом' режиме из-за применения буферизации в контроллере SSD, да и сами скорости записи существенно ниже требуемых скоростей чтения (из-за особенности работы NAND).
Итак, порядок записи в разные LUN выбирается из удобства чтения. Если в контроллере пять каналов, то записывать хорошо бы сразу во все пять микросхем (что означает 5*n LUN) - при чтении получится максимальное быстродействие. Но, простите, если занять все каналы, то до окончания процедуры записи страницы =все= LUN будут заняты и ничего считать не удастся. SSD буквально ‘отключится’. Напоминаю - процедура записи долгая, особенно если перед ней было вызвано стирание - оно-то выполняется еще дольше. Умный контроллер будет чередовать занятость каналов и количество страниц в единовременной процедуре записи. С точки зрения работы устройства последовательность и место расположения данных не важно́ - есть же транслятор, он переставит адреса.
Отметим первый вывод - когда контроллер выполняет массовые операции чтения и записи, разбивка данных по LUN может быть не оптимальной - часть данных одного файла могут попасть в один и тот же LUN. При чтении это 'свалит' параллельность считывания и произойдет падение производительности. Чем больше количества LUN в SSD, тем выше общая производительность записи и тем меньше коллизий попадания в один LUN. Сама процедура записи выполняется гораздо дольше, чем передаются данные для нее, поэтому на один канал можно поместить множество микросхем, и все они будут работать (записывать) практически одновременно.
Наверно, стоит задаться и сопутствующим вопросом - каналы контроллера обязательно синхронны? То есть все каналы полностью одновременно выполняют все операции? Думаю, вы согласитесь, что такой режим работы лишен смысла - не бывает настолько параллельных операций, чтоб все пять каналов могли сейчас записывать, а потом все пять считывать данные, затем все разом переключаются в режим стирания и так далее.
Понятно, что контроллер обычно много читает и иногда записывает, и может записывать пятью каналами ... но не всегда же. Это означает, что при жесткой фиксации произойдет падение производительности от недоиспользования каналов, часть из них будет простаивать. Это предполагает использование контроллером асинхронного режима работы каналов, когда операции на одном из них никак не зависят от загрузки других.
Например, у контроллеров памяти AMD есть два режима работы - синхронный и асинхронный. Если брать 'случайную' программу, без четкого детерминирования, то асинхронный режим немного выигрывает. С NAND эффект должен быть выражен еще ярче. Нас этот момент интересует только в том плане, что процедура 'контроллер начал запись' превращается в 'контроллер ищет свободные каналы и записывает', что также увеличивает риск записи данных в один и тот же LUN.
Очень интересно формируется емкость диска. Для HDD, в виду непревзойденной жадности производителей, емкость считается не в Мбайт, Гбайт или Тбайт, а по степеням десятки.
Общепринятая терминология по отношению к емкости (в байтах) компьютерных величин К-М-Г-Т означает:
К = 2^10=1024
М = К * К = 2^20 = 1024 К = 1048576
Г = М * К = 2^30 = 1024 М = 1073741824
Т = Г * К = 2^40 = 1024 Г = 1099511627776
Если вы где-то увидите надпись "2 Кбайт", то это не может прочитаться иначе, чем 2*1024=2048 байт. Но это мы не можем, а производители дисков могут всё.
На диске написано 1 Тбайт, и думаете, там 1 Тбайт? Отнюдь, там 1000,000,000,000 байт. Разница этого 'лукавства' составляет 1. 0995 раза или около 100 Гбайт. Поставили диск, отформатировали и получили 0.9 Тбайт.
Извините, обращу внимание, это действительно важно! Некоторые тесты возвращают цифры быстродействия в те же "кукурузных" (десятичных) байтах. Запускаешь тест USB Flash, видишь скорость записи 28 Мбайт/сек, что 'со скрипом' проходит декларированные производителем, а потом реальная работа с таким накопителем оказывается не лучше 26 Мбайт/сек. Начинаешь искать ошибку, перестанавливать .... (ну, думаю, всем знакомо) ... а потом читаешь маленькими буквами - скорость указана для 100000...000 байт/секунду. Ну не знаю, кому может доставить удовольствие такая 'мелочь'.
Ну ладно, к нашим баранам. Если с HDD всё ясно, на них можно нарезать сколько угодно данных без четкой привязки к размерности, то в SSD всё иначе - емкость накопительного элемента NAND всегда кратна два в степени n! (с TLC несколько не так, но нам сильно везет – пока их не используют в SSD).
Бытует мнение, что производители прячут часть памяти для отбраковки сбойных страниц. Да, под некондицию надо резервировать место, но не думаю, чтоб столько. У SSD появился транслятор, под него тоже уходит место, как и под различные служебные структуры счетчиков использования, хотя последние могут сохраняться в зоне ECC страницы. 'Исчезает' существенный объем накопителя, но не так же много.
Но это не всё, по мере забивания SSD данными его скорость падает. Рекомендуется оставлять свободной не менее 1/4 емкости SSD (и это при его сумасшедшей цене за Мбайт), а лучше половину (!) диска. Иначе может наступить деградация свойств. Вы привыкли всё свалить на HDD и забыть? С SSD такое не пройдет. Свалили на него ненужный хлам - оставили мало места - SSD упадет в 'я никакой'.
Что за феномен, и как оно лечится?? Четкого ответа нет, можно только предполагать.
Запись информации производится в пул чистых страниц, но чем меньше свободного места, тем меньше сам пул и чаще приходится перетрясывать систему для поиска незанятых страниц и их группировки к последующей очистке (стереть можно только блок страниц). Как хорошо, если диск полупустой - пришла команда записи, пихнул команды в нужные LUN и дальше, на фоновом процессе, неторопливо ищешь ненужное и потихоньку стираешь. Когда свободной памяти нет, то придется писать 'что уж есть' и 'куда уж есть'. Тут уж данные раскидываются а-бы-как, и об оптимизации чтения приходится просто забыть.
Кроме того, я с ужасом думаю про транслятор. Есть вероятность, что он начинает принимать сложную древовидную структуру, что также увеличивает затраты на чтение из-за трудностей с получением целевого списка страниц. Конечно, всё зависит от конкретной реализации программного обеспечения SSD, но проблема общая.
Для нормализации работы SSD применяются программные надстройки между операционной системой и диском – TRIM (информация о незанятых секторах файловой системы) и Garbage Collection (сборка мусора). Об этих технологиях сказано много, поэтому специально останавливаться на них не стоит. Суть их примерно одинакова - объяснить SSD, где что и как ему надо вычистить в своей матрице для освобождения монотонного (непрерывного) пула страниц. И чем меньше свободного места на диске, тем чаще придется выполнять чистку, да и сама чистка будет не слишком 'чистой'.
Да, у SSD свои болячки, Вы не знали?
Так что, я не склонен считать 'жадностью' производителей то, что они прячут часть емкости SSD. Она не пропадет, ведь смысл ее использования весьма прозрачен и прямо сказывается на производительности и времени работы SSD. Ведь, чем чаще 'перетрясывается' SSD для упорядочения страниц и выравнивания нагрузки, тем больше записи производится.
Данный раздел хотелось бы посвятить вопросам общепринятых методик тестирования дисковых накопителей. Дело в том, что автор исследования подразумевает одно, а аппаратура совсем другое, и подчас выходят такие казусы ...
Реализация тестов в разных программах при одинаковых или похожих названиях может несколько различаться, но будем ориентироваться на 'типичные' реализации. Итак, начнем.
Алгоритм действий состоит в установке позиционера на фиксированную дорожку, чаще всего начало диска, с последующим чтением последовательно расположенных секторов данных. Само чтение выполняется запросом считывания блока переменного размера, при этом измеряется время выполнения данной операции (чтение блока).
Деструктивными моментами, сказывающимися на времени выполнения, является смена поверхности и номера дорожки. Кроме того, у ряда производителей, после окончания чтения одной дорожки следует переход на следующую, вместо (вроде бы очевидной) смены стороны или номера диска. Тесты могут учитывать наличие этих дефектов и удалять их из результатов, или не делать этого и надеяться на них малозначимость в итоговом числе.
Программы, работающие через скрипты, вряд ли учитывают эти дефекты в виду своей универсальности, а по нескриптовым вообще ничего сказать нельзя - не дизассемблировать же.
Что же подразумевает данный алгоритм и что происходит в действительности?
Предполагается, что длительное последовательное чтение одним блоком чтения (скажем 4 Кбайт) вызовет в дисковом накопителе те же действия, что и чтение одного единственного блока такого размера. Если не лезть в логику работы устройства, то алгоритм работы теста верен. Но, простите, современные, да и не только современные, а банально 'старые', накопители уже давно обладают расширенной системой кэширования! "Расширенность" связана с различного рода группированием данных для лучшего использования. А это означает, что лезть в логику придется и, боюсь, логика неверна. Статья рассматривает работу довольно разнотипных устройств, HDD и SSD, поэтому и рассуждения будут отдельно по каждому из них.
HDD.
При запросе чтения первого блока из последовательности, HDD выполнит массу действий, напрямую к чтению не относящихся - надо дождаться очереди на выполнение этой операции, потом долго, нудно и старательно передвигать позиционер до нужной дорожки. При этом в буферную память попадет некоторое количество считанных данных, которые контроллер может прочитать и сохранить 'от нечего делать', пока ждет нужный сектор. Увы, HDD - устройство непрямого доступа и нельзя прямо начать выполнение операции - хочешь или не хочешь, а придется ‘сидеть и ждать’, пока нужный сектор не покажется под головкой чтения. Конечно, можно применить в HDD тот же транслятор, что используется в SSD, что позволит раскидывать сектора 'а-бы-как', но ... лучше сразу забыть про такую глупость.
Технологии HDD тем и хороши, что они просты. С момента выхода первого IDE накопителя мало что изменилось - всё та же секторная запись с однозначным соответствием номеру сектора и его расположением на диске. Революционные изменения прошли на ином уровне - в логике работы устройства, конструкционных разработках поверхности дисков и магнитных головок.
Если опустить лирику, то на момент считывания целевого сектора в буфере HDD уже содержится (точнее 'может', примечание переводчика) значительный фрагмент данных до данного сектора. После считывания нужного сектора HDD обязательно будет вычитывать некоторое количество секторов, даже если запроса на последующие сектора (пока) нет в очереди выполнения.
Причина и доказательство тезиса в том, что при отсутствии кэширования чтения будет теряться следующий сектор, что потребует дополнительного оборота диска (порядка 5-10 мсек) и это будет хорошо заметно по увеличению времени доступа к диску. А именно, раз этого возрастания нет – значит, все HDD выполняют кэширование чтения. На сколько вычитывает контроллер? Сложно сказать, бытует мнение, что считывается вся дорожка целиком, но у меня есть сомнение по столь 'экстремистскому' предположению.
Ладно, экстрим или нет, но после считывания начального блока бо́льшая часть дорожки уже находится (или, настоящее время, станет находиться) в буферной памяти контроллера.
Второй запрос блока не заставит контроллер что-то считывать, он просто возьмет данные из буферной памяти. Третий и последующие - аналогично. Конечно, размер дорожки не бесконечен (легко считается как скорость считывания данных, деленная на скорость вращения диска), порядка 1 Мб. После считывания такого объема информации будет производиться смена поверхности, что означает затраты времени на переключение головок в коммутаторе (несущественное время) или перемещение блока магнитных головок на соседнюю дорожку. После смены дорожки всё повторится снова – поиск сектора и чтение всех секторов подряд. Дополнительная задержка возникнет только на поиске сектора, в остальных случаях данные будут поступать из буферной памяти.
