
Выясняем, нужно ли много ядер процессора для типовых задач анализа данных на примере Ryzen
реклама
Проблема масштабируемости производительности.
Я работаю с высокопроизводительными процессорами с числом ядер не менее 12 уже полтора года.
В последнее время задачи, которые приходится решать связаны с обработкой больших массивов телематических данных и ГИС-данных. Дома и на работе есть набор машин с процессорами Ryzen разных поколений, что порождает смежный интерес к тестированию их производительности и пониманию насколько оправданной будет закупка машины на том или ином процессоре. Наши задачи достаточно узкоспециализированные. Но вот что есть практически у всех, кто занимается анализом данных - это типовые задачи по предобработке табличных данных. Более того, большинство аналитиков данных не нагружают процессор ничем иным, кроме реляционных операций с помощью Pandas или подобных инструментов. Уже давно подмечено, что это порядка 65% трудозатрат data scientist'ов. Многие из них убеждены, что добавив в 2 раза больше ядер они ускорят свой код в 2 раза.
В последние дни 2020го я приобрел процессор AMD Ryzen 5950x, в результате чего у меня на руках оказались свободные threadripper 2990wx, ryzen 3900x, 5950x, плюс, так как очень хотелось включить старшие процессоры zen2 в эту статью я попросил прогнать свой код товарища, обладающего 3960x.
реклама

Имея такой зоопарк Ryzen'ов было большое желание сравнить их в том, на что мало кто обращает внимание при тестировании - насколько хорошо они масштабируют производительность с увеличением ядер в реальных прикладных задачах на реальных производственных данных.
Можно ли положиться на рендер бенчмарки?
Можно ли купить процессор, рассчитывая на его эффективный параллелизм в анализе данных, полагаясь на цифры, доступные из популярных бенчмарков, типа Cinebench или Blender? Рендеринг очень хорошо параллелится хоть на уровне пикселей, хоть на уровне объектов и при прямых руках создателей рендер-движков производительность растет линейно в зависимости от количества ядер процессора. Но это не значит что для ваших прикладных задач все будет так гладко, и что условный Ryzen 5800х не окажется на равных с вашим 5950х, как бы вы не старались с оптимизацией кода. У вас могут возникнуть проблемы, описанные ниже, и не влияющие на эффективность рендеринга в Cinebench.
Разные уровни многопоточности
реклама

Предположим, вы заменили 4х-ядерный процессор на 12-ядерный в вашей системе, и ожидаете, что ваш код будет теперь исполняться в 3 раза быстрее. Для этого нужно чтобы все звезды сошлись, а именно:
- В вашем коде вы самостоятельно определили многопоточное исполнение определенных процедур.
В самых простых случаях это потребует изменения всего двух строчек программы. Однако на практике вы можете собрать миллион разных проблем, особенно если код большой. Например, таких. Что в конечном счете может привести вас к решению оставить идею параллелизма, так как переход к нему потребует больше человек*часов, нежели издержки от работы в одном потоке. - Язык разработки предоставляет эффективный инструментарий многопоточности, а интерпретатор или компилятор оптимизирует многопоточные вызовы. Так, например, суперпопулярный язык Python имеет болезненную проблему из-за невозможности полноценного параллелизма на уровне потоков, обусловленную Global Interpreter Lock (GIL). Из-за этого питонисты чаще работают с более тяжеловесными сущностями - процессами, зачастую проигрывая в разы по эффективности параллелизма разработчикам на той же Java.
- Операционная система должна нам помогать, а не вставлять палки в колеса нашего многопоточного кода. Дело в том, что базовые сущности: Поток и Процесс определены на уровне системы, и то, насколько эффективно они работают и взаимодействуют друг с другом, определяется ядром ОС. Довольно известна проблема, когда Windows 10 до определенного патча катастрофически снижала производительность процессоров Threadripper 2970wx, 2990wx, в виду незнания системы об их NUMA-топологии. Также важна система адресации памяти.
- И, наконец, само железо должно иметь как можно меньше бутылочных горлышек, позволяя приближать рост скорости выполнения программ в зависимости от количества ядер к линейному.