Итак, тест читает с диска данные с переменным размером блока, причем выполняет это сплошным потоком. Контроллер диска выбирает данные из буферной памяти. Ну и как эти процессы связаны со скоростью чтения блоком 'какого-то' размера? И вообще, с чтением одиночного блока? Если у вас есть другой ответ, кроме как "никак", значит я плохо объяснил или что-то упустил. Извините.
SSD.
Если с HDD всё просто и понятно, то с SSD сплошной туман - в зависимости от конкретной реализации программного обеспечения может быть 'такая' реакция, что останется только чесать в затылке и удивляться. Но, не будем его расчесывать, лысина не украшает, давайте идти от 'нормального' решения.
При получении команды чтения блока контроллер выдаст запрос на получение нужной страницы. Естественно, перед этим он должен построить список требуемых страниц через транслятор и этот момент, несомненно, важен, но пока забудем.
Если используется не байт-чередование, то первые данные будут получены не ранее, чем считается первая страница. А это произойдет не ранее, чем 75 мсек (аргументы по данной цифре были выше). После чего, через небольшие интервалы времени, будут получены другие недостающие страницы для получения затребованного блока чтения из SSD. В принципе, накопительная матрица NAND довольно быстрая и выполнять кэширование чтения для контроллера нет явной необходимости. Так он делает его или нет? Попробуем разобраться.
Если посмотреть статистику по тестам SSD последовательного чтения, то для блока 4 Кбайт скорость чтения колеблется от 40 до 120 Мбайт/сек. При этом стоит сразу вспомнить, что размер страницы NAND равен 2-4 Кбайт (обещают и 8 Кбайт). Для простоты положим, что размер страницы 2 Кбайт, как в отмеченных ранее микросхемах.
При байт-чередовании априори считывается в несколько раз больше информации, чем размер страницы. Для иных режимов обязательно считается страница и, через небольшой интервал времени, вторая страница. Вычитывать дальше у контроллера задачи не стоит, ведь запрошенный объем информации он уже получил из матрицы NAND. Возьмем этот вариант и применим к нашим цифрам - для одной страницы скорость чтения 88 Мбайт/сек. Для двух страниц должно быть лишь чуть больше, порядка 95 Мбайт/сек или около того. Но, в любом случае, меньше 120 Мбайт/сек, которые получаются по тестам. Кроме того, весьма забавно требовать от контроллера SSD, чтобы он каждый раз заново начинал процедуру кэшированного чтения для каждого нового блока, особенно если эти блоки следуют один за другим.
Вообще-то, чтение файла последовательными запросами блоков (по 128 Кбайт) довольно типичная ситуация. Если надо считать файл достаточно большой величины, то Windows рассыпает запросы по 128 Кбайт. Представьте себе, как быстро бы работал SSD, если б он по каждому запросу начинал новое чтение. Напомню - для SSD "как хочешь", но нужен 'разгон' в чтение одной страницы, то есть 75 мсек. Вполне естественно, что SSD будет вычитывать больше данных, чем необходимо, если в его буфере запросов нет явных запросов на эти данные (в режиме AHCI). Причина банальна, старт - стоп процедуры буферизированного чтения довольно длителен по времени, поэтому его лучше делать реже. Парадокс, хоть NAND и не механическая система хранения данных, но свойства механики (инерционность) присущи и ей.
Выходит, что нет никаких проблем с пониманием цифры “120 Мбайт/сек” - SSD вычитывает гораздо больше данных, чем запрошено вначале, поэтому контроллер только первый запрос выдает со скоростью нормального (одиночного) обращения, а все последующие идут через буферную память. М-да, еще одна аналогия с HDD. И, увы, следствие то же - скорость последовательного чтения файла блоком размера N никак не связана со скоростью чтения одиночного маленького файла общим размером N.
Ранее я говорил о байт-чередовании и пропустил такой вариант при выяснении возможного присутствия кэширования чтения. С ним то, как раз очень просто - при байт-чередовании априори считывается много страниц, из которых используется только часть (по длине страницы). Значит, всегда есть упреждающее чтение на несколько страниц. Если SSD использует этот режим работы, то у него всегда есть кэширование чтения.
Но, тогда встречный вопрос - почему происходит снижение скорости чтения при уменьшении блока доступа? Всё просто, на передачу информации от контроллера до процессора уходит какое-то время. Чем длиннее канал, чем больше в нем разнородных устройств и интерфейсов, тем дольше будут перемещаться данные. Обычно, у встроенных в южный мост контроллеров наименьшее время доступа. Вы хотите ускорить работу системы и устанавливаете дополнительный контроллер с расширенной функциональностью... и это неизбежно увеличит задержки. Как следствие, хоть дополнительный контроллер и "умный", но скорость чтения мелких файлов станет меньше, причем зачастую, меньше в несколько раз.
Что хотели: измерить скорость чтения файлов разного размера
Что получили: скорость чтения больших файлов (большой блок доступа) и индикацию времени задержки передачи в канале передачи данных на чтение (маленький блок доступа).
В качестве небольшого 'домашнего задания' попробуйте предположить, что делает SSD при запросе чтения из секторов, которые не определены, то есть в них не проводилась запись и транслятор пуст. (Ответ). Скорость около 150 Мбайт/сек – это действительные данные, а ровная полоска вверху – ‘это самое’. Поэтому тестирование SSD весьма нетривиальное действие и требует серьезной подготовки.
Алгоритм, используемый в данном тесте, повторяет рассмотренное ранее последовательное чтение, только вместо чтения блоков производится их запись.
И HDD, и SSD буферизируют записываемые данные по одной и той же причине - собрать блоки достаточно большого размера.
При редкой записи файлов небольшого размера данные складируются в буферной памяти накопителя и записываются в моменты отсутствия команд. Если объем записываемых данных больше буферной памяти, то накопитель не сможет ничего 'отложить', чтобы осуществить ее в момент простоя, поэтому будет вынужден записывать ‘здесь и сейчас’.
Что хотели: измерить скорость записи файлов разного размера
Что получили: скорость записи больших файлов (большой блок доступа) и индикацию времени задержки передачи в канале передачи данных на запись (маленький блок доступа). Конечно, если не вмешается система кэширования дискового накопителя или Windows.
На накопителе данных, как правило, есть кэш-память под буферизацию данных на запись и кэширование чтения. Раз эта память есть, то можно измерить скорость работы с ней. Для чего можно или использовать специальные команды, или 'как всегда', просто много раз читать один и тот же блок данных - контроллер вряд ли будет считывать с носителя информации одно и то же, если это самое 'оно' уже считано и находится в его буферной памяти.
Старые HDD так и работали - при повторном запросе на чтение того же блока (набора секторов) только в самый первый раз данные считывались с дисков, а все последующие запросы оканчивались буферной памятью. Интересно, что современные HDD, особенно с многоядерным контроллером, SSD и устройства на интерфейсе USB крайне негативно относятся к режиму буферизованного (Burst) чтения.
Теперь, пожалуйста, задайте себе вопрос - как часто операционная система считывает один и тот же набор секторов постоянно? ... Вы верите в обширный склероз с манией преследования?
Вполне очевидно, что данный режим общения с дисковыми накопителями глупость, поэтому программное обеспечение контроллера накопителя не обязано корректно обрабатывать данную несуразность. Нормальные результаты теста - хорошо, плохие - ровным счетом ничего не значат. Во втором варианте, при некотором полете фантазии, можно попробовать расшифровать методику кэширования, используемую контроллером - ведь 'провал' буферизированного чтения означает, что контроллер все же выполняет (или пытается выполнять) повторные операции чтения с накопителя данных и множественные запросы ему мешают, вытесняя кэширование чтения (упреждающее чтение). Но, подобные шаманские действия пока никто не предпринимал и обряд чтения сих иероглифов не описан в летописях.
Хоть тест называется 'буферизованное чтение', но самим буферизированным чтением является 'последовательное чтение' - при нём практически вся информация считывается из буферной памяти. Само же 'буферизованное чтение' не представляет никакого физического смысла. Ну, разве что - померить максимальную пропускную способность интерфейса при больших блоках доступа, да и то, если дисковый накопитель хоть как-то способен выполнять такой вид операций.
Что хотели: измерить скорость получения файлов разного размера из буферной памяти дискового накопителя
Что получили: если функция поддерживается, то – смотреть раздел 'последовательное чтение' - скорость интерфейса при больших блоках и индикацию времени задержки передачи в канале передачи данных (маленький блок доступа). Повторюсь, если функция не поддерживается, то это ровным счетом ничего не значит - ну зачем собаке пятая нога?
Всё то же, всё так же. На дисковый накопитель высылается команда записи одного и того же блока данных. При этом контроллер просто тихо дуреет от подобного склероза операционной системы, да еще в столь запущенной форме и интенсивности.
Данный режим не встречается в нормально работающем компьютере, а потому носитель информации не обязан корректно обрабатывать такую, извините, глупость.
Старые HDD все же нормально выполняют данный вид операций, новые и SSD - как получится. А если не получится, то и не надо.
Что хотели: измерить скорость получения файлов разного размера из буферной памяти дискового накопителя
Что получили: смотреть 'буферизированное чтение'. Глупость получили.
Одна из главных и самая понятная характеристика дискового накопителя - это скорость чтения и записи данных. Если с другими характеристиками много тумана (ну посудите сами, как можно быстро и понятно интерпретировать среднее время доступа к данным или время на смену дорожки), то со скоростью передачи всё просто - записываешь на диск большой файл, и он будет записан за (надо считать) времени. Можно и не считать - скорость современных дисков порядка 100 Мбайт/сек, что означает считывание (или запись) около 100 Мбайт за одну секунду (за 2 секунды 200 Мбайт, за 3 секунды 300 Мбайт и далее).
Одно 'но' - производительность зависит от типа дискового накопителя. Если у SSD эта характеристика зависит (смотрит на потолок) от "погоды на Марсе", то у HDD скорость, по большей мере, зависит от расположения на диске. Если это начало HDD, внешние дорожки, то скорость максимальна. По мере увеличения позиции в HDD положение магнитной головки на дисках смещается к центру, что вызывает уменьшение производительности до двух раз.
Важно здесь то, что тестовые утилиты (обычно) измеряют скорость дисковых накопителей в начале диска, где производительность максимальна. Данный прием как-то оправдан для древних времен, когда одни HDD сравнивались с другими HDD, и еще никто не слышал сокращения "SSD". В HDD применяется зонная структура, когда внешние дорожки получают большее количество более ‘быстрых’ секторов данных. По мере приближения к концу диска количество секторов на дорожке уменьшается. На диске множество зон с разной производительностью. Так вот, раз тестовые утилиты проводят измерения в самом начале диска, буквально в нулевой зоне, то некоторые производители добавляют еще одну маленькую зону в самое начало диска и задают на нее максимально-возможную производительность. Тесты покажут высокую скорость, но в реальной работе вы эту скорость не увидите - размер зоны весьма небольшой.
Итак, возьмем HDD со скоростью чтения 120 Мбайт/сек, что получается только на внешних дорожках, и сравним его с посредственным SSD со скоростью чтения 150 Мбайт/сек. Вроде бы паритет производительности? Ан нет! У HDD 120 Мбайт/сек получаются только на внешних дорожках, а на внутренних будет только 60 Мбайт/сек. Никакого "паритета" нет.
Не забывайте об этом лукавстве, когда будете сравнивать дисковые накопители разной природы. Для HDD скорее надо брать среднюю скорость, а никак не максимальную.
А знаете, ничего не хочется говорить.
Для HDD данный тип тестов более-менее реален, а у SSD возможны проблемы из-за потоковости доступа. Дело в том, что контроллер адаптируется под тип нагрузки, а здесь применяется массовый поток по случайным адресам. При этом контроллер должен бы понять, что кэширование чтения вредит и отключить его. На 'понятливость' контроллера уходит какое-то время, поэтому результаты будут не совсем честными.
На диск отправляется поток запросов на чтение (или запись) маленьких блоков, обычно один сектор, 512 байт. Место положения данных выбирается случайно по всей поверхности носителя информации. Фактически, измеряется качество работы позиционера (HDD) или транслятора и предвыборки для SSD.
Вроде бы, тест вполне адекватный, откуда взяться проблемам? Бывают.
При случайном поиске можно каждый последующий адрес выбирать случайно, а можно 'прыгать' между фиксированной позицией и случайным. Лично у меня есть подозрение, что общеизвестный HD Tune применяет второй вариант, поэтому его измерения отличаются от данных других программ.
Кроме того, время доступа определяется не только скоростными характеристиками позиционера, но и принципами приближения магнитной головки на нужную дорожку. Если подвеска HDD неудачна (а классический метод крепления не самый лучший вариант), то вибрация будет вмешиваться в предполагаемые перемещения позиционера, что вызовет увеличение времени. Для SSD проблем с вибрацией нет, но зато существует зависимость между временем отклика и тем, что до этого делал привод.
Одной из важных особенностей SSD является и то, что они могут делать 'что-то еще'. Такого не наблюдается в HDD, ведь принцип их работы весьма прост. Обычно, данный тест выполняется очень долго, чтобы как-то нивелировать систему кэширования в дисковых накопителях, и в контроллере SSD остаются только запросы на чтение (или запись) небольших секторов. Всё, что было ранее 'выталкивается' и игнорируется программами тестирования, как помехи от операционной системы. Но, увы, это ведь не так.
Что хотели: измерить скорость доступа к данным
Что получили: возможны разночтения в алгоритмах измерения времени доступа HDD и полностью рафинированный тест для SSD.
Один из самых сложных вопросов. Много копий было сломано, но вопрос так и остается и на том же месте. С одной стороны, операционная система пытается загружать системные файлы в многопоточном режиме, с другой - в приложениях пользователя многопоточности нет. Ну откуда ей взяться, если любая программа работает по принципу загрузил - посчитал - записал.
Причем здесь многопоточность? Функция "загрузил" сложная по своей сути, ведь исходный файл надо расшифровать, а делать это множеством потоков крайне затруднительно. Конечно, если программа работает в пакетном режиме, то обработку каждого файла можно разнести в независимый поток, тогда множество однопоточных доступов превратиться в один многопоточный. И часто вы конвертируете картинки в пакетном режиме? … и при этом программа действительно распараллеливает выполнение множества заданий?
При множественном доступе HDD теряют производительность, сказывается инерционность позиционера. Что до SSD, то их производительность только возрастает. Причем, ускорение может быть очень-очень большим. Насколько оправдано такое тестирование для домашнего применения? ... лично я сомневаюсь.
Хотя многопоточность чтения может присутствовать и в домашней области применения - игровые движки в силах разнести задание на загрузку примитивов в несколько потоков, но многопоточная запись в обычных приложениях крайне маловероятна.
Впрочем, извините за вульгарное сравнение - если до сих пор некоторые игры не поддерживают больше одного процессора (ядра), то довольно странно думать, что в них реализована многопоточная загрузка. Увы, детально вопрос не исследован, поэтому поставим жирный знак вопроса и перейдем к следующей проблеме.
И по этому вопросу много мифов. Ну, добавим свои.
В качестве инструмента я использовал HAB, поэтому не могу гарантировать 100%-ной точности измерений, но я им доверяю. Замеры производились в операционной системе Windows 7 х86 для двух компьютеров примерно одинаковой конфигурации (процессор 2-4 ядра, системная память – четыре гигабайта).
Конкретная конфигурация, какие именно HDD применялись - не столь и важно, SSD не использовались.
Общая статистика для игр и фильмов.
За время снятия лога компьютер использовался только для игр и просмотра фильмов.
Программа весьма неудачно показывает количественный спектр размеров блока доступа, потому необходимы пояснения. Извините, программа написана не для сбора статистики, просто так вышло.
В левой части картинки три раздела – низкоскоростные, высокоскоростные файловые операции и операции через отображение файлов на память (Mapping).
С первыми двумя режимами понятно - если файловые операции идут медленно, то результаты попадают в верхний раздел, если быстро, то в средний. Режим отображения (Mapping) не совсем обычный и стоит привести небольшие разъяснения.
Если программе надо получить информацию из файла, то ей придется выполнить ряд действий:
Это довольно долгий и хлопотный процесс. Существует более удобная технология - файл можно отобразить в память приложения. Для этого в свободном диапазоне виртуального пространства выделяется окно и в него ассоциируется файл. Никаких упреждающих чтений не производится. Программе для получения данных из файла достаточно просто прочитать по соответствующему адресу из выделенного окна. При этом операционная система получит ошибку отсутствия страницы и подгрузит данные из файла в окно приложения (выделит небольшой блок памяти и считает туда соответствующий фрагмент файла).
Согласитесь, это очень удобно! Увы, кроме удобства есть и недостаток - максимально видимый размер файла, который может быть открыт через отображение, ограничен размером виртуального окна процесса, и не более 2 Гбайт на один файл. Одна из игр, которая использует только отображение файлов, это S.T.A.L.K.E.R. ... теперь вы можете понять, почему данная игра так любит большой размер своего виртуального адресного пространства - из-за отображения. Уфф. Вообще-то, именно ради S.T.A.L.K.E.R. в программу и добавлена индикация отображения, а то выходила глупость - игру запустил, но программа показывает отсутствие дисковой активности. Мило?
По числам в табличках, надеюсь, особых трудностей нет - показывается время выполнения и объем операций; минимальный, максимальный и средний размер блока доступа.
На рисунке справа отображается количество операций с разными размерами блоков. Да решение неудачное, извините. Каждый столбик соответствует своему размеру блока - левый 1 Кбайт (и меньше), второй 2 Кбайт, третий 4 Кбайт .... последний 32 Мбайт (и больше).
Давайте всё же вернемся к нашим баранам.
Напомню - компьютер использовался только для игр и просмотра фильмов стандартной размерности через Media Player Classic.
Первое, что бросается в глаза - операционная система 'постоянно' читала мелкие файлы длиной 1-2 Кбайт. Отчасти, низкоскоростное чтение настолько мелких файлов (скорее фрагментов) вызвано работой программы просмотра фильмов, но не все же 40 часов из 100. С одной стороны это непонятно, с другой - разве это большая нагрузка для современной дисковой системы?
Для высокоскоростного обмена характерно чтение блоком 2 Кбайт и запись 512 Кбайт. Причем, записывалось довольно много, 83 Гбайт. Сложно сказать, откуда столько взялось, может что-то переписывал по сети. Впрочем, да, именно так - перегонял файлы через VirtualDub с сети на свой компьютер, за это говорит размер блока доступа - в свойствах программы VirtualDub выставлено записывать блоками по 512 Кбайт.
Для режима отображения свойственно чтение блоками 128 Кбайт и более. Причем, если перейти от количества запросов к объему переданных данных, то средний блок чтения составит 2 Мбайт.
Записи в режиме отображения практически не было.
Вполне очевидно, что это "среднебольничная" температура. Информация полезна, но хочется чего-то конкретного. Что можно на себе примерить и сказать 'вранье'. Сейчас будет.
Возьмем игру Borderlands. Она базируется на Unreal Engine, поэтому результаты не являются столь уж уникальными.
Наверно, лучше привести две статистики – загрузки игры (вместе с вступительными роликами) и самого процесса игры.
Если посмотреть бегло, то никаких существенных отличий между ними нет. Всё тот же поток постоянного низкоскоростного чтения файлов 1 Кбайт, отсутствие каких-либо операций записи. Режим отображения показывает чтение блоками не менее 128 Кбайт и средним порядка 3-8 Мбайт.
Во время игры почти половину времени дисковая система неторопливо читала мелкие файлы длиной 1 Кбайт (или менее) и, примерно, 1/8 времени операционная система загружала отображение. Последний тип операций выполнялся очень большими блоками.
Давайте перейдем к другому компьютеру ... нет, одна игра это не показатель. Надо расширить, ну хоть 'что под руку подвернется'.
Serious Sam 2.
Слева загрузка уровня, справа - процесс игры.
Игра красивая, но очень 'легкая'. Загрузка уровня занимает всего 23 секунды при считывании 120 Мбайт данных. При этом из 23 секунд загрузки только восемь производилось чтение данных с HDD. Запомним. Размер блока доступа 32 Кбайт.
Процесс игры также не вызывает большой дисковой активности - за семь минут игрового времени было считано всего 100 Мбайт в течение четырех секунд. Вполне вероятно, что вклад в эту цифру внесла фоновая активность операционной системы Windows 7 - очень уж она 'неспокойная'.
Надо отметить 'традиционное' низкоскоростное чтение блоком 1 Кбайт.
Singularity.
Как обычно - слева загрузка уровня, справа процесс игры.
В общем и целом поведение очень напоминает предыдущую игру. То же фоновое низкоскоростное чтение, очень быстрая загрузка уровня.
Размер блока чтения вычислить затруднительно, присутствует нормальное распределение от 2 Кбайт до 256 Кбайт при пике 16 Кбайт. Одно можно сказать точно - во время игры происходит подгрузка данных. Считать 1 Гбайт за 160 секунд, при общем игровом времени 9 минут, 'просто так' не получится. В этой игре возможны появления микрофризов (короткие замирания кадра или резкое падение количества кадров в секунду). Впрочем, тестовый прогон с анализом результатов программы FRAPS не показал наличие каких-либо проблем. Это говорит, что с таким типом нагрузки обычный HDD справляется весьма успешно.
Bulletstorm.
Характер поведения напоминает Serious Sam 2. Загрузка быстрая, во время самой игры подгрузка данных практически отсутствует. Блок считывания переменной длины, от 2 Кбайт до 64 Кбайт.
Mass Effect 2.
В этой игре нагрузка на дисковую систему смехотворна. Ну, или мне не повезло с выбором места.
Painkiller: Redemption.
Хоть игра вышла недавно, но представляет старый 'движок' с новыми картами. Нагрузка на дисковую систему соответствующая - мизерная.
Crysis Warhead.
Режим загрузки уровня ведется блоками с большим разбросом величин, что подразумевает индивидуальное считывание частей игры.
В самом процессе игры чего-то необычного не наблюдается, дисковая активность незначительная, фрагменты подгружаются блоками 4-8 Кбайт для высокоскоростного доступа и порядка 1 Кбайт для низкоскоростного.
В статистике присутствует 3 Мб записанных данных. Их источником было три автоматических сохранения по 1 Мб в процессе игры. Интересно, запись велась большими блоками (64 Кбайт и 256 Кбайт), что подразумевает оптимизацию и довольно необычно.
Crysis 2.