Если на всех этих уровнях все идеально, то, заменив, скажем, Ryzen 3100x на 3900x мы бы получили 3-кратный прирост производительности. К сожалению, в реальном мире это не так, и прирост в большинстве прикладных вычислительных задач будет ниже линейного. В этом вы можете убедиться ниже, в разделе Тесты.
Факторы влияющие на масштабирование производительности
Что является основными препятствиями к заветному линейному увеличению производительности? Основными факторами являются следующие:
- Соотношение времени выполнения полезного когда, с помощью которого вы обрабатываете данные и "инфраструктурного" кода создания и уничтожения потока или процесса. В худшем варианте мы получим такую картину:
 Здесь, во-первых, мы разбили данные на слишком мелкие кусочки, такие, что отдельный процесс будет дольше создаваться и уничтожаться, чем обрабатывать их. Во-вторых, здесь использован параллелизм на уровне процессов, а процесс в операционных системах (что Windows, что Linux) - тяжеловесная сущность со своим адресным пространством памяти, которая на порядки дольше будет создаваться и разрушаться, чем поток.
Здесь, во-первых, мы разбили данные на слишком мелкие кусочки, такие, что отдельный процесс будет дольше создаваться и уничтожаться, чем обрабатывать их. Во-вторых, здесь использован параллелизм на уровне процессов, а процесс в операционных системах (что Windows, что Linux) - тяжеловесная сущность со своим адресным пространством памяти, которая на порядки дольше будет создаваться и разрушаться, чем поток.
В лучшем варианте будет такое:Вместо разбивки на мелкие батчи, данные были разбиты на крупные, вместо процессов были использованы потоки, соотношение времени исполнения полезного кода к инфраструктурному - высокое. К сожалению, не всегда возможно разбить данные на крупные куски. Самое печальное, что с ростом числа ядер время на создание многочисленных процессов возрастает нелинейно, в худших случаях мы запросто получим, что "параллельный" код работает одинаково быстро на 1м и на 64х ядрах. - Интенсивность обращения к памяти по произвольным адресам. Здесь все просто - если операции процессора постоянно требуют данные из памяти по случайному адресу, то все упрется в число каналов памяти, частоту памяти и задержки. Как вариант обойти эту проблему - делить данные на куски, помещающиеся в кэш и обрабатывать такие куски поочередно. Но существует множество задач, где такая оптимизация невозможна - мы не можем предугадать, что именно надо положить в кэш.
 Здесь, во-первых, мы разбили данные на слишком мелкие кусочки, такие, что отдельный процесс будет дольше создаваться и уничтожаться, чем обрабатывать их. Во-вторых, здесь использован параллелизм на уровне процессов, а процесс в операционных системах (что Windows, что Linux) - тяжеловесная сущность со своим адресным пространством памяти, которая на порядки дольше будет создаваться и разрушаться, чем поток.
Здесь, во-первых, мы разбили данные на слишком мелкие кусочки, такие, что отдельный процесс будет дольше создаваться и уничтожаться, чем обрабатывать их. Во-вторых, здесь использован параллелизм на уровне процессов, а процесс в операционных системах (что Windows, что Linux) - тяжеловесная сущность со своим адресным пространством памяти, которая на порядки дольше будет создаваться и разрушаться, чем поток. Вместо разбивки на мелкие батчи, данные были разбиты на крупные, вместо процессов были использованы потоки, соотношение времени исполнения полезного кода к инфраструктурному - высокое. К сожалению, не всегда возможно разбить данные на крупные куски. Самое печальное, что с ростом числа ядер время на создание многочисленных процессов возрастает нелинейно, в худших случаях мы запросто получим, что "параллельный" код работает одинаково быстро на 1м и на 64х ядрах.