Не могу сказать, что принес CryENGINE 3 в игру как игровой движок, но работа с диском и использование памяти явно претерпели изменения к лучшему. Если в Crysis Warhead, для девяти минут игрового времени, было считано 2.3 Гбайта за пять минут дисковой активности, то в Crysis 2, за 23 минуты всего 419 Мбайт. Похоже, этой игре вообще не важна производительность дисковой системы.
И, напоследок, самое сладкое - S.T.A.L.K.E.R.: Зов Припяти.
С загрузкой все логично - эта игра использует режим отображения файлов вместо файловых операций, поэтому большой трафик присутствует только в разделе Mapping. Размер блока при данных операциях большой, от 128 Кбайт до 16 Мбайт при среднем 5 Мбайт. Пока всё красиво, переходим к процессу игры. И тут наступает ОЙ.
В процессе игры происходит большая активность ФАЙЛОВЫХ операций. Ну, так не бывает, не верю. Объяснение данному феноме́ну может быть только одно - загрузку графического окружения разработали одни люди, а то, что делается при самой игре - другие. Один разработчик не будет смешивать разнородный тип обращения для однотипных действий. Если используется file mapping, то он и будет использоваться для всех операций с данными - так проще и удобнее. С точки зрения использования реальной или виртуальной памяти, оба способа: отображение файлов и файловое чтение в блок памяти полностью одинаковы - и там, и там требуется регион памяти одинакового размера.
Правда, стоит отметить, что отображение файлов всё же лучше работает с большими объемами данных, а с маленькими могут быть накладки и файловое чтение может быть эффективнее. Ну, эта игра 'славится' своими микрофризами, поэтому постоянное высокоскоростное чтение во время игрового процесса не вызывает недоумения. Просто так сделано. Ужасно.
О, давайте сделаем прогон официального измерителя производительности фирмы GSC Game World. В нём отсутствуют такие мелкие глупости, как подгрузка уровней и состояния объектов.
Гм, никаких файловых операций не вижу.
Прежде, чем закрыть вопрос игр, хорошо бы взглянуть - насколько стабильна дисковая активность в играх. Статистика показывает общие результаты, но считывание может происходить импульсно, не монотонно. В таком случае мера дефектности будет выше.
Не будем особо распространяться, достаточно двух игр - Crysis Warhead (слева) и S.T.A.L.K.E.R. (справа).
Лог снимался с помощью S&M, поэтому на графиках присутствуют только файловые операции (линия красного цвета, шкала логарифмическая) без дисковых операций в режиме отображения. Для S.T.A.L.K.E.R. этот недостаток проявляется в отсутствии показа дисковой активности при загрузке уровня в самом начале и середине графика.
Ну что, в обоих случаях видно, что интенсивность считывания данных примерно одинакова за все игровое время, что позволяет доверять результатам статистики, приведенным ранее.
Перейдем от игрового компьютера к 'неигровому'.
На нём запускалось обычное, и не совсем, офисное программное обеспечение. На компьютере установлены uTorrent, Opera и довольно быстрый интернет.... что давно стало обычным явлением. Компьютер для работы, игр на нём нет.
Статистика за 273 часа, но компьютер на ночь не выключался, поэтому сюда заложено 2/3 простоя. Torrent работал всё время, но нагрузка от него мизерная - о нём разговор позже.
Если сравнивать с 'игровым' компьютером, то отличия имеются.
Для медленных операций чтения ситуация примерно та же - 15 часов чтения файлов 1 Кбайт, а для медленной записи новое - если в игровом компьютере медленная запись практически отсутствовала, то в этом варианте запись происходит, причем довольно часто, четыре часа общей работы. Размер блока записи напоминает чтение, 1 Кбайт, но присутствуют блоки и большего размера - 2-4-8 Кбайт.
Для быстрых операций как чтения, так и записи, характерен блок доступа 128 Кбайт. Хотя, сам факт, что семь часов происходили быстрые (высокоскоростные) операции чтения настораживает. Может Opera 'помогла'? Интернетом-то пользовались.
По отображению то же, что и ранее - система читала очень большими блоками. Странно, что набралось почти три минуты, когда система записывала в режиме отображения, да еще и блоками по 64 Кбайт.
От общего к частному. Давайте попробуем разобраться с Torrent.
На компьютере установлен клиент uTorrent 2.2 с настройками по умолчанию. Вначале загрузка файла. Левый выполнялся со средней скоростью 4М, правый 5М.
Разница в скоростях обоих вариантов незначительна, а лог снимался два раза для другого - посмотреть повторяемость результатов.
Из существенного - из двух минут работы программы девять секунд производилось медленное чтение (всего порядка 60 Кбайт); быстро, но недолго (2-13 секунд) считывалось 10-85 Мбайт просто огромными блоками (400-600 Кбайт) и записывалось одну минуту в высокоскоростном режиме. В последнем случае блок записи был 1 Мбайт. Чтение через отображение тоже проявило свою активность, куда же без нее. Активность была в течение одной минуты при среднем размере блока порядка 1 Мбайт. Только не спрашивайте меня, зачем операционная система буферизировала операцию записи, вариантов ответа столько, что перечислять устанешь. Ну, делала и всё, примем как должное. Всё равно изменить ничего нельзя (ага, выключить файл подкачки. Примечание переводчика).
Загрузка была, теперь раздача. Слева 300К, справа 2М.
Если забыть про низкоскоростной обмен, что совсем 'мелочь', то выходит следующая картина - uTorrent читает блоками 128 Кбайт. Второе - при раздаче 'что-то' пишется на диск. Для первого случая за шесть минут было записано 3.3 Мбайт и роздано 120 Мбайт. Для второго - 14 Мбайт за полчаса и раздачи 4.8 Гбайт данных. Похоже, uTorrent пишет на диск каждые 15 секунд блок данных 128 Кбайт вне зависимости от скорости раздачи данных. Этот вид статистики не может показать, производится ли подобная активность при приеме данных, ведь тип и место записи отдельных операций статистики не разделяются.
Если говорить о программах, которые изначально ориентированы на высокое использование дисковой системы, то, как правило, в них применяются специальные меры по увеличению блока доступа для снижения нагрузки. Например, VirtualDub (перекодирование видеоконтента) считывает блоками 128 Кбайт и записывает 512 Кбайт при использовании специальных временных буферов - всё это настраивается в свойствах программы.
Что до 'фирменных' программ типа Photoshop, то в них возможно всякое и логическому осмыслению не подлежит. У пользователя всё равно нет выбора, будет работать с тем, что есть.
В предыдущем разделе вы видели, что дисковая система работает с высокой нагрузкой довольно редко и не слишком долго.
Это означает микро-паузы в работе. У обоих типов дисковых накопителей, и у HDD, и у SSD, используется режим отложенной записи. Если есть пауза в работе и присутствуют несохраненные данные, то накопитель выполнит их запись. С точки зрения операционной системы это произойдет совершенно незаметно. Давайте уточним - выполнение команды записи кэшированное, то есть дисковый накопитель сразу возвращает признак 'выполнено' и действительное выполнение записи можно почувствовать только по 'странной' задержке или падению скорости выполнения команд чтения. Если есть пауза в работе, то запись будет выполнена в этот момент времени и очередь команд на чтение не пострадает, ведь она была пустой.
Кроме отложенной записи, HDD может выполнять предвыборку типично используемых данных. Не слишком известный факт, но HDD некоторых фирм знают о типе файловой системы на диске. Узнать это нетрудно, достаточно прочитать нулевой сектор и разобрать очень простую структуру разделов диска.
Как HDD может использовать эти данные? Загадка за семью печатями. У каждого типа файловой системы свои особенности. Для операционных систем Windows самой любимой является NTFS с ее журналированием и стремлением упихивать мелкие файлы в MFT. Первое означает постоянный (и довольно глупый) поток записей журналирования, которые можно слегка 'покэшировать' с снижением объема реально выполняемых операций. А второе - частую модификацию отдельных секторов данных, которые были считаны совсем недавно. При добавлении незначительных по объему данных в MFT они дописываются к последней структуре (в конец, в середину, куда выйдет).
При этом не производится никакого выравнивания на границу сектора. Если бы выравнивание производилось, то терялся бы смысл записи в MFT. Но, если новые данные не выровнены, то это обязывает предварительно считать текущее содержимое сектора перед его записью. Вполне очевидно, что подобный тип деятельности тщательно кэшируется в Windows, но память под кэш когда-нибудь закончится или ‘отберется’ программой пользователя. Особенно это 'любят' HDD с AF (сектором 4 Кбайта).
Интересно, когда SSD научатся сами понимать файловую систему? Если уж даже HDD как-то используют эти знания, то в SSD это позволит избавиться от всяких TRIM-ов и GC. Да и транслятор можно сделать проще, хотя – это точно 'размечтался'.
Если взять SSD, то у него более сложная внутренняя структура и при паузах ему сразу найдется что делать. Кроме обозначенной ранее отложенной записи, SSD должен (бы) выполнять фоновую сборку мусора, балансировку использования блоков NAND - анализ статистики и освобождение наименее использованных страниц, упорядочение служебных структур диска. Кроме того, может производиться кэширование чтения - вычитывание в кэш-память данных, которые могут потребоваться впоследствии. Режим предсказания и автонастройки на тип выполняемых команд свойственен современной аппаратуре и есть шанс, что этот прием распространился и в топологии SSD, благо признаки этого отмечаются.
При тестировании быстродействия дискового накопителя на него создается сплошной поток команд, без каких-либо пауз. Насколько данный прием справедлив? Если вспомнить статистику, приведенную выше, то может быть только один вывод - при работе приложений дисковая активность не постоянна. Даже при загрузке игр процент использования дисковой системы далеко не 100%. Вполне понятно, что если суть работы приложения в переписывании файла с одного диска на другой, то особых пауз там не наблюдается, но насколько часто вы пользуетесь такими приложениями?
Ну, хорошо, почему же тесты не желают вставлять паузы в последовательность дисковых команд? Это же уменьшит "синтетичность" исследований и даст более адекватные результаты. Увы, не все так легко.
Паузы добавить просто, но как потом их учитывать? Например, выдали команду записи с последующим простоем. В какой момент считать задание выполненным? Если с HDD бо́льшую часть времени осуществляется позиционирование на нужную дорожку, для маленьких файлов, то в SSD вообще что-то трудно предсказать - очень уж много зависит от того, чем до этого занимался контроллер. А раз трудно предсказать время операции, то - как отделить от нее дополнительную паузу, которую специально добавили в тест? Короче говоря, если с операциями чтения какой-то слабодостоверный результат и можно получить, то с записью и ее отложенным кэшированием всё 'глухо'.
С домашним компьютером вроде бы всё совсем не ясно, а как быть с серверным использованием дисковых накопителей?
Понятно, что есть модели типа Database, Webserver, Fileserver, но что они значат? На диск посылается сплошная очередь заданий на чтение и запись. Нормально? Ну, давайте начнем с конца - если сервер работает с 100 %-ной загрузкой дисковой системы, то это мертвый сервер. Его производительность уже совсем 'никакая' и его клиенты будут в бешеном восторге.
Вообще-то, загрузка дисковой системы может быть большой, но не долго. Иначе сервер в помойку. Кроме того, при тестировании серверного применения дисков, используют сценарии при довольно существенном и большом проценте операций записи в общем трафике. Я с трудом представляю такой 'черный ящик', называемый сервером, и в котором процент операций записи более, ну скажем, тридцати процентов. Да еще и при большой многопоточности. Единственное, что приходит на ум из задач с присутствием записи - это кэширующий диск для потокового вещания. Но и тут количество потоков записи несопоставимо меньше количества подключаемых клиентов.
Довольно интересный тест. Конечно, до SYSmark не дотягивает, в нем нет пауз. А потому "сферический конь", зато красивый.
Возьмем несколько дисков и посмотрим. Детального тестирования в рамках этой статьи проводить не стоит, и так уже много всякого. Но так, пройдемся по ключевым точкам. Жаль, что нет передовых SSD дисков... ну, что есть.
Участники забега:
Вполне очевидно, что с SSD, даже с таким 'богом забытым', соревноваться бесполезно. Но почему привод 7200 Western Digital Black был быстрее 10k Western Digital VelociRaptor в тесте 'Windows Media Center'? Догадок может быть много, сразу вспоминается два ядра у контроллера WD Black, но не будем отвлекаться.
PCMark Vantage измеритель производительности интересный, но не более того, коль скоро в нем сплошная синтетика. Увы. Можно заметить какие-то аномалии в проколы в производительности, но как сие перенести на реальные приложения пользователя?
В операционных системах Windows последних поколений - Vista и 7 - есть элементы и технологии для ускорения работы с дисковыми накопителями.
Это ReadyBoost® и SuperFetch®. Первое позволяет загрузить во внешний носитель (USB Flash) часто используемые файлы, что снижает время их загрузки. Уменьшение времени вызвано упорядоченным расположением файлов и отсутствием механических деталей у такого типа носителей. Второе - сверхактивное использование системной памяти для кэширования файловых операций. В SuperFetch несколько иначе понимают системную память - она используется как кэш дисковой системы. При этом если программе потребовалась оперативная память, то ей назначаются страницы в файле подкачки без выделения самой памяти и каких-либо действий со страницами файла подкачки.
Короче говоря, память для Windows - это место на диске и всё основано на кэшировании работы дисковой системы. Если в операционных системах предыдущего поколения процент занятости памяти показывал осмысленную информацию, то в Vista/7 этот индикатор особого смысла не несет - кэширование диска включает и выделяемую память. Кроме того, при нехватке системной памяти весь кэш может быть безболезненно удалён операционной системой, а после освобождения памяти, по окончанию работы приложения, SuperFetch начнет заново собирать в ненужной уже системной памяти кэш часто используемых файлов.
Внешне эта деятельность проявляется в 'странной' дисковой активности после выхода из приложения, по привычке ассоциируемая с нехваткой системной памяти из-за обмена данными с файлом подкачки, что вызывает у пользователя желание установки большего количества памяти. Увы, вложенные средства не окупятся, сохранился ли кэш SuperFetch или нет, заметить трудно – его эффективность проявится при повторном запуске программы. И часто вы запускаете небольшие программы, да еще и такие, которые долго загружаются с большой дисковой активностью, на современных дисках?
Программа eBoostr позволяет выполнять действия, аналогичные ReadyBoost и SuperFetch, и работает на Windows не только семейства Vista/7, что позволяет получить ускорение диска даже в "старенькой" Windows XP. Впрочем, программа и позиционировалась изначально как ReadyBoost for Windows XP.
Зачем я упомянул о ней? У SSD есть одно достоинство и один недостаток - очень высокая скорость чтения с маленьким временем поиска и ... безобразная запись. Не столько сам механизм записи, сколько небольшой ресурс NAND и довольно небольшая скорость. Причем, чем дальше в лес, чем более тонкий техпроцесс NAND, тем ресурс будет меньше и меньше. Эта безрадостная картина объясняется тем, что в одной ячейке Flash носителем информации и так уже является ‘счетное’ количество электронов, а будет еще меньше. Интересно, а как у NAND с радиационной стойкостью? Естественный фон никуда не делся, а гамма-излучение легко проходит сквозь корпус микросхемы и может изменить заряд ячейки.
Впрочем, отвлекся. Как бы использовать SSD, чтобы объем записи на него был поменьше?
Можно использовать EWF (Enhanced Write Filter), что позволяет полностью исключить запись на SSD. Но цена этого ... нет, спасибо, не хочется. К слову сказать - EWF можно поставить не только на Windows XP, но и на последнии версии операционной системы Windows, только вам потребуется встраиваемая (Embedded) редакция Windows 7.
Второй вариант 'нестандартного' применения SSD - кэширование дисков. Не думаю, что вы готовы собирать аппаратуру в соответствии с требованием программы maxiq, поэтому про данный способ лучше сразу забыть.
Третий вариант - применить eBoostr.
Данная программа свою функцию выполняет, но ничего сверхнеобычного не ждите. Да, она поможет в 2-3 раза быстрее запустить приложение в первый раз, но все последующие будут производиться из кэша диска операционной системы. Хотя, то же верно и для обычных HDD и SSD. Эффективность работы программы, по ее собственной статистике, составляет 20-60 процентов в зависимости от того, как часто меняются программы на компьютере.
Еще одной особенностью программы является возможность сбора ‘псевдо’ дискового массива - eBoostr позволяет создавать кэш-файл на нескольких физических дисках и при запросе считывать данные одновременно со всех дисков массива.
Стоит ли специально покупать SSD именно для его работы в eBoostr? Сложно сказать, наверно нет. Для точного ответа требуется детальное тестирование. На просторах интернета проводили сравнение эффективности eBoostr с ReadyBoost и результаты не однозначны, хоть и в пользу eBoostr. Прямой перенос исследований, проводимых в интернете, на компьютер с другой конфигурацией невозможен. Значит, стоит провести свою проверку.
В состав eBoostr входит программа измерения скорости первого запуска выбранного приложения. Воспользуемся любезностью разработчиков программы.
Для начала, общий тест производительности в eBoostr:
В три раза быстрее. Довольно много, но как это феноменальное ускорение проявится во времени запуска реальных приложений?
В таблице указано время прямого доступа, без кэширования, время с кэшированием, процент использования кэш-файла на SSD и эффективность от использования eBoostr. Время указывается за пять запусков теста, поэтому не пугайтесь большим числам.
| Программа | Номер запуска теста | Время прямого доступа, сек | Время доступа через кэш, сек | Использование кэша, % | Эффективность |
| Media Player Classic HC x86 | 1 | 3.63 | 3.21 | 90 | 1.13 |
| 2 | 7.1 | 7.3 | 92 | 0.97 | |
| 3 | 13.14 | 9.83 | 90 | 1.34 | |
| 4 | 10.94 | 8.67 | 88 | 1.26 | |
| 5 | 11.87 | 9.13 | 89 | 1.3 | |
| Windows Media Player | 1 | 21.65 | 18.44 | 71 | 1.17 |
| 2 | 18.38 | 18.22 | 72 | 1.01 | |
| 3 | 19.61 | 17.4 | 72 | 1.12 | |
| Windows Photo Viewer | 1 | 3.25 | 2.42 | 71 | 1.34 |
| 2 | 3.95 | 3.03 | 67 | 1.3 | |
| 3 | 3.92 | 2.89 | 72 | 1.36 | |
| Internet Explorer | 1 | 18.41 | 20.61 | 66 | 0.89 |
| 2 | 19.87 | 19.25 | 74 | 1.03 | |
| 3 | 15.73 | 16.61 | 73 | 0.95 | |
| Офис XP, WinWord | 1 | 13.26 | 12.57 | 7(*) | 1.05 |
| 2 | 10.86 | 8.10 | 95 | 1.34 | |
| 3 | 11.14 | 8.49 | 95 | 1.31 | |
| Офис XP, Excel | 1 | 8.8 | 8.18 | 93 | 1.08 |
| 2 | 12.76 | 9.08 | 93 | 1.41 | |
| 3 | 9.89 | 7.11 | 93 | 1.39 | |
| Офис XP, Outlook | 1 | 17.07 | 14.35 | 93 | 1.19 |
| 2 | 12.4 | 11.14 | 94 | 1.11 | |
| 3 | 13.32 | 9.11 | 93 | 1.46 |
Файловая система NTFS позволяет хранить файлы в сжатом виде. Степень компрессии не очень высокая и не может проявить себя на файлах мультимедиа (сжатый звук, видео), но большинство файлов в современном компьютере сжимаются весьма пристойно. Если вы думаете, что компрессию включают исключительно ради экономии места, то это заблуждение.
Да, сжимание файлов экономит место, но еще и повышает производительность дисковой системы, ведь придется считывать меньший объем данных. Дополнительные затраты на распаковку незначительны и уже для 486-го компьютера расход процессорного времени на декомпрессию был меньше, чем разница времен считывания обычного файла и его сжатой версии. По экономии места вспоминается такое древнее сравнение - при установке Windows NT с настройкой компрессии системного диска, на него удается записать больше данных, чем на обычный несжатый диск без установленного Windows NT.
Чтобы не возвращаться, рекомендация по включению компрессии системного диска для Windows 7:
| При загрузке нажать F8, попадем в меню, выбрать "восстановление загрузки системы", войти в систему и выполнить следующую последовательность команд: X:\Windows\System32\>cd c:\Windows\System32\ X:\Windows\System32\>c: C:\Windows\System32\>compact /c /a /i /s:c:\ Подробнее в нашей Конференции. |
Для HDD вопрос разумности включения компрессии уже многократно рассмотрен в просторах интернета и интереса не представляет. Понятно, что ускорение небольшое, экономия дискового пространства давно неактуальна и связываться с 'экзотикой' нет никакой нужды. Но это HDD, а вот у SSD свои приоритеты.
Начнем с основного. В спецификации ряда SSD указывается скорость чтения/записи порядка 285/275 Мбайт/сек (чтение/запись). У SSD Intel та же формула выглядит как 230/70. Отсюда следует, что продукция Intel медленнее? Ну да, конечно.
В таких 'умных' SSD применяется компрессия данных, аналогичная подобному режиму файловой системы NTFS. Если на такой SSD подавать данные, которые плохо сжимаются, то он покажет далеко не ‘285/275’. Воспользуемся документацией фирмы OCZ - до 285/275 еще ооочень далеко. Кхе, кхе, а откуда же дровишки? Это предположение легко доказывается и иных прочтений нет - в подобных SSD применяется компрессия данных.
Что интересно, тестирование в различных программах может дать и 285/275 и, скажем, 170/35. Всё зависит от программы. Чтобы понять проблему, обратимся к недавней истории – к HDD. Итак, в HDD компрессия не используется и данные записываются в том виде и размере, что приходят в командах записи. Поэтому программам нет какого-то смысла генерировать какие-то специальные шаблоны для тестирования. Обычно, он бывает тривиальным – либо одни нули, либо одни единицы, другие и "необычные" варианты встречаются реже.
Что же произойдет при работе с SSD, у которого включена компрессия? Файлы очень хорошо сожмутся, в несколько раз. Ну, а, коль скоро, размер файла стал меньше, то на его запись (и считывание) придется тратить меньшее время. Плюс к тому, у SSD появляется больше свободного места. Это хорошо? Несомненно, ДА, но есть подводные камни.
Во-первых, сжатые файлы могут обладать большим размером, чем их первоначальный, но это мелочи. Во-вторых, размер файла не соответствует его сжатой версии в SSD, что требует более сложного транслятора. В-третьих, и это уже серьезно, при модификации части файла, буквально 'пары байт' придется производить пережатие нескольких секторов с их последующей перезаписью. Если при этом действии размер данных изменился в бо́льшую сторону и сжатый вариант не уложился в существующее количество секторов, то их число будет увеличено. Проблема даже не в сложных 'телодвижениях' контроллера SSD, а в неэффективном использовании NAND - ведь в вновь добавленном секторе полезную информацию будет нести только ‘пара байт’, а остальное просто пропадет.