Вместо разбивки на мелкие батчи, данные были разбиты на крупные, вместо процессов были использованы потоки, соотношение времени исполнения полезного кода к инфраструктурному - высокое. К сожалению, не всегда возможно разбить данные на крупные куски. Самое печальное, что с ростом числа ядер время на создание многочисленных процессов возрастает нелинейно, в худших случаях мы запросто получим, что "параллельный" код работает одинаково быстро на 1м и на 64х ядрах. реклама
Итак, нам нужно либо оптимизировать код таким образом, чтобы процессор не выполнял лишнюю инфраструктурную работу и обрабатывал данные по-максимуму из своего кэша, либо нам нужно более совершенное железо, оптимизированное под эти две проблемы. Повторюсь, первое не всегда возможно. Допустим, вы обрабатываете 10 миллионов объектов, каждый из которых весит от 5 килобайт до 10 мегабайт. Заведомо вы не знаете как оптимальнее их разбить на батчи. Другой пример - вы обрабатываете миллион документов, причем какой следующий документ взять может быть известно только после обработки текущего. Как вы поймете какой набор документов оптимальнее всего кэшировать? Поэтому очень хотелось бы видеть прогресс на уровне железа.
Тесты для Zen+, Zen2 и Zen3
Давайте посмотрим, как хорошо плохо масштабируются различные типовые задачи анализа данных для разных поколений Zen.
За Zen+ играет единственный, зато флагманский представитель: 32х ядерный Ryzen Threadripper 2990wx
Zen2 Представлена двумя бойцами: 12-ядерный Ryzen 3900х и Ryzen 24-ядерный 3960x
реклама
Zen3 представляет Ryzen 5950x
 2990wx редкий зверь, даже жалко было продавать, через лет 20 коллекционеры бы озолотили
2990wx редкий зверь, даже жалко было продавать, через лет 20 коллекционеры бы озолотили
Какие задачи будут использоваться в тестировании:
- ETL Python. Типовая задача по трансформирванию таблицы данных с помощью реляционных операций.
Такая задача нужна повсеместно для анализа данных - вы собираете несколько таблиц в памяти, например, таблицу с учетными записями пользователей, таблицу с историей их покупок в интернет-магазине, и таблицу с данными о приобретённых ими товарах. Далее вам нужно все это соединить, преобразовать и очистить. Для этой задачи мы напишем простой код на Python с использованием Pandas и библиотеки Joblib для параллелизма на уровне процессов. Сниппет здесь. Батчи данных максимально большие (число строк в исходных данных / число потоков). Параметры датафрейма: 1 000 000 строк, 10 колонок. Операции: вычисление расстояния на сфере, вычисление статистик, поиск строки в подстроке, соединения, группировки. - ETL C++. Аналогичная первой задача, но написанная на C++ c параллелизмом на уровне потоков (используется простейший std::thread) и активным использованием регистровых переменных
- Catboost. Использование фреймворка CatBoost для машинного обучения. Градиентный бустинг традиционно сыплет непредсказуемыми запросами в память. Рабочая лошадка машинного обучения, между прочем.
Во всех тестах использовались настройки памяти: 3133-15-17-18
ОС: Ubuntu 20.4, ядро 5.10 (все более ранние версии не очень у меня дружат с 5950х - хозяйкам на заметку)
- ETL Python: Отмасштабированная картинка для >= 16 потоков:Как мы видим, после 8 процессов эффективность от добавления новых процессов значительно снижается. Во-первых это обуславливается боттлнеком при работе с памятью. Особенно это заметно по динозавру 2990wx. Во-вторых, это может обуславливаться тем, что с увеличением количества процессов уменьшается размер батчи обрабатываемых данных. Для 8 процессов мы делили исходный набор данных на 8 кусков, для 32х процессов - кусков будет больше, следовательно отдельный кусок - меньше. Тем не менее и после 8 процессов разные процессоры оказываются сравниваемыми. Лучше всех себя показывает 3960x на 25% опережая 3900х и 2990wx.