Да уж, процедура 'сборки мусора' для таких SSD - далеко не тривиальная операция. Например, у Crucial RealSSD-C300 явно присутствует режим фонового упорядочивания информации. По наблюдениям пользователей таких SSD, сразу после записи могут наблюдаться провалы в скорости чтения, но стоит дать ему спокойно полежать несколько часов (5-10), и эти дефекты исчезают сами собой.
Компрессию можно включить в файловой системе и получить такой же эффект ускорения, при этом не забивая SSD ненужной деятельностью (кстати, 'сборка мусора' явно подразумевает операции по переносу данных, что снижает ресурс накопителя) ... но вот беда, режим компрессии в SSD не отключается.
В компьютерах используются RAID массивы разного типа, но в домашнем вряд ли вы будете использовать что-то, отличное от RAID 0 (Striping, чередование). Впрочем, можно встретить RAID 1 (Mirroring, зеркалирование), но это уже из разряда экзотики. В домашних условиях проще и надежнее переписать особо важные данные на внешний носитель, чем удваивать количество дисков и получать дополнительные проблемы.
С RAID 0 они тоже есть, но его использование замечается сразу и невооруженным взглядом - производительность дисковых операций практически удваивается (если в массив объединены два диска). Можно подключить и бо́льшее число дисков, но скорость растет уже не столь рьяно - сказываются накладные расходы. Вот о них давайте немного поговорим.
RAID 0, чередование. Основная идея в том, что файлы разбиваются на блоки и их четные номера записываются на первый диск, а нечетные на второй (если используются два дисковых накопителя). При получении команды ‘считать файл’ контроллер RAID 0 рассыпает запросы чтения на оба диска и начинает считывать с них четные и нечетные блоки секторов.
В действительности HDD ничего не знает о 'файлах' и оперирует понятиями 'сектор' и "последовательность секторов". В результате этого действия оба HDD одновременно выполняют чтение информации, причем каждый из них читает в два раза меньше информации, чем затребованный файл, что обеспечивает удвоенную скорость чтения, по сравнению с одиночным диском. Если дисков в массиве больше двух, то расщепление производится на большее количество субъектов, работающих одновременно. По технологиям RAID очень много информации в сети, поэтому специально останавливаться не стоит. Ну, хорошо, расщепить-то можно, но какова размерность блока расщепления?
И тут сразу начинаются танцы с бубном, ведь никаких рекомендаций по выбору размера stripe нет. Просто нет и всё. Ставьте 'default', вот самое умное, что можно услышать. Не знаю как вам, а меня такая гибкая позиция производителей аппаратуры не слишком обрадовала.
Размер блока расщепления, или чередования, должен зависеть и от контроллера, и от используемых дисков, и от того, где это будет работать. Пришлось написать HAB - программу, на которую я уже ссылался не раз.
Суть программы в том, что измеряется скорость линейного и буферизированного чтения для разного размера блока выполнения операции и выясняется та величина блока, на котором еще не происходит падение производительности.
Хотел бы специально отметить, программа не измеряет скорость работы диска, у нее чисто утилитарная задача - выяснить величину задержки во всём канале передачи данных, от процессора до контроллера диска, и на основе этого дать рекомендацию о величине блока чередования RAID 0. Несколько запутано, но смысл действия в том, что задержки в канале не позволяют обмениваться очень быстро и скорость выполнения операций с небольшими блоками падает. Если выбрать размер блока побольше, скажем 128 Кбайт, то операции чтения файлов такого и меньшего размера будут выполняться только на одном диске и ускорения не произойдет.
Вообще говоря, RAID 0 ускоряет работу с файлами, которые больше блока чередования, ибо только тогда один файл будет считываться с нескольких дисков. А это означает, что маленький размер блока Stripe ограничен задержками и загрузкой процессора на выполнение обслуживания ввода-вывода. Хоть процессор и не участвует в пересылке данных, это осуществляется аппаратным способом через механизм bus mastering, но от процессора требуется настройка аппаратуры для последующей передачи данных. Чем меньше блок, тем больше число операций ввода-ввода, и тем сильнее загружен процессор. Для современных многоядерных процессоров вроде бы это не столь актуально, но большая загрузка проходит незаметно только в простое системы. Если же подгрузка данных производится во время игры, то 'внеплановая' загрузка процессора может вызвать 'странную дерганность' картинки, вплоть до фризов (остановка или очень низкий FPS). S.T.A.L.K.E.R. помните?
Чтобы не возвращаться, рекомендация по включению компрессии системного диска для Windows 7:
| При загрузке нажать F8, попадем в меню, выбрать "восстановление загрузки системы", войти в систему и выполнить следующую последовательность команд: X:\Windows\System32\>cd c:\Windows\System32\ X:\Windows\System32\>c: C:\Windows\System32\>compact /c /a /i /s:c:\ Подробнее в нашей Конференции. |
(Примечание переводчика.
Автору окончательно снесло чердак. Откуда эта дурь с одновременностью получения данных с двух дисков? Он что, считает, будто все диски крутятся строго синхронно и все HDD одновременно обрабатывают одну и ту же команду? Если контроллер RAID 0 выдает два HDD запроса на чтение последовательного набора секторов, то ответ может последовать первым вовсе не с первого диска, на который запрос был отправлен в начале действия. Первым ответит тот, у которого удачнее оказался угол поворота диска. Второй ответит от 'почти сразу' до ‘времени поворота диска’.
И потом, какой смысл говорить об экономии нескольких микросекунд на доступ к блоку 4-128 Кбайт, если позиционер ползет до дорожки 12 миллисекунд. Разница времен 'на порядки'. Если же включен режим не RAID 0, а RAID 0 + AHCI, то вообще все покрывается лесом. Все диски занимаются своими делами, приход команд от контроллера на два диска означает лишь, что эти запросы будут поставлены в очередь выполнения и ответ будет получен 'когда-нибудь'. То есть 'расщепление’ маленького блока на несколько дисков приведет к УВЕЛИЧЕНИЮ времени получения ответа – ведь придется дожидаться ответа от ВСЕХ дисков массива. Автору срочно сменить траву).
RAID 0, от HDD к SSD
Вроде бы, и то, и то - дисковые накопители со стандартным интерфейсом SATA, откуда взяться различию при работе в RAID 0? Увы, они есть. SSD обладают другим построением и оно настолько отличается от идеологии работы HDD, что программа HAB ничего умного сказать не сможет. И дело не в глупости программы. Можно устанавливать любой размер блока чередования и результат будет измеряться 'толщиной волоса'. Intel рекомендует для своих SSD использовать блок чередования размером 16 Кбайт. Логику данной рекомендации я проследить не берусь, разве что в том, что при таком размере контроллеру SSD приходится меньше ждать прихода следующего блока.
У RAID 0 контроллеров довольно часто встречается одна пренеприятнейшая особенность - они могут записывать в начало дисков технологическую информацию, что сдвинет нумерацию секторов. Это безразлично для обычных HDD, но диски с "Advanced Format" и SSD сразу получают черную метку.
HDD с AF просто потеряют производительность операции записи (да и чтения тоже), а с SSD всё еще хуже - сдвиг на сектор вызовет неполное совпадение секторов данных с границами страницы, что приведет к обязательному предварительному вычитыванию страницы NAND перед ее записью. Но и это не самое большое зло, в SSD увеличится общее количество операций записи, что снизит ресурс диска.
Оценить, есть ли сдвиг на сектор в программах типа HAB практически нельзя, очень уж мощная система кэширования у SSD. В данном случае лучше проверять скорость записи, для чего можно ознакомиться с довольно интересной темой ”Форматирование флешевых накопителей с выравниванием кластера на границу блока”.
И еще о SSD и RAID
Вообще, странная и очень подозрительная вещь, этот драйвер Intel(R) Rapid Storage Technology (далее в тексте 'RST'). В рекомендации Intel для своих SSD советуется устанавливать именно этот драйвер, даже на одиночные диски. Странно, не находите?
Теперь давайте посмотрим картинки.
Обычный X25-M:
Их пара, уже под RST:
Замечаете разницу? В первом случае 'провалы' гораздо больше, чем во втором. И это при том, что TRIM и GC для RAID не использовались. Впрочем, с TRIM в драйвере RST прояснилось, он поддерживается и для режимов с чередованием. Но всё равно, с TRIM или без, но очень уж разительный контраст поведения.
Особенность топологии RAID в том, что диски полностью изолируются от операционной системы и, вообще говоря, контроллер RAID может делать с ними что захочет, это 'черный ящик'. Сдается мне, что нехорошие дяденьки из фирмы Intel для SSD собственной разработки делают кое-что неочевидное.
Одна из болезней SSD во фрагментации - на него записываются данные разной длины, причем часть из них удаляется. Что досадно, удаляются не большие файлы, а именно мелочь. Как следствие, SSD оказывается фрагментирован. Для обычного HDD это просто неприятно, а у SSD всё гораздо запущеннее и падение производительности, особенно на запись, может стать ‘жуткой’ - из-за мелких дырок придется переписывать большое количество страниц для объединения свободного пространства. Дело в размере блоке стирания, он очень большой.
Так вот, у меня есть ничем не подкрепленная мысль, что RST не так прост и делает "сборку мусора" еще на стадии записи файлов. Собственно, а что ему мешает чуть задержать одни файлы и пропихнуть вперед другие так, чтоб при записи они оказались выровненными? Запись производится в последовательные страницы NAND, поэтому для управления выравнивания достаточно лишь переупорядочить команды записи во времени.
Интересно, кто-нибудь догадается написать драйвер, выполняющий подобную функцию для не-Intel SSD?
Stripe и Torrents
Существует масса рекомендаций по настройке системы под Torrents, но давайте остановимся на оптимизации дисковой подсистемы. Производительность HDD для блока доступа 128 Кбайт, а именно такими обменивается Torrents (смотреть выше), определяется от времени доступа. Чем быстрее крутится диск, тем больше блоков удастся считать с него за единицу времени.
Из этих соображений вполне логичным было бы перейти на SSD, ведь основной режим p2p систем - это раздача. Увы, смотрите статистику выше, клиент Torrents не оптимизирован для работы на SSD, он постоянно пишет какую-то технологическую информацию на диск. Если для HDD это не важно, то у SSD ресурс ограничен. Вряд ли стоит применять такой носитель для Torrents, по крайней мере, до тех пор, пока они не исправят свою, извините, ошибку.
Итак, остаются обычные диски. Если собирать систему на действительно обычных HDD со скоростью вращения 7200 об/мин, то это позволит получить до 70 операций в секунду или скорость раздачи 9 Мбайт в секунду. При расчете подразумевалась самая неудачная конфигурация раздачи – множество соединений со скоростью около 125 К на огромном файле (порядка 30 Гбайт), да еще и без пересечений у участников. В реальной работе такое встретится не может, обычно скорости или существенно больше 125 К или много меньше этой цифры.
Первое означает бо́льшую скорость, второе – бо́льший шанс попасть в блок, который есть в памяти. Torrents работает с блоками по 4 Мбайта. Можно попробовать предположить, что обычного HDD с 7200 об/мин будет достаточно для раздачи с 2-4 большей скоростью, чем вычислено. Как аргумент могу привести то, что прием 5-6 М и раздача 2-3 М на Seagate ST3500320AS (7200.11) ничем необычным не проявлялась. Заметить активность uTorrent можно, только развернув саму программу.
Но как же повысить производительность, если SSD ставить не желательно? Поставить несколько HDD? Направление мысли верное, но какой смысл в нескольких дисках, если на них будут лежать разные файлы? Активная раздача, как правило, ведется ограниченным числом новинок, которые быстро устаревают и заменяются новыми 'хитами'. Специально раскидывать такие файлы по разным дискам? Можно, конечно, но кто будет этим заниматься?
Механизмы, типа RAID 0, в подобной проблеме не помогут - нет смысла ускорять считывание, важнее увеличить количество потоков. Оп, а может помогут? Давайте вывернем проблему наоборот - необходимо разместить один файл на нескольких дисках для того, чтобы множество дисков проводили чтение различных фрагментов одного и того же файла.... и это очень хорошо делается механизмом функционирования RAID 0.
Но нам не нужна скорость, варианты? А что, если в настройках RAID 0 поставить самый большой размер блока чередования? При этом практически не будет никакого ускорения считывания (и записи) блоков 128 Кбайт, которыми работает Torrents, но на один запрос будет отвлекаться только один диск массива. А это значит, что при большом количестве считываний по довольно случайным адресам, что свойственно Torrents, нагрузка равномерно распределится на все диски.
Отсюда можно вывести еще одно пожелание - не ставьте дорогие 'высокооборотистые' диски. За стоимость одного такого 'монстра' можно приобрести несколько обычных 7200 об/сек HDD, даже с невысокими скоростями чтения/записи, и они дадут лучшую отдачу системы под подобный класс задач. Просто соберите на них RAID 0 с большим блоком чередования.
Вместо заключения.
Еще одна проблема с множеством сломанных копий. Не минула чаша сия и меня. В стародавние времена я немного исследовал этот вопрос, но дальше 'наблюдений' дело не пошло. Всё было намертво забыто, но ... шила в мешке не утаишь. К вопросу жесткости монтирования HDD придется вернуться, хоть и совсем по другой причине. Если раньше боролись с шумом и вибрацией, теперь возникла необходимость в борьбе с вибрациями, но - наоборот, для самого HDD.
Столько слов, столько слов - давайте прямо к сути, а?
В нашей Конференции обсуждается много проблем, в том числе был вопрос по странно низкой скорости работы HDD. Я попросил автора вопроса провести небольшую проверку, которая заключалась в запуске теста производительности HD Tune с одновременной установкой диска в DVD привод где-то посередине прогресса графика.
Вариант с пустым DVD приводом и с установкой диска в DVD.
Неравномерность графика и заниженные показания связаны с неверной настройкой HD Tune, установлен слишком маленький размер блока тестирования, но для нашей проблемы это не существенно.
На втором рисунке, с установкой диска в DVD привод, хорошо заметны провалы скорости чтения, весьма продолжительные во времени. Вообще-то, при повторении такой проверки на системном диске в момент установки диска в DVD провалы на графике будут, они вызваны повышенной активностью операционной системы на появление нового устройства, но не такие же большие и по величине, и по продолжительности. Попробуйте на своем компьютере как-нибудь.
Итак, что означает сей дефект? Увы, это не просто провал производительности, а нечто худшее - HDD начинает работать неправильно. А именно, вибрация HDD, вызванная эксцентриситетом вращения диска DVD, сбивает магнитную головку с дорожки.
В последнее время ширина трека уменьшилась, конкретные цифры были показаны ранее. Чем 'уже’ дорожка, тем труднее удержать на ней головку, не зря же в некоторые модели HDD стали устанавливать пьезоэлементы доводки позиционера и датчики вибрации, ускорения. Ранее эта экзотика присутствовала только в элитных HDD и их появление в массовых моделях уж чем-чем, а случайным точно не будет. На то есть четкая причина - головку очень трудно удержать на дорожке, она крайне чувствительна к внешним механическим воздействиям. Возможно, что и к 'внутренним' тоже, но эти возмущения создаются механикой самого диска, а потому поддаются программному контролю и могут компенсироваться.
Была еще интересная тема в Конференции, по низкой производительности диска, в которой один человек запустил тест со случайной перезаписью секторов диска. Мотивировалось это возможным улучшением работы, а привело к убиванию всей поверхности дисков.
Если головка не может удержаться при чтении, то это банальное снижение скорости чтения в несколько раз, а вот срыв стабилизации при включенной записи выбивает сектор этой и соседней дорожек. Даже если механическое воздействие и не вызвало 'вылет' на другую дорожку, то представьте, как будет выглядеть этот трек? Ну, примерно так же, как проезжие дороги в российской глубинке - прямые и ровные. Проверить мое предположение затруднительно - ссылка на сообщение в Конференции была утеряна, а повторять аналогичные действия на своем HDD я не стал. Уж простите.
Защита от вибрации.
Из простых способов обезопасить HDD от внешних воздействий, чаще встречаются два - подвесить диск на чём-то гибком или поставить его на мягкие ножки или распорки.
Первый вариант довольно прост - где-то в корпусе ищется свободный объем и туда подвешивается диск. Можно использовать резинки или нерастяжимую тонкую веревку. Впрочем, вопрос хорошо рассмотрен и вряд ли стоит детально останавливаться. Недостаток данного способа - крайне неэффективно используется объем и потому сложно подвесить больше одного диска.
Второй вариант, на "ножках", более компактный, но существуют определенные трудности с выбором материала ножек. Здесь вот в чём дело - после удара (любого внешнего механического возмущения) происходит колебательный процесс с постепенным уменьшением амплитуды. В зависимости от степени демпфирования будет меняться время от воздействия до перехода системы в стабильное состояние.
Термин 'демпфирование' образовался от 'демпфер' - элемент для поглощения энергии колебаний.
Свое исследование вопроса мягкой подвески я проводил давно, поэтому точных цифр не помню, да они и не переносимы на современные HDD.
В качестве подопытного выступал Maxtor Diamond Plus 9 6Y080P0. Специального программного обеспечения я не нашел, поэтому критерием качества выступал режим измерения времени доступа в программе HD Tach 3.0.
Почему не HD Tune? А знаете, почему-то эта программа не показывала такой 'чувствительности', которая была у HD Tach. В то время я не стал разбираться, а сейчас ответ есть - у HD Tune используется не совсем стандартный алгоритм измерения времени доступа, среднее время перемещения позиционера от начала диска до случайного положения. Как следствие, позиционер перемещался, в основном, около внешнего края диска, а не равномерно по всей поверхности. Допустимо это или нет, правильно или ошибочно - да неважно. В HD Tach я видел изменение времени доступа в зависимости от метода крепления, и этого было достаточно.
Итак, при разном способе крепления меняется время доступа. Почему? Попутный вопрос - и насколько это вредно?
При перемещении на новую дорожку, на соленоид позиционера подается новое напряжение, что смещает угол поворота позиционера и головка передвигается между дорожками. Думаю, ни у кого не возникает мысли, что при прыжке магнитной головки на "полдиска" сразу попадешь на нужный трек. После основного перемещения придется еще прыгать и прыгать до нужной дорожки. А при чем здесь колебания и демпфирование? Если вы держали в руках работающий HDD, когда он ‘дергает’ позиционером, то отчетливо помните характерные удары (если не держали, то и не надо пробовать - это вредно для HDD).
Сила действия равна силе противодействия. Если позиционер повернулся, то сам HDD тоже повернется, в противоположную сторону. Но эта связь обратима - если приложить усилие поворота на HDD, то и позиционер повернется из-за инерции покоя. Это означает, что поворот корпуса HDD, вызванный перемещением позиционера, влияет на поворот этого самого позиционера. Если сложно в восприятии, попробую аналогию - возьмите какую-нибудь сумку и положите в нее что-нибудь не слишком тяжелое. Теперь раскачайте - Ваша рука будет испытывать усилия смещения вправо и влево. Попробуйте не сопротивляться этим усилиям - колебания сразу уменьшатся и сумка остановится. Для HDD 'колебания' - это перемещение позиционера, а усилие в удержании сумки - это мера демпфирования.
Чем жестче закреплен диск, тем меньше сдвигается его корпус и тем предсказуемее работает система позиционирования. Контроллер предполагает, что установкой напряжения Х позиционер переместится на нужную дорожку.
Так и произойдет, он примерно там и окажется, при условии, что корпус HDD не внес чего-то дополнительного. Датчики ускорения не особо распространены, поэтому адаптации к смещению корпуса контроллер сделать не может. А это означает, что позиционер попадет не совсем туда, куда предполагалось. После чего контроллер начнет последовательно искать нужную дорожку .... но все смещения корпуса носят колебательный характер. Если корпус сместился в результате удара или движения позиционера, то потом он вернется в свое первоначальное положение. Это понятно, но это перемещение наложится на работу позиционера, ведь его 'тащат' теперь уже в другом направлении.
Если первоначально был 'недолет' из-за движения корпуса, то впоследствии будет 'перелет' от возврата корпуса в устойчивое положение. Если бы программа контроллера HDD выполняла позиционирование очень-очень долго, то такое движение 'туда-сюда' было бы безразлично. Но время доступа крайне важно, поэтому положение позиционера отслеживается весьма активно. При обнаружении факта недолета контроллер сделает следующий 'прыжок' на новую предполагаемую дорожку и промажет, ведь корпус начнет движение назад.
Давайте сразу определим два параметра - жесткость и демпфирование. Жесткость - это то, на сколько сместится корпус диска от механического воздействия, а демпфирование - как быстро прекратятся его колебания.
В примере я рассматривал всего два движения корпуса после удара - вперед и назад. Это было бы хорошо, но часто за ним следует снова вперед, потом снова назад и так далее с постепенным уменьшением амплитуды. Программа управления позиционером просто сойдет с ума от такого "вперед-назад и много раз". Хотелось пошутить, а вышло грустно. Если период колебаний будет большим, то головка уже успеет настроиться на дорожку и последующее возвратное движение корпуса приведет к ... а если в этот момент уже началась запись?
Увы, современные диски получили настолько узкую дорожку, что проблемы вибрации и внешних воздействий не просто 'сказываются', а действительно могут нарушить работу HDD вплоть до выхода его из строя. И тут уже без шуток, в конференциях встречались картинки тестов скорости чтения с полностью 'убитой' скоростью. Что при этом творится в SMART, я не знаю, далеко не всегда удается пообщаться с владельцами этих несчастных дисков.
Ну ладно, к нашим баранам.
Есть жесткость крепления, которая определяет амплитуду и частоту колебаний, и есть степень демпфирования, от которой зависит, насколько быстро уменьшатся свободные колебания во времени.
При мягкой подвеске на растяжках, жесткость крепления "никакая" и это плохо? Вообще-то, не хорошо, но и не плохо - при мягком креплении увеличивается амплитуда колебаний при внешнем воздействии, но одновременно с этим увеличивается и период этих колебаний (частота уменьшается). Для работы системы позиционирования вредоносным является не скорость перемещения корпуса, а ускорение его движения. Поэтому, хоть амплитуда колебаний увеличивается, но растет и период колебаний. Попробуйте помахать рукой широко и неторопливо, а потом быстро и с меньшим размахом. Во втором случае напряжение мышц наверняка будет больше. Так вот, для HDD важно как раз это "напряжение мышц", а не то, на сколько вы двигаете рукой.
Теперь по демпфированию, которое определяет время до окончания колебательного процесса.