- ETL C++:
Отмасштабированная картинка для >= 16 потоков:Тут опять же, после 8 потоков (да, тут уже потоки, одно адресное пространство и одни переменные) скорость увеличения производительности значительно снижается. При этом код более-менее оптимизирован. Однако, если мы взглянем на отмасштабированную картинку, увидим, что разница в эффективности процессоров значительная. Вдумайтесь, на 32х потоках 5950х в разгоне в 2 раза обошел 3960х! И при этом его кривая монотонная - то есть невооруженным взглядом видно, что производительность растет при введении в бой новых ядер процессора. - Catboost:
Обычно градиентный бустинг не хочет больше 8 ядер (zen 3 доказал, что хочет) И это доказано не только мной, вот тут отличное исследование. Мы опять видим, что после 8 потоков никакого феноменального улучшения, а после 12 - почти у всех ухудшение. Исключение - 5950х в разгоне. Zen 3 продолжает удивлять.
 Отмасштабированная картинка для >= 16 потоков:
Отмасштабированная картинка для >= 16 потоков: Как мы видим, после 8 процессов эффективность от добавления новых процессов значительно снижается. Во-первых это обуславливается боттлнеком при работе с памятью. Особенно это заметно по динозавру 2990wx. Во-вторых, это может обуславливаться тем, что с увеличением количества процессов уменьшается размер батчи обрабатываемых данных. Для 8 процессов мы делили исходный набор данных на 8 кусков, для 32х процессов - кусков будет больше, следовательно отдельный кусок - меньше. Тем не менее и после 8 процессов разные процессоры оказываются сравниваемыми. Лучше всех себя показывает 3960x на 25% опережая 3900х и 2990wx.
Как мы видим, после 8 процессов эффективность от добавления новых процессов значительно снижается. Во-первых это обуславливается боттлнеком при работе с памятью. Особенно это заметно по динозавру 2990wx. Во-вторых, это может обуславливаться тем, что с увеличением количества процессов уменьшается размер батчи обрабатываемых данных. Для 8 процессов мы делили исходный набор данных на 8 кусков, для 32х процессов - кусков будет больше, следовательно отдельный кусок - меньше. Тем не менее и после 8 процессов разные процессоры оказываются сравниваемыми. Лучше всех себя показывает 3960x на 25% опережая 3900х и 2990wx. 