Повторю картинку:
При высоком демпфировании (на рисунке график красного цвета) нет никаких признаков колебаний. Для среднего демпфирования тоже, а вот при низком (график синего цвета) отчетливо видно движение туда-сюда, наличие колебаний.
Что такое демпфирование? Это поглощение механического движения и преобразование его в тепло. Только так, иначе демпфирования не будет.
Я провел простой тест - поставил HDD на гибкие ножки и померил время доступа. Чем меньше время, тем четче работает механизм позиционирования и тем лучше чувствует себя диск.
Обычное время доступа для Maxtor Diamond Plus 9 6Y080P0, выполняющего роль тестового, составляет порядка 12.5 мсек.
Удивлены? Ничего странного, каучук вязкий и поглощает колебания, а резина нет. Поставили на резиновые ножки – ‘убили’ диск.
Измеренное ранее 12.5 мсек получено при размещении диска на поролоне, электроникой вверх. Из всего, что я проверял, этот способ дает наилучшие результаты. А как же обычное крепление в системном блоке? Точной цифры не помню, порядка 13.5 мсек. Да-да, стандартное крепление не соответствует наилучшему. Удивлены? ... попробуйте проанализировать траекторию движения позиционера, его ось вращения и точки крепления диска - и вы удивитесь откровенной неудачности данного варианта монтажа HDD. Давайте сделаем наоборот, поставим диск ‘стороной с кабелем’ к передней стенке, и? Результат совпадает с предположенным - время доступа уменьшилось, стало лишь чуть хуже 12.5 мсек (порядка 12.7 мсек, не помню).
Кроме того, в ряде корпусов системных блоков HDD ставится через резиновые вставки. О?
Посмотрим. Напрямую проверить вставки в моем корпусе не получится, HDD входит в свою секцию плотно, прижимаясь к боковым стенкам. Хорошо, берем лом и рихтуем стенки. Против лома нет приема, поэтому протестировать вставки сможем. При этом HDD будет прикручиваться через четыре винта крепления. Они проходят через вставки и не влияют на виброизолирующие свойства получившейся конструкции. Я не просто так вспомнил про винты, скоро придется к ним вернуться.
Ладно, собрал и проверяю - 20 мсек. Волосы дыбом, срочно меняю специальные винты с ограничителем на обычные и начинаю их затягивать - при этом повышается жесткость крепления. Время доступа уменьшается, порядка 18 мсек. Затягиваю 'до дури', вставки расплющиваются в лепешки - время падает до 15 мсек. Масса эмоций, вставки летят в корзину, затягиваю винты полностью и .... получаю всё те же 13.5 мсек, что были до доработки. В результате получаем искореженный корпус и массу плохого настроения.
Уж не знаю, работают ли эти вставки в штатном варианте установки, но в моем случае полный провал. Что до уровня шума, а тогда стояла эта проблема, то его измерить было нечем, поэтому эффект доработки оценить сложно. Но, в случае с вставками, я и слушать не стал - 20 мсек доступа я могу получить банальным включением AAM, что гарантированно безопаснее для диска и точно тише стандартного варианта с выключенным AAM и 'такой' установкой HDD.
Ну, в жизни бывает всякое. На глаза попалось интересное сообщение, фрагмент:
В период примерно месяц - полетели у четырех тов. новые винты марок Seagate и вроде один WD. У четырех винтов битые сектора (у одного очень много и в начальной области). И отработали они после покупки менее месяца. ... И, главная особенность, на всех винтах были установлены кулеры в виде пластмассовой коробочки, прикрепленной сверху винта. Внутри два маленьких кулера.
Автор сообщения делает предположение, что источником проблемы стали магнитные поля, но вряд ли это так. Попробуйте стереть видеокассету размагничивающим дросселем - кассета будет дребезжать всеми своими частями, но с информацией ничего не случится. Пробовал как-то сэкономить время, кассеты надо было вернуть чистыми и срочно - полное фиаско.
В современных магнитных носителях используются покрытия с очень высокой коэрцитивной силой, просто так они не размагничиваются. Усиленное охлаждение тоже вряд ли стало причиной увеличения дефектности дисков. Тогда что? Как мне кажется, вибрация. Вентиляторы крутятся быстро, что порождает высокочастотную вибрацию, а именно такое воздействие и опасно для диска. Практически проверять не стал, извините. Душа не лежит что-то ломать.
Однако, сам HDD устройство механическое с множеством резонансов различных его частей. Кроме внешних воздействий бывают и внутренние - перемещение позиционера весьма интенсивно встряхивает устройство. С "нормальными" HDD вроде ясен механизм происходящих процессов, а если взять не нормальный? Да хоть тот же VelociRaptor, участвовавший в тесте ранее. У него и легкий позиционер с небольшим ходом, и маленький корпус - с внутренними резонансами проблем быть не должно. В корпусе этот HDD прикручен к самому дну, что обеспечивает высокую жесткость крепления и отсутствие передачи вибрации на и с него от других устройств компьютера.
Запускаю тест:
На рисунке три графика - нижний на периферийной части диска (начало), средний в середине, верхний - во внутренней части (конце).
Начало и середина нормальные, а при перемещении позиционера во внутренней части диска есть один четкий ‘резонансный’ пик. Или это откровенная ошибка программного обеспечения HDD или в наличии резонанс в механической системе.
Что до SSD, то им не страшна вибрация и удары. Конечно, если не сбрасывать их с n-го этажа. Ну, хоть что-то радует.
Программу HAB можно взять здесь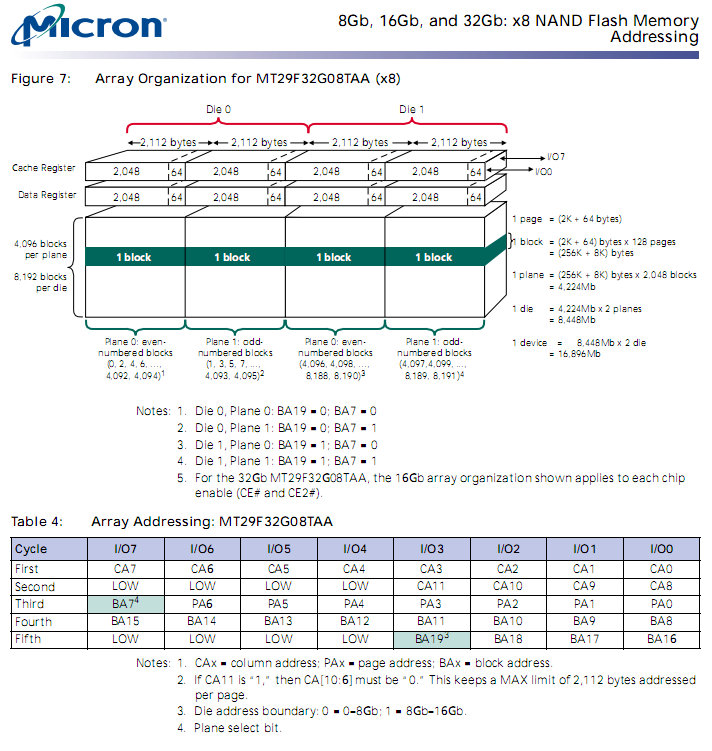{kind=link}
{kind=link}
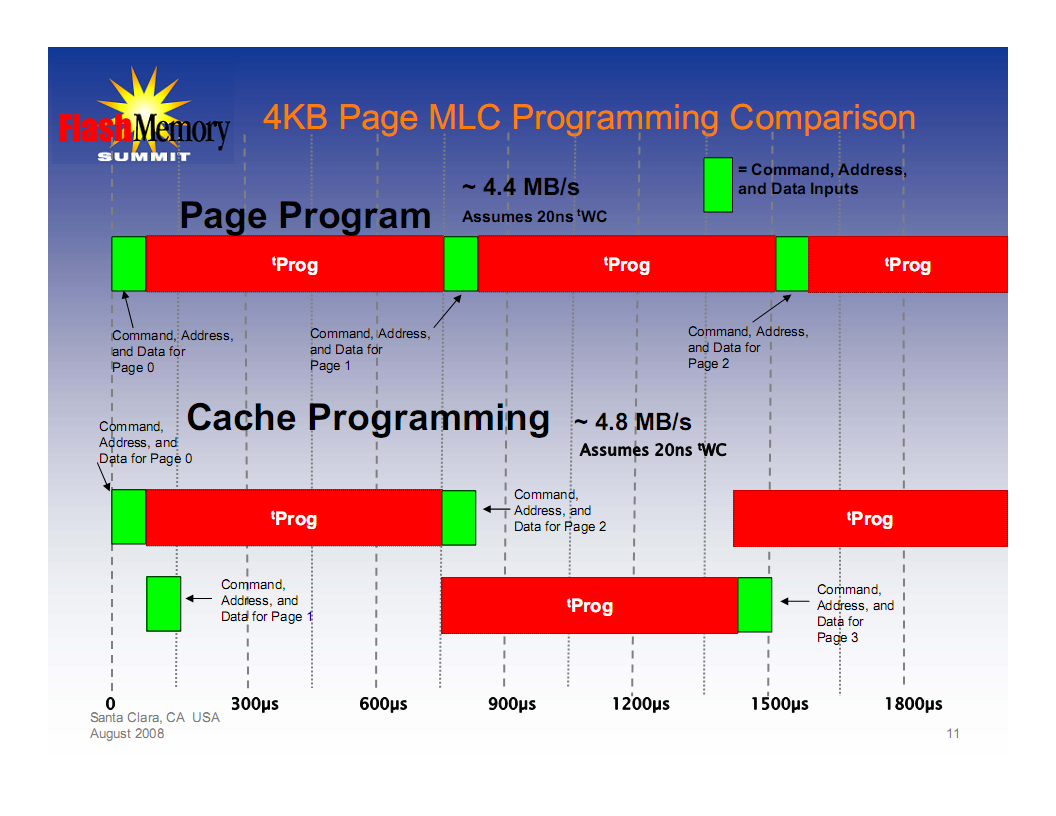{kind=link}
{kind=link}
{kind=link}
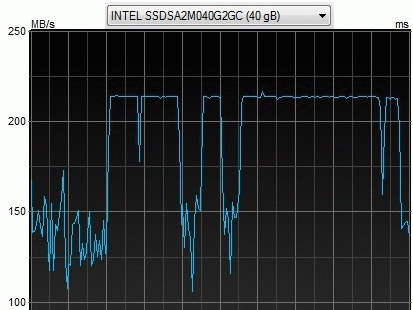{kind=link}
{kind=link}
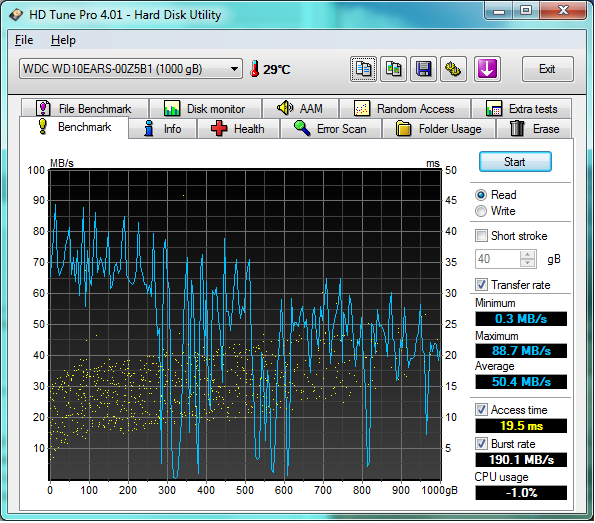{kind=link}