 Тут опять же, после 8 потоков (да, тут уже потоки, одно адресное пространство и одни переменные) скорость увеличения производительности значительно снижается. При этом код более-менее оптимизирован. Однако, если мы взглянем на отмасштабированную картинку, увидим, что разница в эффективности процессоров значительная. Вдумайтесь, на 32х потоках 5950х в разгоне в 2 раза обошел 3960х! И при этом его кривая монотонная - то есть невооруженным взглядом видно, что производительность растет при введении в бой новых ядер процессора.
Тут опять же, после 8 потоков (да, тут уже потоки, одно адресное пространство и одни переменные) скорость увеличения производительности значительно снижается. При этом код более-менее оптимизирован. Однако, если мы взглянем на отмасштабированную картинку, увидим, что разница в эффективности процессоров значительная. Вдумайтесь, на 32х потоках 5950х в разгоне в 2 раза обошел 3960х! И при этом его кривая монотонная - то есть невооруженным взглядом видно, что производительность растет при введении в бой новых ядер процессора. 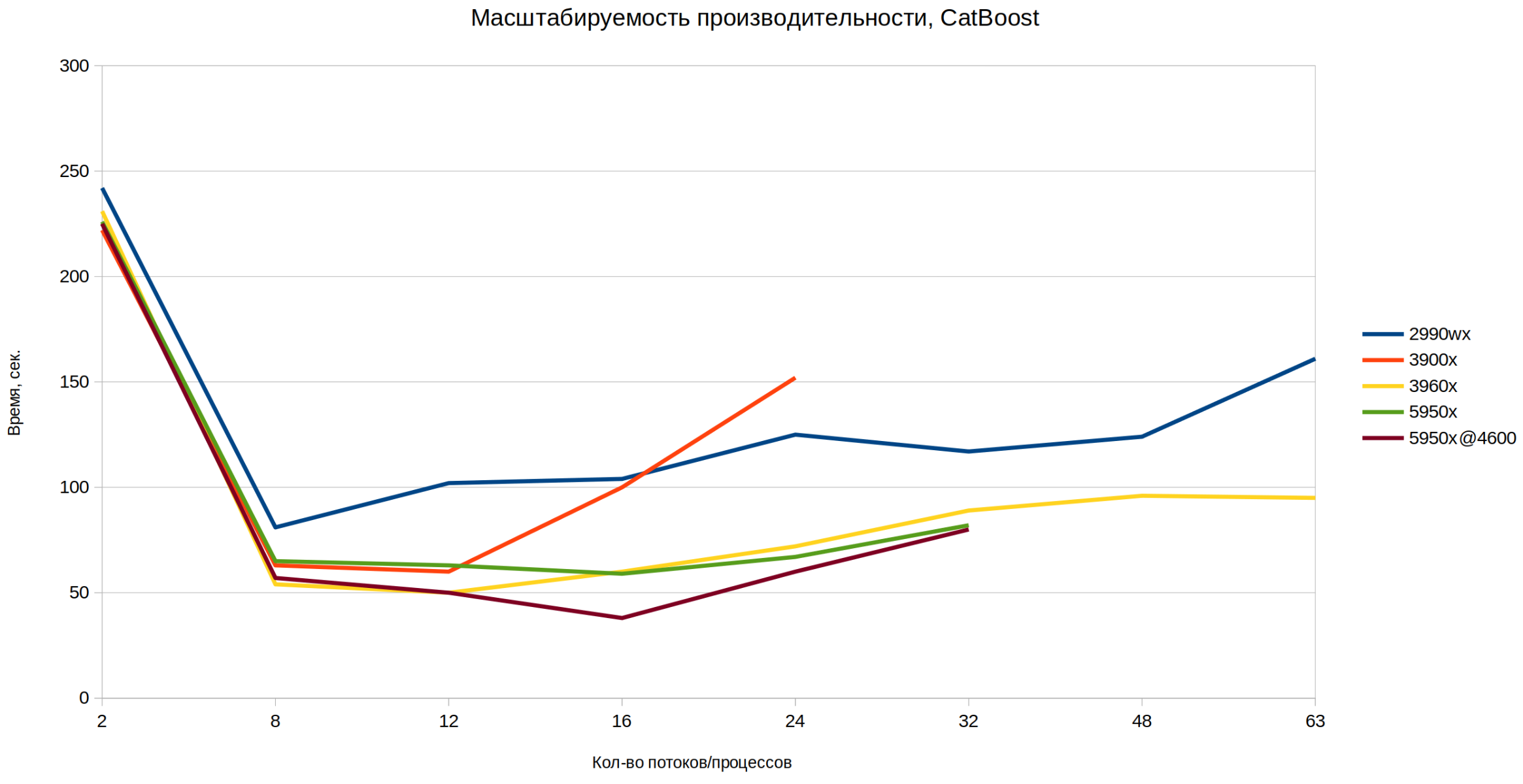
Выводы
Могу сказать следующее:
- Если вы хотите купить Threadripper или даже просто 16-ядерник для того, чтобы разогнать ваш код в Python, R, или даже C++ по обработке табличных данных через Pandas и подобное (а вы это делаете очень много, я уверен) - то не спешите тратить деньги, вполне возможно хватит максимум, 12-ядерника. А то и 8-ядерника. Лучше купите память побыстрее.
- Zen 3 некоторым образом имеет лучшие показатели не только в абсолютной производительности, но и в масштабируемости. Вообще ощущение, что 5950х - почти идеальный процессор с точки зрения производительности и универсальности.
- Разумеется, анализ данных не ограничен (не у всех) реляционными преобразованиями табличных данных. И если у вас хитрые задачи, например, на графах, или обработка пространственных данных - то тут уже выбирайте столько ядер, сколько даст реальную пользу, хоть 64.
реклама
Лента материалов
Соблюдение Правил конференции строго обязательно!
Флуд, флейм и оффтоп преследуются по всей строгости закона!
Комментарии, содержащие оскорбления, нецензурные выражения (в т.ч. замаскированный мат), экстремистские высказывания, рекламу и спам, удаляются независимо от содержимого, а к их авторам могут применяться меры вплоть до запрета написания комментариев и, в случае написания комментария через социальные сети, жалобы в администрацию данной сети.

Комментарии Правила